AWSのIPアドレスを判定する
こんにちは。GMOアドマーケティングadcloud開発チームのN.Sです。 サーバへのアクセスを分析する中で、アクセス元がクライアント端末かサーバかで処理を分けたいというニーズが発生しました。 まずは試しにIPアドレスが...
こんにちは。GMOアドマーケティングadcloud開発チームのN.Sです。 サーバへのアクセスを分析する中で、アクセス元がクライアント端末かサーバかで処理を分けたいというニーズが発生しました。 まずは試しにIPアドレスが...
こんにちは。GMOアドマーケティングのK.Mです。 最近よく聞くPWAという概念があります。ざっくりいうと「アプリのようなWeb」ということで、プッシュ通知や、アプリのようにリッチなオフライン体験、バックグラウンド処理な...
皆さんこんにちは。 普段は顧客対応や開発のサポート業務を行っておりますGMOアドマーケティングのR.Aです。 11月3日にiPhoneXが発売され暫く経ちましたが、皆さん機種変更等はされましたでしょうか。 自分も現在iP...
こんにちは。GMO NIKKO エンジニアのN.Iです。 最近、機械学習を使って何かサービスを作れないか? みたいなかるーい感じの話があり、画像解析を触ってみることになりました。 調べてみると、各社WEB画面で画像をUP...
エンジニアの皆さん、日々お疲れ様です。 GMOアドマーケティングのA.Tです。 今日は技術的なことではなく、チケット管理システムを活用したタスクマネジメントについて書いてみようと思います。リーダー1年生が対象です。 進捗...
GMOアドマーケティングのT.Nです。 今年の9月にJava9が正式にリリースされました。 弊社ではまだJava8を使用していますが、 Java9へのアップグレードに備え、勉強しているところです。 Java9の変更点はい...
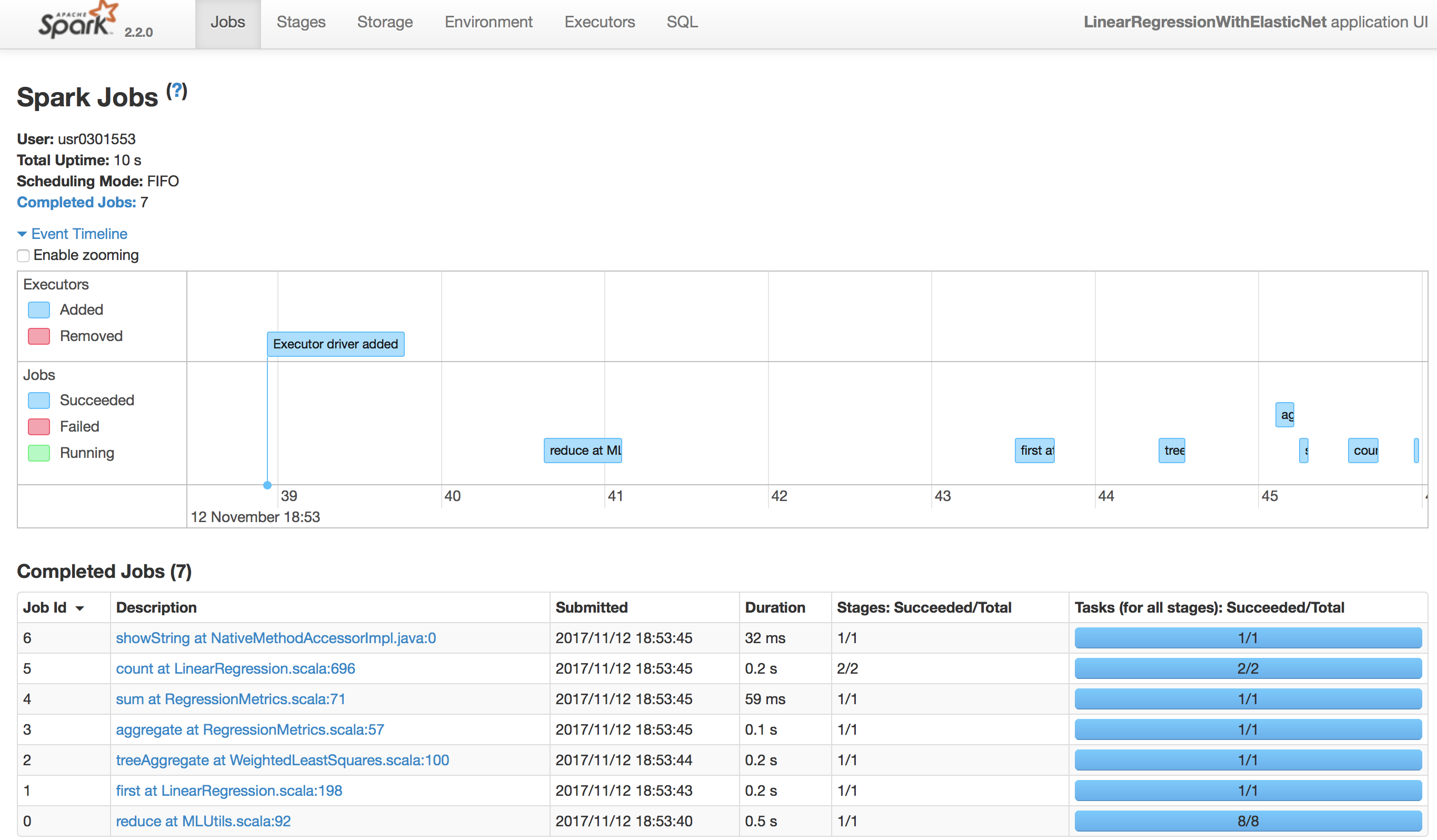
皆さん こんにちは、GMOアドマーケティングのS.Rです。 SparkのProgramを開発する上で、Performanceの改良やInstanceの設定のTuningはかなり重要です。 これらのチューニングはSpark...
GMOアドマーケティングのSSP開発チームのT.Kです。 コードレビューで処理を追いかける際にPhpStormを良く使いますが ビューからコントローラへのジャンプが出来ず、不便に感じていました。 既存のプラグインで対応で...
GMOアドマーケティングに中途入社してまもないy.yです。 11/5(日)のGo Conferenceの内容についてまとめようと思っていたのですが 補欠からくり上がれなかったので今回はGo言語を使って Google Cl...
こんにちは、GMOソリューションパートナー媒体開発本部のN.Sです。 先日NGINX社より軽量アプリケーションサーバNGINX Unitのベータ版リリースがありました。 各言語毎のアプリケーションサーバ運用を一本化出来る...