コードレビューを怖がっていた新卒エンジニアが始めた対策
この記事の概要 新卒エンジニアのY.Oの自己紹介 入社後苦労した事 コードレビューとは何か コードレビューの回数を減らすために行っている対策。 ご挨拶 こんにちは! TAXELチームに配属された新卒エンジニアのY.Oです...
この記事の概要 新卒エンジニアのY.Oの自己紹介 入社後苦労した事 コードレビューとは何か コードレビューの回数を減らすために行っている対策。 ご挨拶 こんにちは! TAXELチームに配属された新卒エンジニアのY.Oです...
お久しぶりですNKのS.Tです。ちょうど1年ぶりの投稿となります(その間に社名が2回変わったのは秘密) 前回は三角形の描画まででしたので今回はテクスチャーを追加してみます。 ■環境 OS: Windows 10 IDE:...
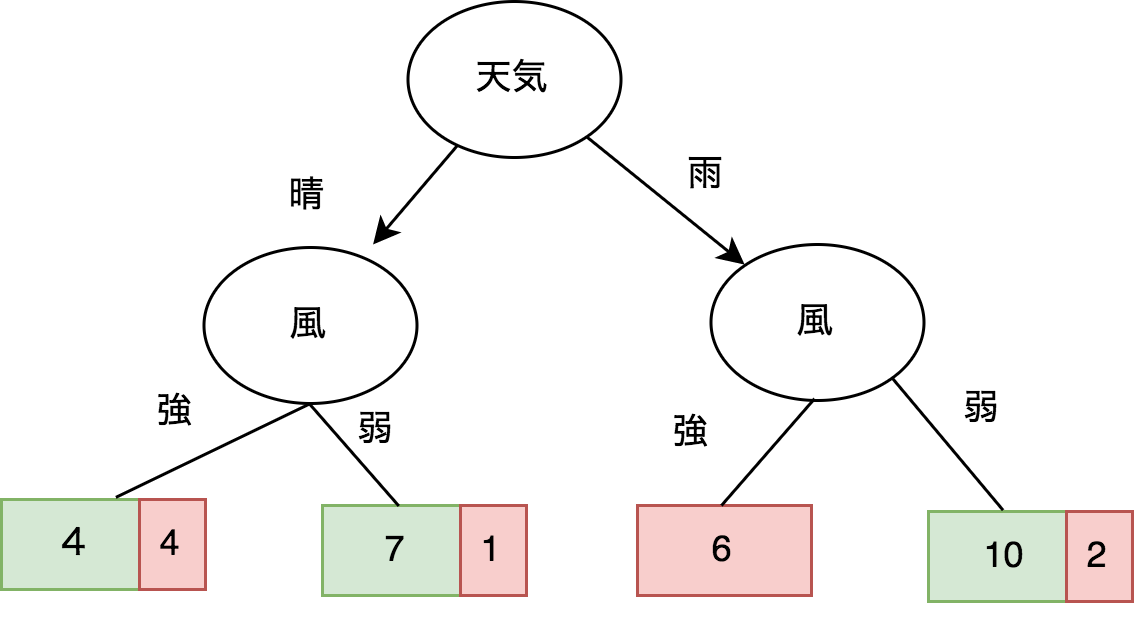
皆さん こんにちは、GMOアドマーケティングのS.Rです。 今回はよく使われる機械学習のアルゴリズムRodomForestを皆さんへ紹介致します。 この記事を理解するには、中学レベルの数学とPythonの基本知識が必要で...