
こんにちは、GMOアドマーケティングのS.Sです。
機械学習の予測モデルを作成するときに、データをもとにしてモデルのハイパーパラメータを調整できると便利です。
例えばRandom Forestのモデルを学習する場合だと、木の深さはデータセットのサイズなどに応じて適切な値を設定する必要があります。
この値を何度か変更しつつ結果を確認するのは大変です。また同一のtrain set/validation set分割のもとで候補の中から選んだハイパーパラメータがよいかどうかを調べると、validation setにoverfitしてしまうという問題もあります。
このような問題を解決するために交差検証(https://ja.wikipedia.org/wiki/%E4%BA%A4%E5%B7%AE%E6%A4%9C%E8%A8%BC)では、次のような手順で性能を測定します。
- データをランダムにシャッフルする。訓練データのラベルごとなど規則的に並んでいるケースではこのステップを省略すると、foldごとにラベルに偏りが出てしまいます。
- データを同じ大きさの複数のグループに分割する。
- validation setとして使う部分を入れ替えながら評価指標を計算する。
- ステップ3で得られた評価指標を平均をとるなどして集約して、交差検証で得られる指標とします。
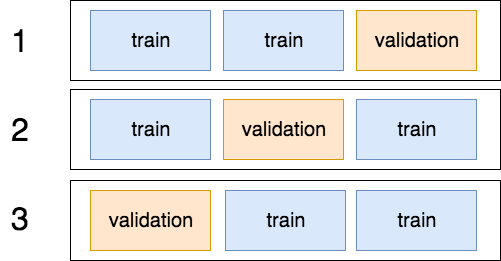
下に3-fold CVの図を示しました。
得られた指標をもとにハイパーパラメータを調整できます。
他にも一定期間で集計したデータをもとにモデルを学習するようなケースでは、データセットの傾向が変化することもあり、最初によいと思って設定したハイパーパラメータが時間とともにベストではなくなるということも考えられます。
そのようなケースでもハイパーパラメータも含めて調整することで対処できる場合があります。
今回はApache Sparkでモデルをfitするときに、ハイパーパラメータをCross Validationによって設定する方法をRandom Forestの例を示しつつ紹介します。
RandomForestの木の深さ(maxDepth)と木のノード分割のためのしきい値(minInstancesPerNode)を調整してみます。
SparkでCross Validationを行うには、Cross Validatorクラスを使います。(https://spark.apache.org/docs/latest/api/python/pyspark.ml.html#pyspark.ml.tuning.CrossValidator)
ParamGridBuilder(https://spark.apache.org/docs/latest/api/python/pyspark.ml.html#pyspark.ml.tuning.ParamGridBuilder)に各パラメータの選択肢を指定して、Parameter GridをつくってCrossValidatorに渡すとCross Validationを行なってもっともよかったパラメータの組み合わせのもとでのモデルが取得できます。(ここでは5-foldとしました。)
モデルのよさはevaluatorで定義しますが、最初のサンプルコードではBinaryClassificationEvalutor(https://spark.apache.org/docs/2.3.0/api/python/pyspark.ml.html#pyspark.ml.evaluation.BinaryClassificationEvaluator)を使って、2値分類の評価指標であるaurocをもとにモデルを作成して、もっともよいものを選びます。(AUROCについてはhttp://kamiyacho.org/ebm/ce205.htmlを参照してください。)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pyspark.ml.evaluation import BinaryClassificationEvaluator, Evaluator from pyspark.ml.tuning import CrossValidator, ParamGridBuilder from pyspark.ml.classification import RandomForestClassifier rf = RandomForestClassifier(labelCol=label_col, featuresCol=features_col) param_grid = ParamGridBuilder() \ .addGrid(rf.minInstancesPerNode, [100, 200]) \ .addGrid(rf.maxDepth, [8, 16, 24]) \ .build() evaluator = BinaryClassificationEvaluator().setLabelCol(label_col) cv_model = CrossValidator(estimator=rf, estimatorParamMaps=param_grid, evaluator=evaluator, numFolds=5) best_model = cv_model.fit(train_data).bestModel |
Evaluator自体を定義することでモデルの予測値を変換して評価したり、異なる評価指標を使うこともできます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class CustomEvaluator(Evaluator): def __init__(self, labelCol): super(Evaluator, self).__init__() self.labelCol = labelCol def _evaluate(self, dataset): df = some_transform(dataset) evaluator = BinaryClassificationEvaluator().setLabelCol(self.labelCol).setRawPredictionCol("colName") return evaluator.evaluate(df) def isLargerBetter(self): return True |
まとめ
Sparkのモデルに含まれるハイパーパラメータを交差検証で選ぶ方法について、RandomForestの例とともに紹介しました。


