PhpStorm(Intellij IDEA)のプラグイン作ってみる
GMOアドマーケティングのSSP開発チームのT.Kです。 コードレビューで処理を追いかける際にPhpStormを良く使いますが ビューからコントローラへのジャンプが出来ず、不便に感じていました。 既存のプラグインで対応で...
GMOアドマーケティングのSSP開発チームのT.Kです。 コードレビューで処理を追いかける際にPhpStormを良く使いますが ビューからコントローラへのジャンプが出来ず、不便に感じていました。 既存のプラグインで対応で...
GMOアドマーケティングに中途入社してまもないy.yです。 11/5(日)のGo Conferenceの内容についてまとめようと思っていたのですが 補欠からくり上がれなかったので今回はGo言語を使って Google Cl...
こんにちは、GMOソリューションパートナー媒体開発本部のN.Sです。 先日NGINX社より軽量アプリケーションサーバNGINX Unitのベータ版リリースがありました。 各言語毎のアプリケーションサーバ運用を一本化出来る...
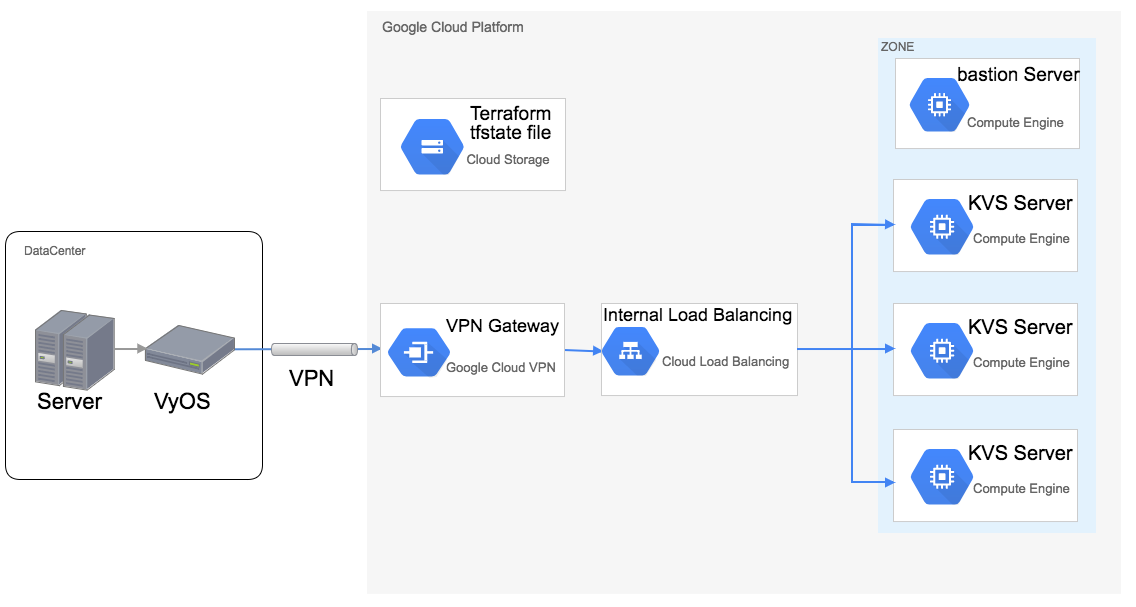
はじめまして。GMOアドマーケティングでインフラを担当しているa.sです。 今回はTerraformを用いて、GCP上に検証環境を構築する機会がありましたので、構築に伴う一連の作業をご紹介します。 構築内容 既存のオンプ...
2017年7月からGMOアドマーケティングのSSP開発チームにJoinしたKA.Mです。 先日、試用期間も無事終え落ち着きました。 GMOアドパートナーズグループには、住宅補助手当という オフィスビル近隣に住んでいる人が...
こんにちは。 GMOアドマーケティング、機械学習入門者のT.Mです。 はじめに ゼロから作るDeep Learningを読み終え、 実際に何か作るにあたって何をしたらよいか調べていたところ ニューラルネットワークのライブ...
GMOアドマーケティングのKMです。気が付けば、IT業界20年です(笑) エンジニアの人は自分の得意分野って把握している?キャリアプランは? エンジニアを目指す人や理解したい人も参考になればと思い職種について書きます。 ...