![]()
こんにちは、CTO室のT.Nです。レコメンドウィジェット「TAXEL by GMO」の開発に携わっています。
今回はTAXEL(タクセル)の裏側の話をちょこっとしたいと思います。
TAXELとは
TAXELとは閲覧ユーザーの興味関心・行動や、コンテンツ特性を解析し、機械学習エンジンにより関連する記事をレコメンド表示するサービスです。
タグを設置するだけでコンテンツを解析し、記事をレコメンド・表示できるものとなっています。
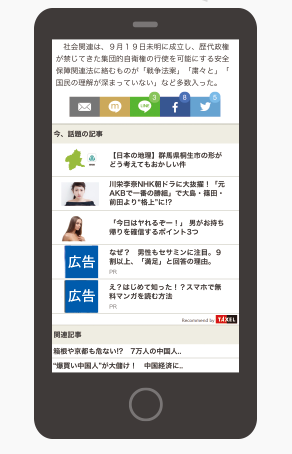
TAXELでのレコメンドの仕組み
TAXELは「ハイブリッドレコメンド」により、レコメンド記事を選定しています。
ここでいう「ハイブリッドレコメンド」とはメディアの特性や記事の状態等によって複数のレコメンド手法を組み合わせ、効果的なレコメンド記事を表示できる機能を指しています。
これはどういった時に有効なのでしょうか?
例として商品をレコメンドする仕組みを考えてみましょう。
商品レコメンドの際によく使われる手法として、「同じ商品を買ったユーザを類似ユーザとみなし、類似ユーザが買った別の商品をレコメンドする」といったものがあります。
一番有名なものだとAmazonのおすすめ商品がありますね。
しかしこの手法だと購入者が少ない商品がレコメンドされない現象、つまり「コールドスタート問題」が生じます。
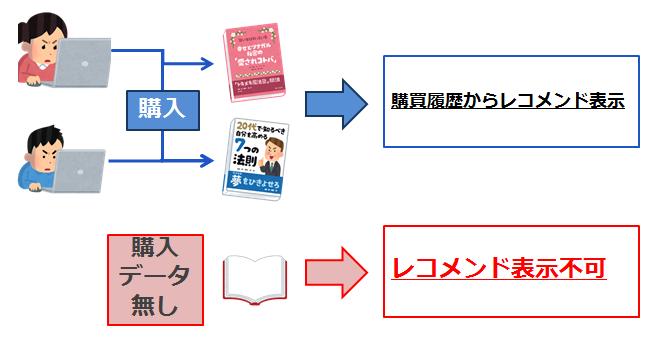
ではコールドスタート問題を回避するにはどうすればいいでしょう?
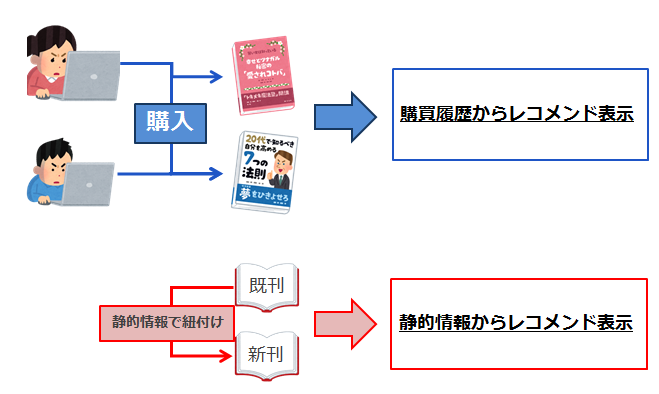
一つ考えられるのは商品名や内容等の静的情報で類似のものを推薦すればよいという考えがあります。
書籍で考えるとあるシリーズの小説をずっと購読している人に対して、そのシリーズの最新刊を推薦するというものです。
このような手法であればたとえその商品の購入者が少なくても有効なレコメンドができそうですね。
TAXELでは、このように異なる複数のレコメンド手法を組み合わせ記事の推薦を実施しています。
複数を組み合わせることによってそれぞれのレコメンド手法の弱点を補い、効果を最大化しようとしているわけです。
レコメンド手法紹介
さてこれまではTAXELのサービスの紹介でしたが、ここからはこのようなレコメンドで使える手法のいくつかをサンプルコードを交え紹介します。
例として、上に挙げた「類似ユーザ行動情報を利用したレコメンド」「類似名を利用したレコメンド」を題材にしようかと思います。
※なお以下のコードは全てApache Sparkを利用したものとなっています
レコメンド手法1: 類似ユーザ行動情報を利用したレコメンド
行動情報をもとにしたレコメンド手法は数多く存在します。
有名なものとしてはアソシエーション・ルールという手法があります。
代表的なアルゴリズムとして1994年に提唱されたAprioriアルゴリズムがあります。
アソシエーション分析という形でも色々な場所で利用されており、聞いたことがあるという方もいらっしゃるかと思います。
またこれより新しいものとして協調フィルタリングという手法も存在します。
Apache Sparkでは、このうちALS(ALS-WR)というアルゴリズムが実装されています。
これはNetflix Prizeで利用された手法で、Large-scale Parallel Collaborative Filtering for
the Netflix Prize(2008)という論文にて提唱されました。
特徴としては従来の協調フィルタリング手法より、処理データ量を減らしたため高速化したところにあります。
ここではアソシエーション・ルールのサンプルコードを紹介します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD import org.apache.spark.mllib.fpm.AssociationRules import org.apache.spark.mllib.fpm.FPGrowth.FreqItemset object ArSample { def main(args: Array[String]): Unit = { val sc = new SparkContext("local[*]", "example") // 例なのでデータを増幅する // FreqItemset(データパターン, 頻度) val freqItemsets = sc.parallelize(Seq( new FreqItemset(Array("http://hogehoge/page1"), 20L), new FreqItemset(Array("http://hogehoge/page2"), 20L), new FreqItemset(Array("http://hogehoge/page3"), 20L), new FreqItemset(Array("http://hogehoge/page4"), 20L), new FreqItemset(Array("http://hogehoge/page5"), 20L), new FreqItemset(Array("http://hogehoge/page1", "http://hogehoge/page2"), 19L), new FreqItemset(Array("http://hogehoge/page4", "http://hogehoge/page5"), 18L) )); // アソシエーションルールのクラスを作成 // 確信度(confidence)を設定する val ar = new AssociationRules().setMinConfidence(0.6) val results = ar.run(freqItemsets) results.collect().foreach { rule => println("[" + rule.antecedent.mkString(",") + "=>" + rule.consequent.mkString(",") + "]," + rule.confidence) } } } |
レコメンド手法2: 類似名を利用したレコメンド
類似名を探すというのはコンピュータにとっては非常に難しい話です。
例えば「水」と「川」は似ているが、「飛行機」があまり似ていないというのは人間なら誰でも分かることです。
しかしコンピュータにとってこの3つの単語はただの0/1の羅列です。
そこから類似性を発見するのは非常に難しい問題となります。
このような問題に対する手法としてword2vec(word embedding)があります。
この手法を用いると単語はただの文字列から、数十次元から数百次元のベクトル(数値の配列)に変換されます。
ベクトル、つまり数値の配列になると何が嬉しいのでしょう?
その一つとしてベクトルになると類似性が距離で表現できるようになることが挙げられます。
つまりベクトル間の距離が近いものは類似単語となり、遠いものはあまり似ていない単語といったことが表現されます。
これをもっと具体的に考えてみましょう。
ここでは物事を単純にするために2次元のベクトルで表現して、考えたいと思います。
Word2Vecで変換すると、例えば水は(0,1)、川は(1,2)、飛行機は(10000,20000)といったベクトルに変わります。
「水」と「川」は近い数値を持ちますが、飛行機は離れた数字を持っていますね。
これが類似性がベクトルで表現できる、ということです。
またベクトルはただの数値であるため、加減算もクラスタリングもできるようになります。
(e.g. King + Woman = Queen)
加減算ができれば複数単語を持つ名称にも適用できるようになりますね。
ではコードを見てみましょう。
ここではWord2Vecで単語ベクトルを生成した上で「水」の類似単語を表示し、かつK-Meansを用いクラスタリング(グルーピング)した結果です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
import java.io.PrintWriter import org.apache.spark.SparkContext import org.apache.spark.mllib.clustering.KMeans import org.apache.spark.mllib.feature.Word2Vec import org.apache.spark.mllib.linalg._ import org.apache.spark.rdd.RDD object WordToVecCluster { def main(args: Array[String]): Unit = { // ローカル実行のため適当な名称で val sc = new SparkContext("local[*]", "example") // 事前にWikipedia等の大量テキストデータを分かち書きしておく // 分かち書きしたファイルを指定 val path = "input.txt"; val source: RDD[String] = sc.textFile(path); // 分かち書きが半角スペース区切りなので、これをWord2Vecが処理出来る形に変更 val input = source.map(content => content.split(" ").toSeq) // Word2Vecを用いて単語をベクトル化(100次元:デフォルト)する // 精度を上げるためイテレーション数を1(デフォルト)→3に変更している val model = new Word2Vec().setNumIterations(3).fit(input) // 水の類似単語を表示する model.findSynonyms("水", 5).foreach(println) // 単語単位 // Word2Vecでベクトル化したデータを、K-Meansで処理できるようにVector型に変換する val wordvec = model.getVectors.map(x => new DenseVector(x._2.map(elem => elem.toDouble)).asInstanceOf[Vector]).toSeq // K-Meansを用いてクラスタリング // クラスタ数 val k = 1000 // イテレーション数 val maxItreations = 10 // クラスタリング実行 val clusters = KMeans.train(sc.parallelize(wordvec) , k, maxItreations) // クラスタリング結果をファイルに出力 val file = new PrintWriter("out.txt") model.getVectors.foreach { tuple => println(tuple._1 + ": cluster => " + clusters.predict(Vectors.dense(tuple._2.map(_.toDouble)))) } file.close() } } |
まとめ
今回はTAXELでのレコメンド手法の一部を紹介させていただきました。
レコメンド手法やビッグデータに興味のある方、やってみたい!という思いをもった方、俺ならもっとうまく出来る!という方等などいらっしゃれば、こちらから是非ご応募ください!

