GMO NIKKOのS.Tです。
社内システムをクラウド化(移行中)する機会があったので共有します。
長いので今回はその第ー回目として下記を説明します。
・Compute Engine
・Cloud Storage
・Big Query
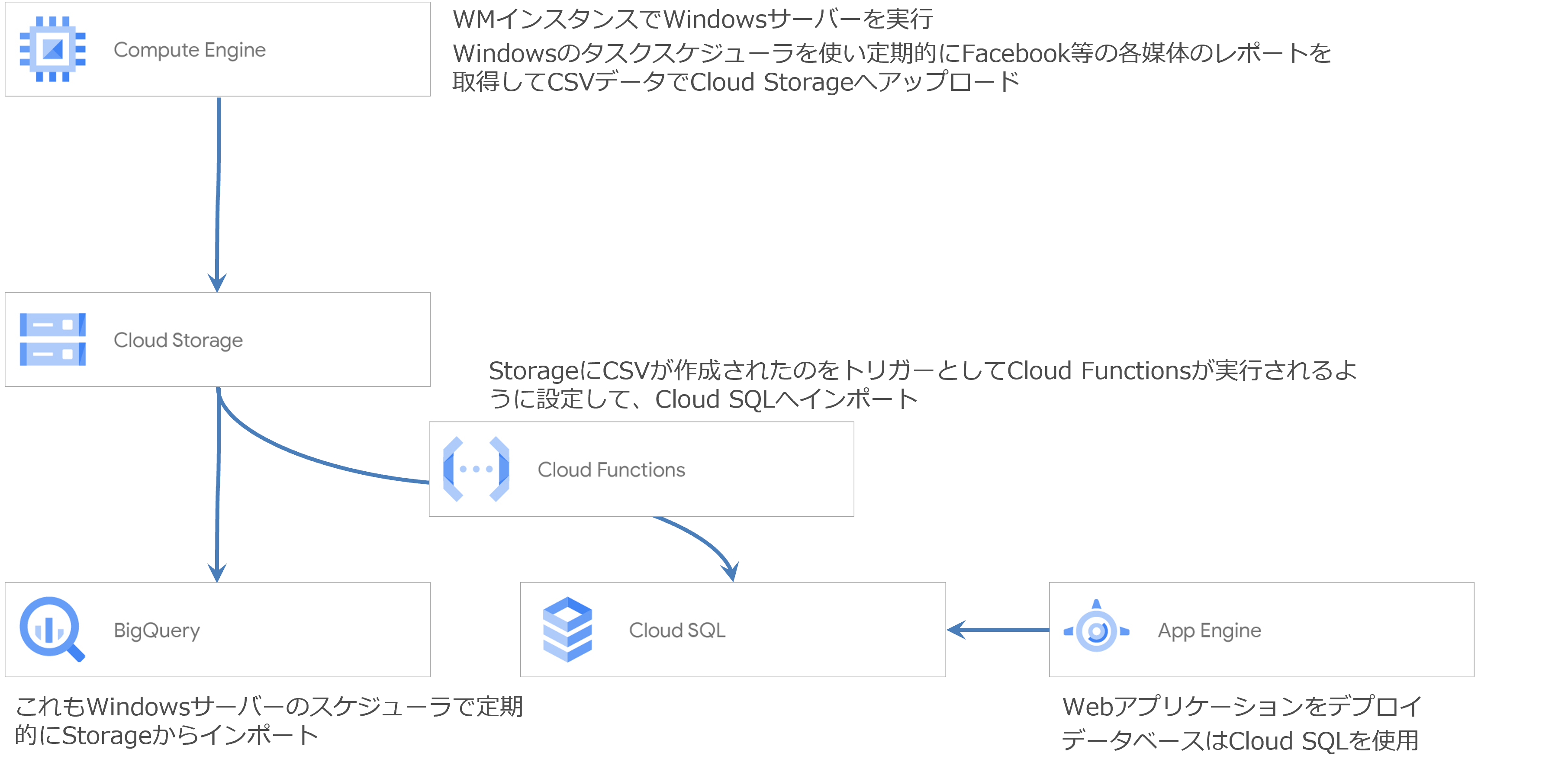
全体図
現在オンプレで稼働中のシステムからなるべく変更点を少なくして工数を抑えつつ費用もあまりかからない方法になっていると思います。
Compute Engine
■Windowsサーバーでレポートやマスター取得等のバッチを実行
最大の変更点はデータベースがOracleからCloud SQL(PostgeSQL)に変更になったことですね。
クラウドでWindowsを動かすので他の設定は比較的そのまま使えます。
以前はキュー管理にRabbitMQを使用していましたが、タスクスケジューラで定期的に非同期実行を行いCloud SQLにキュー用のテーブルを用意することで対応しました。
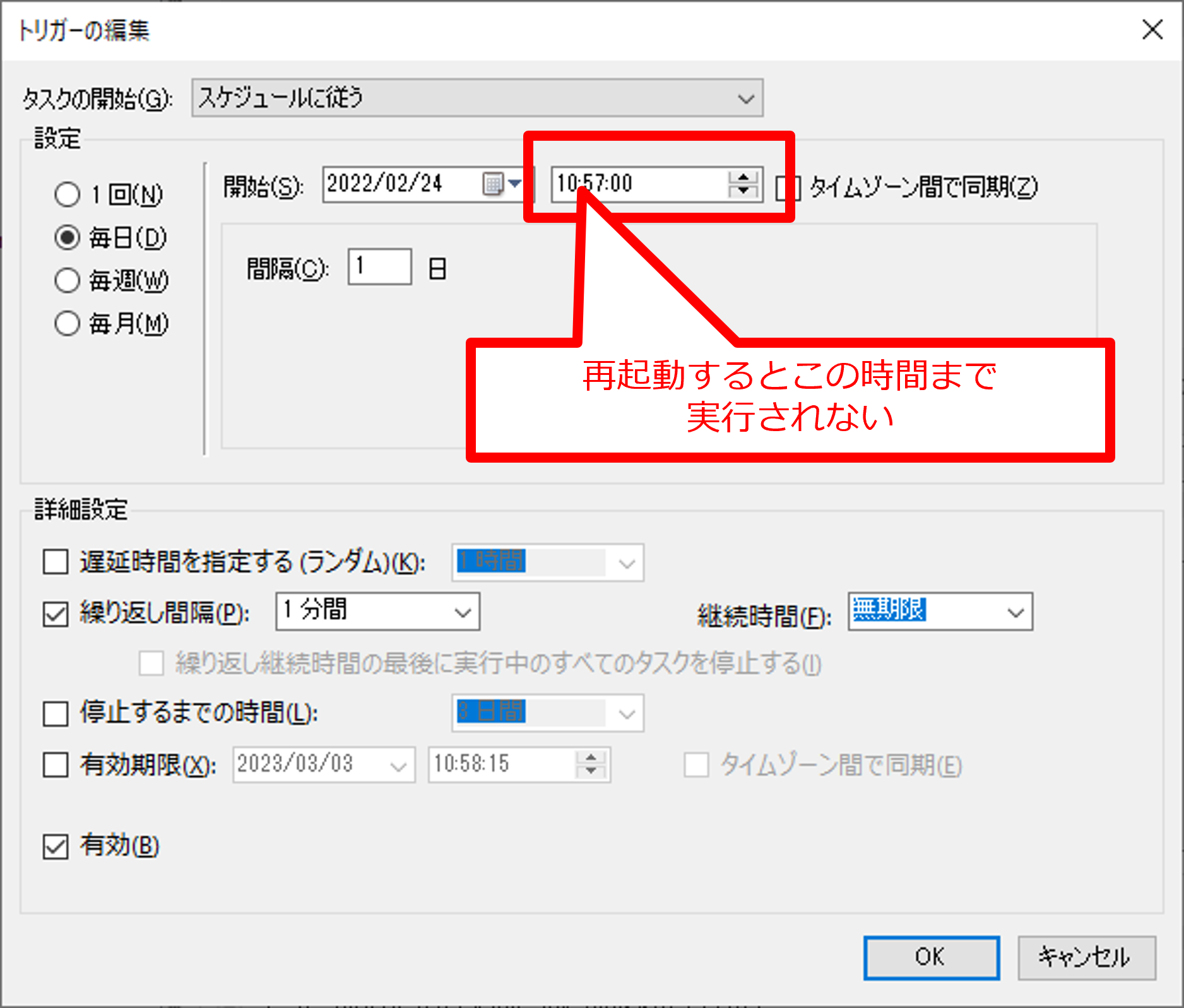
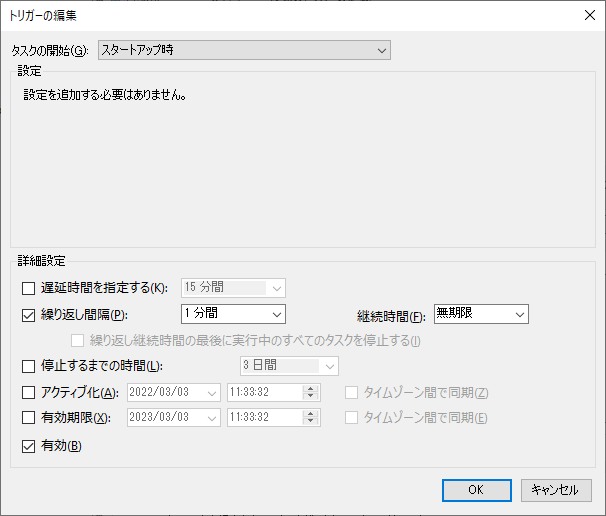
毎分実行するように下記のように設定しましたが、Windows Update等でOSを再起動すると指定時間まで実行されない仕様(タイミングによっては翌日まで動かない)なのでスタートアップ時も実行するようにトリガーを追加して対応しました。
取得してレポートデータは扱いやすいCloud Storageに保存します。
Cloud Storage
■Cloud Storageへアップロード
下記はバッチの内容ですが、PHPでレポートデータをCSV形式で保存してGZIP圧縮してアップロードしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
foreach (glob($csvDir . $reportName . '/*.csv') as $file) { // csvをgzip圧縮 $data = join("", file($file)); $gzdata = gzencode($data, 9); try { $fp = fopen(str_replace('.csv', '.csv.gz', $file), 'w'); if (fwrite($fp, $gzdata)) { unlink($file); } } catch (Exception $e) { throw $e; } finally { fclose($fp); } // アップロード $file = str_replace('.csv', '.csv.gz', $file); $uploadPath = 'daily/' . preg_replace('/\.\/csv\/(\d{8}_\d{6})\/(.+?)\/((\d{6}).+?)$/', '$4/$2/' . $version . '/$3', $file); $object = $bucket->upload(fopen($file, 'r'), ['name' => $uploadPath]); print("\t[" . $uploadPath . "] アップロード成功\r\n"); } |
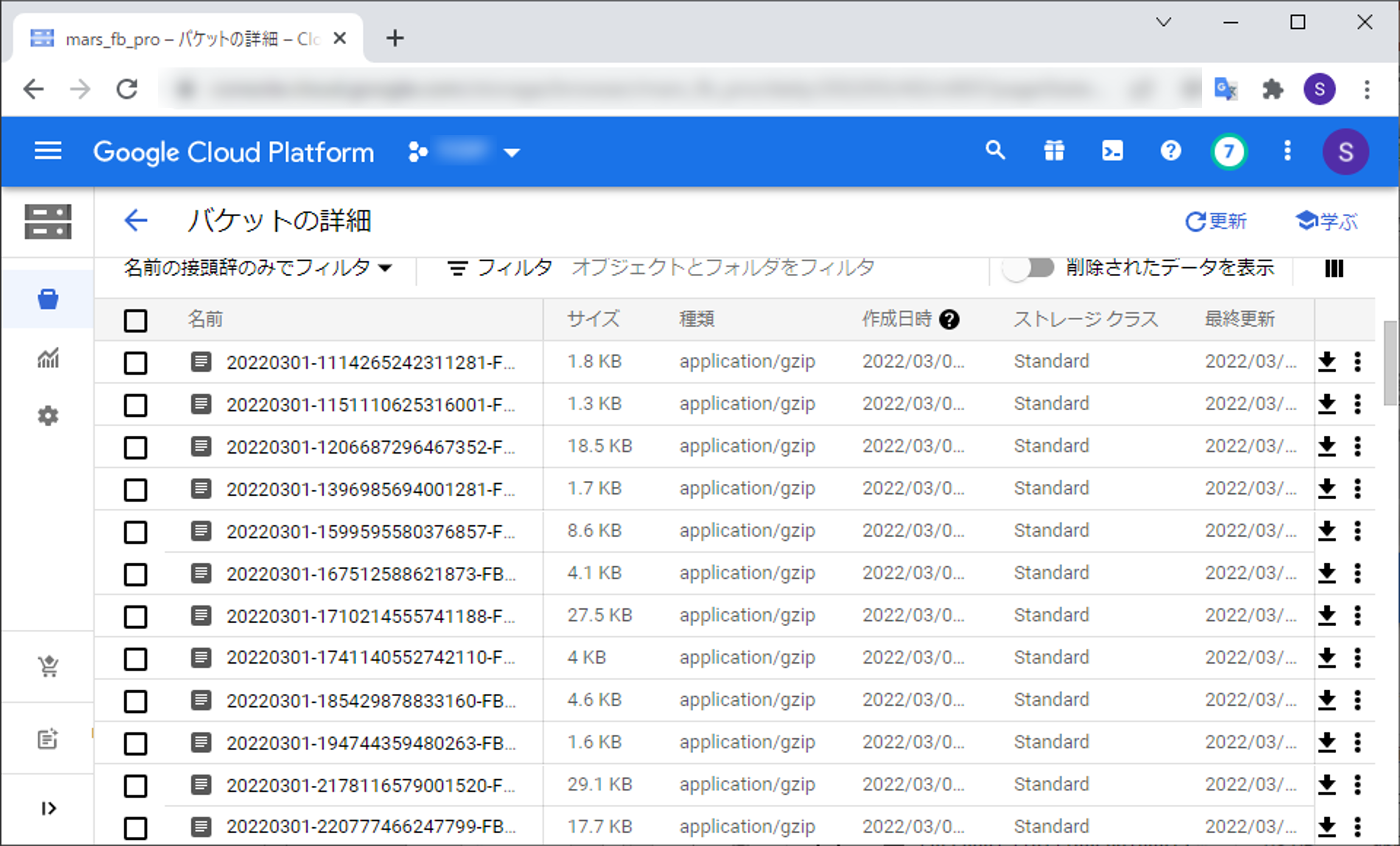
実行するとこのようにCloud Storageにアップロードされているのが確認できます。
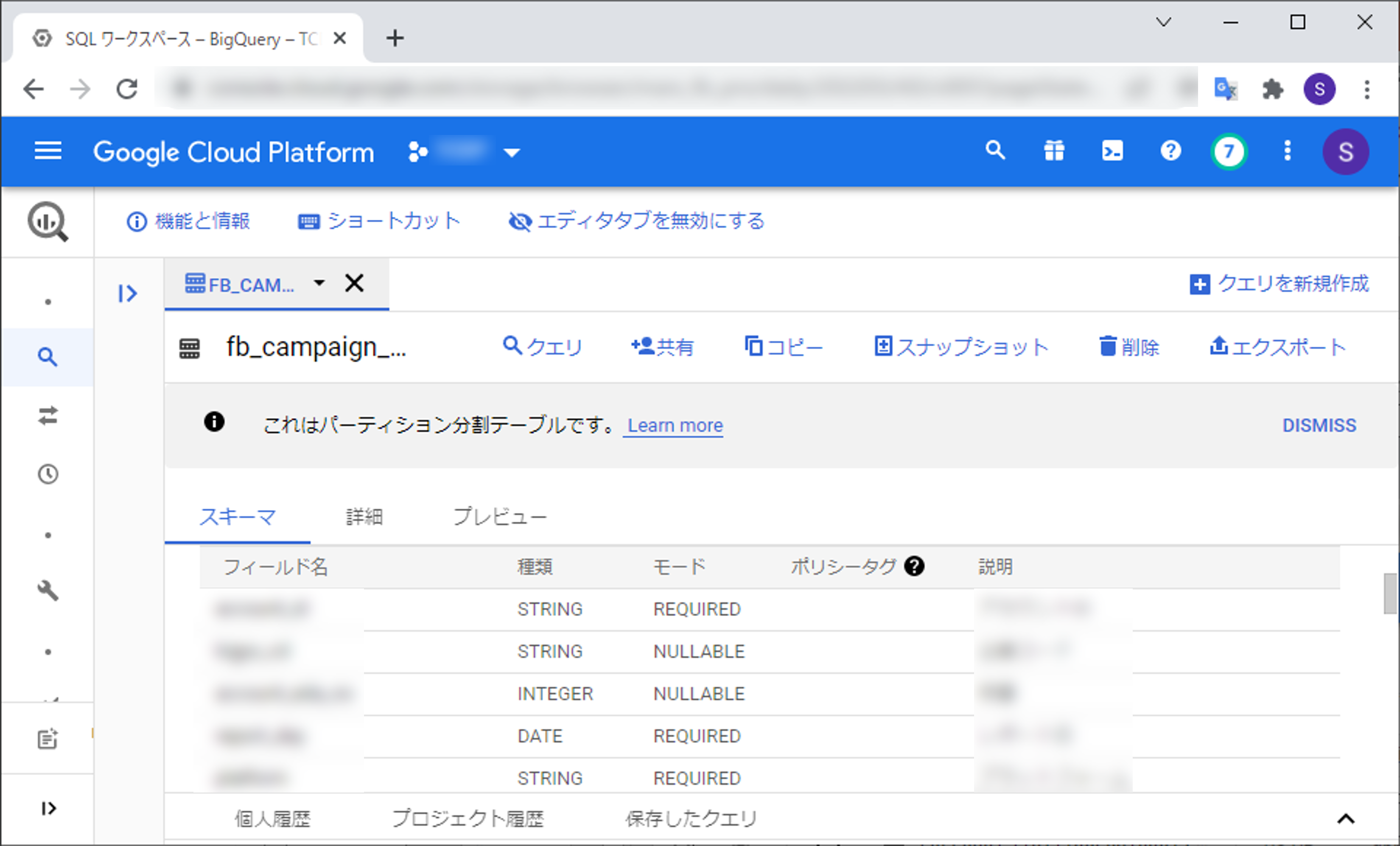
Big Query
Cloud StorageからBig QueryへのインポートもWindowサーバーのバッチから行っています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
foreach ($schema as $key => $value){ try { $yyyymm = str_replace('-', '', $i); // テーブルが存在しなかったら作成 if (!in_array($tableName, $tables)) { $table = $dataset->createTable($tableName, $value); } $table = $dataset->table($tableName); $gcsUri = 'gs://' . $bucketName . '/daily/' . $yyyymm . '/' . strtoupper($key) . '/' . $version . '*-XXXXX.csv.gz'; // 保存先は任意で $options = [ 'configuration' => [ 'load' => [ 'writeDisposition' => 'WRITE_TRUNCATE', // 上書き 'skipLeadingRows' => 1, // スキップするヘッダー行 'allowQuotedNewlines' => true // 引用符で囲まれた改行を許可する ] ] ]; $loadConfig = $table->loadFromStorage($gcsUri, $options)->schema($value['schema']); $job = $table->runJob($loadConfig); // ジョブが完了するまでポーリング $backoff = new ExponentialBackoff(10); $backoff->execute(function () use ($job) { $job->reload(); if (!$job->isComplete()) { throw new Exception('ジョブはまだ完了していません', 500); } }); if (isset($job->info()['status']['errorResult'])) { print(' ' . $job->info()['status']['errorResult']['message'] . "\r\n"); } else { print(" インポート成功\r\n"); } } catch (Exception $e) { print("\r\n"); putResult('Error:' . $e->getMessage()); } } |
Big Queryのテーブル設定も必要なので$schemaとして下記データを渡しています。
フィールド定義と日付でパーティショニングを行う場合の設定になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$schema['XXX'] = [ 'schema' => [ 'fields' => [ ['name' => 'xxxxx', 'type' => 'STRING', 'mode' => 'REQUIRED', 'description' => 'XXXXX'], ['name' => 'report_day', 'type' => 'DATE', 'mode' => 'REQUIRED', 'description' => 'レポート日'], ︙ ] ], 'timePartitioning' => [ 'type' => 'DAY', 'field' => 'report_day', ] ]; |
ID等の数字でパーティショニングを行う場合はこのように設定する必要がありました。
|
1 2 3 4 5 6 7 8 |
'rangePartitioning' => [ 'field' => 'id', 'range' => [ 'start' => '0', 'end' => '99999999999999999', 'interval' => '10000000000000' ] ] |
実行するとこのようにBig Queryにテーブルが作成されてCloud Storageのデータがインポートされているのが確認できます。