Facebookの公式apiを使って、ユーザーのメールアドレスを取得する方法
はじめまして。GMOモバイルのD.Nです。 今回は、facebookでユーザーのメールアドレスを公式apiを使い取得する方法をご紹介します。 今回は、facebook公式apiをphp(cakephp)で使う前提で説明さ...
はじめまして。GMOモバイルのD.Nです。 今回は、facebookでユーザーのメールアドレスを公式apiを使い取得する方法をご紹介します。 今回は、facebook公式apiをphp(cakephp)で使う前提で説明さ...
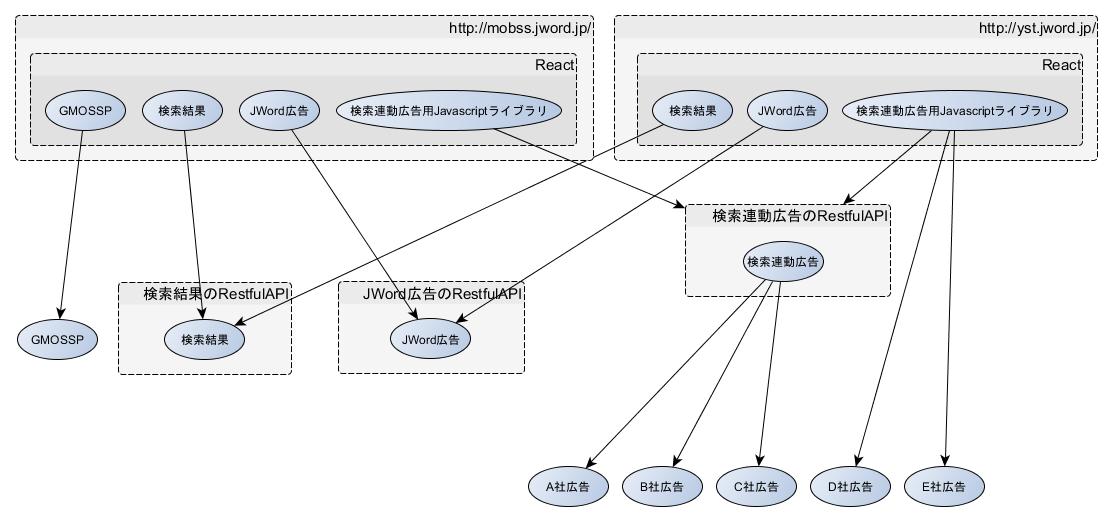
JWordのT.Oです。 去年あたりから話題になっているマイクロサービスですが、個人的にとても共感できる内容だったので今JWordで使っているサービスをマイクロサービス化するとどのような構成になるか構成図を書いてみました...
はじめまして。JWord holyです。 今回は、PHP7.0.0について話したいと思います。 12/3(木)、PHPはバージョン7.0.0をリリースしました。 PHP7.0.0のリリース内容を一部抜粋すると、 ・「PH...
こんにちは。GMO MOBILEデザイナーのH.Sです。 日々大量の画像を捌きつつ、センスを養うために常に情報のインプットも必要なデザイナーにとって最も大切なのは、いかに手数を少なく効率的に画像を作るかということだと思い...
JWordのO.Yです。 ビッグデータがムーブメントとなって久しく、用途はなんであれ今はHadoopを導入している企業さんも多いことかと思います。 JWordでもHadoopを導入しており検索クエリーの集計等に使用...
(画像は Impala の Web サイト より転載) GMOインターネット 次世代システム研究室 兼 GMOアドパートナーズ グループCTO室のM. Y.(自称DevOps担当)です。今回は、普段の業務で気付いた Im...
GMOモバイルのT.Oです。 管理画面などで売上などのデータをグラフ表示したいという要望は多いのではないでしょうか? そこでこの記事では以下のような棒グラフの実装手順をお伝えします。 グラフ描画にはJavaScriptラ...
こんにちは。GMO NIKKOのY.Sです。 先月、Apache Drill 1.2がリリースされました。 Apache DrillはスキーマフリーのSQLエンジンで、HDFS, HBase, MongoDB, Ama...
少し前の話になりますが、9月にGMO アドパートナーズグループ(以下APG)のエンジニアが一堂に会して、「第2回APG Engineer Night」が開催されました。 グループ各社に分散しているエンジニアのコミュニケー...
はじめまして。CTO室のT.N.です HashiConf2015で発表されたHashiCorpの新プロダクトOttoとNomad OttoについてはVagrantの後継ツール(というわけではないんですが)という触れ込みも...