皆さん
こんにちは、GMOアドマーケティングのS.Rです。
SparkのProgramを開発する上で、Performanceの改良やInstanceの設定のTuningはかなり重要です。
これらのチューニングはSparkのWebUIを使えばかなり簡単に制御できます。
そこで、今回はSparkのWebUIを皆さんへ紹介致します。
※この記事を理解するには、Spark、Hadoop、Linuxのshellコマンドの基本知識が必要です。
1 Sparkとは?
Sparkの概要は以下のWikipediaの記事を参考にして下さい。
Apache Sparkはオープンソースのクラスタコンピューティングフレームワークである。カリフォルニア大学バークレー校のAMPLabで開発されたコードが、管理元のApacheソフトウェア財団に寄贈された。Sparkのインタフェースを使うと、暗黙のデータ並列性と耐故障性を備えたクラスタ全体をプログラミングできる(Apache Spark、2014年5月30日、ウィキペディア日本語版、https://ja.wikipedia.org/wiki/Apache_Spark)。
2 Sparkのインストール:
- Sparkの公式ダウンロードサイトで任意のバージョンをダウンロードします。
今回は例として最新のSpark2.2.0、Pre-bulit版をダウンロードしました。 - Sparkのモードを選びます。Sparkには3つの起動モードがあります。
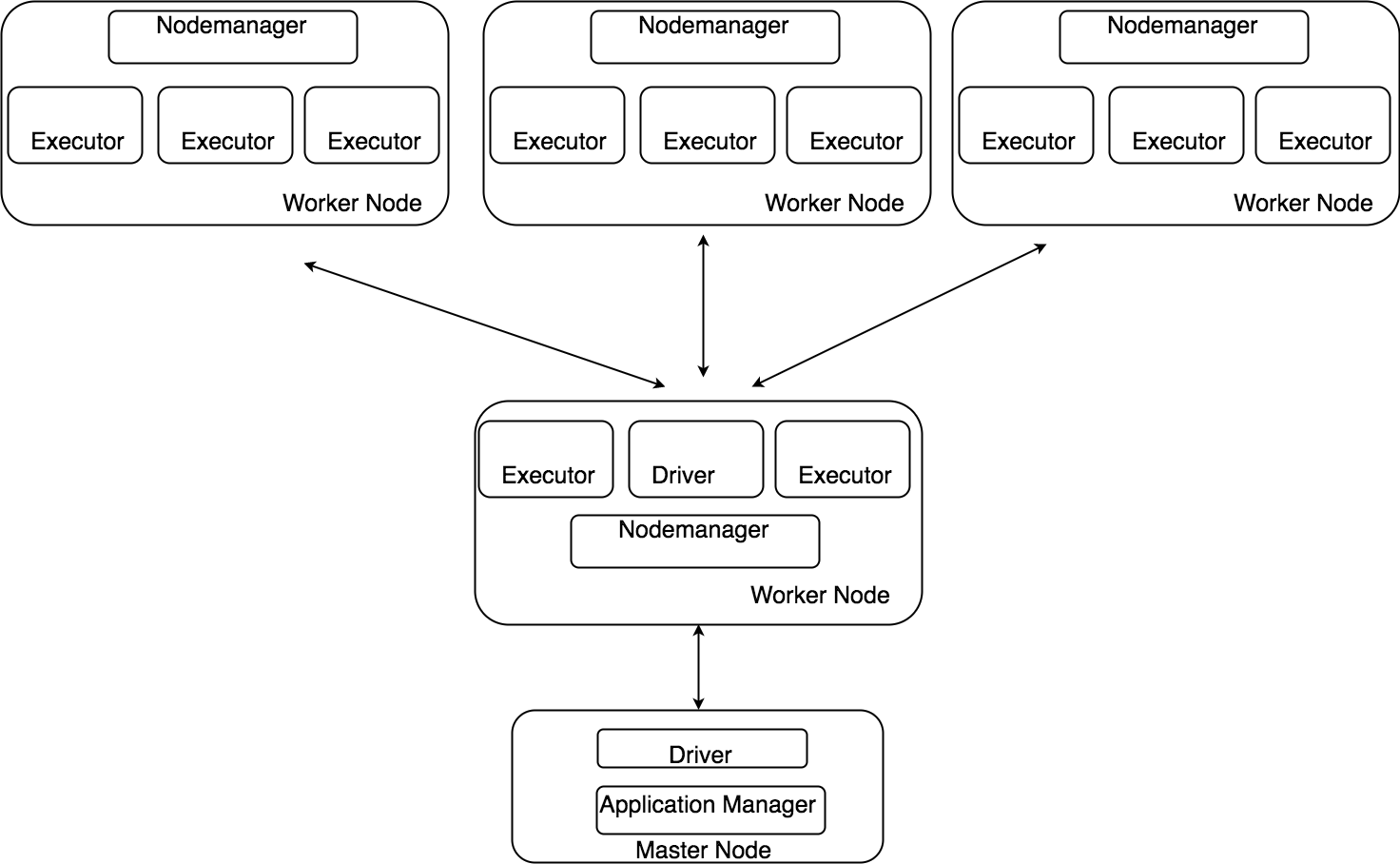
- WorkerNodeがない状態で起動します(Standalone Deploy Mode)。
今回は例としてこのモードで説明します。 - Yarnで起動します。YARN(Yet Another Resource Negotiator )は、Hadoopクラスタのリソース管理、ジョブスケジューリングを担当するモジュールです(YARN、2014年5月30日、ウィキペディア日本語版、https://ja.wikipedia.org/wiki/Apache_Hadoop#Yet_Another_Resource_Negotiator_.28YARN.29)。
- Mesosで起動します。Mesosはカリフォルニア大学バークレー校の研究機関AMPLabのプロジェクトによって開発されたクラスタのリソース管理のモジュールです(Mesos, 30 October 2017, Wikipedia, https://en.wikipedia.org/wiki/Apache_Mesos)。
- WorkerNodeがない状態で起動します(Standalone Deploy Mode)。
- SparkのShellを起動します。Sparkは四種類のShell(Scala, Java, Python, R )を実行できます。
今回は例としてScalaのShellを起動します。起動するコメントは下記です:
1./bin/spark-shell
SparkのShellを起動すると下記の画面を確認することが出来ます:

図1:Sparkの起動画面
3 WebUIへアクセス:
今回は二つモード(StandaloneとDataproc)でSparkのWebUIをアクセスする方法を紹介します。
- Standalone:
例としてStandaloneモードでSparkの公式サイトに記載されているLinearRegressionのSampleCodeを実行します。SampleCodeやデータはSpark公式のGithub(Source Code、Data)からDownloadしてください。今回はWebUIを確認しやすくするために、ソースコードの最後に下記の”halting”のコードを追加します。
123#Waiting for 400 secondsfrom time import sleepsleep(400)
操作の手順は以下の通りです:- Sparkをインストールします。
- LinearRegressionのSampleCodeをsubmitします。
1./bin/spark-submit examples/src/main/python/ml/linear_regression_with_elastic_net.py data/mllib/sample_linear_regression_data.txt - SampleCodeが動作しているときにBrowserへMaster NodeのIPやPortを入力してWebUIへアクセスします(Standaloneの場合はhttp://127.0.0.1:4040/jobs/を入力します)。
WebUIのアクセスに成功すると図2のような画面を確認することが出来ます。
WebUIの各部については第3章で詳しく説明します。
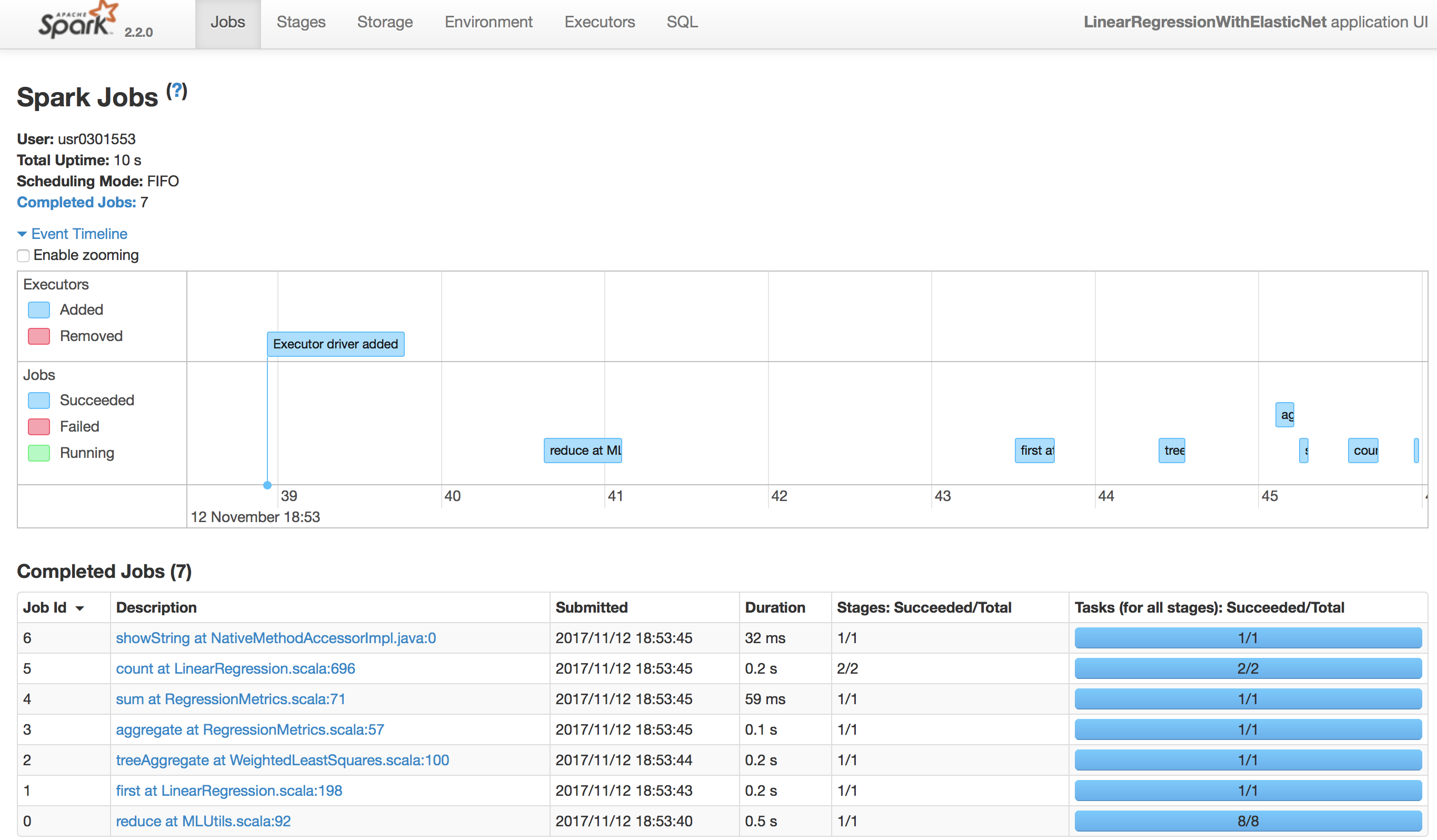
図2:StandaloneのWebUI
- Google Cloud Dataproc:
今回はGoogle社により提供されている Spark / Hadoop のマネージドサービスであるDataprocのWebUIにアクセスする方法を紹介します。- Google SDKを設定します。設定方法はGoogle Cloudの公式サイトを参考にしてください。
- DataprocのInstanceを立ち上げます。使うCommandは下記の通りです。
1gcloud dataproc clusters create test --zone=asia-northeast1-a - Step2で作ったDataprocのInstanceのMasterNodeと連携するSSH tunnelを作ります。
使うCommandは下記の通りです。
1gcloud compute ssh --zone=asia-northeast1-a test-m -- -D 1080 -N -n
Commandの詳細の説明はGoogle Cloudの公式サイトを参考にしてください。 - Sparkのapplicationをsubmitします。今回は例としてLinearRegressionのSampleCodeをsubmitします。使うCommandは下記の通りです。
12gcloud beta dataproc jobs submit pyspark --cluster test examples/src/main/python/ml/linear_regression_with_elastic_net.py--py-files data/mllib/sample_linear_regression_data.txt - Terminal(Mac, Linux)やCommand Line(Window)でChromeを起動します。
使うCommandは下記の通りです。
1234Google Chrome executable path \--proxy-server="socks5://localhost:1080" \--host-resolver-rules="MAP * 0.0.0.0 , EXCLUDE localhost" \--user-data-dir=/tmp/master-host-name
各OSでのChromeのDefault Pathは表1の通りです。表1:ChromeのDefault Path
Operating System Default Path of Google Chrome Mac OS X /Applications/Google\ Chrome.app/Contents/MacOS/Google\ ChromeLinux /usr/bin/google-chromeWindows C:\Program Files (x86)\Google\Chrome\Application\chrome.exe - 起動したChromeでhttp://[MasterNodeのInstance名]:8088へアクセスします。
アクセスすると、DataprocのWebUIを確認することができます(図3)。
DataprocのWebUIの項目「TrackingUI」から「History」をクリックすることで、図3の様なSparkのWebUIに遷移できます。
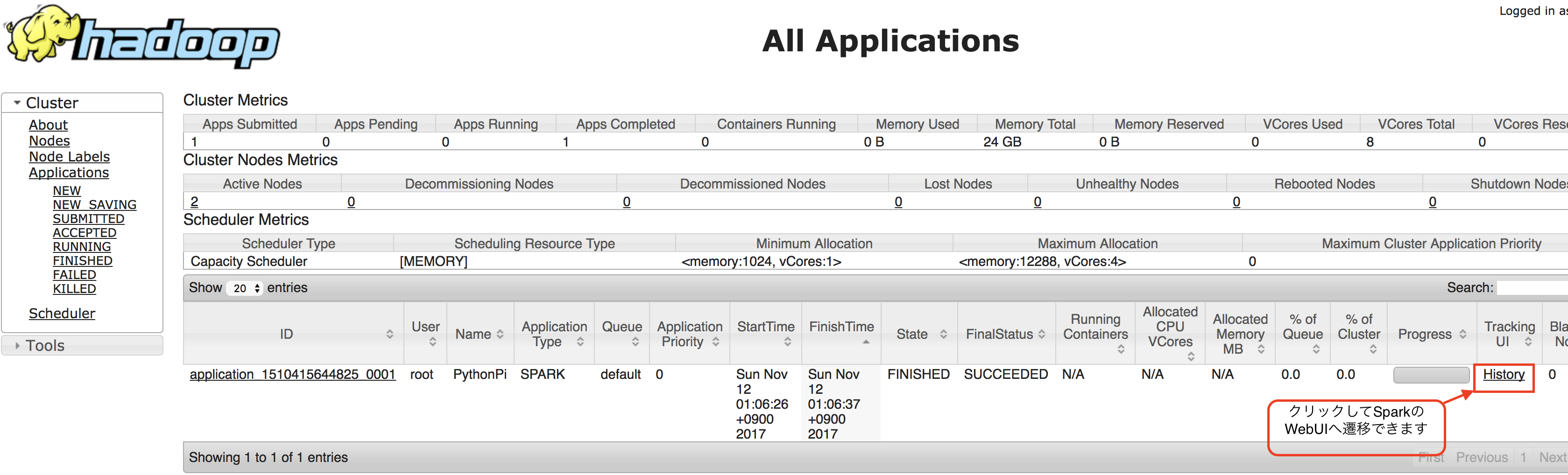
図3:DataprocのWebUI
4 WebUIの説明
SparkのWebUI には6つのTabがあります。
- Jobs:
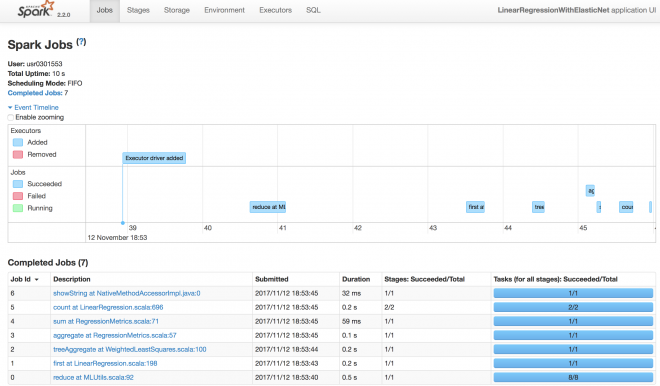
Tab JobでJobのListが確認できます(図4)。
JobのDescriptionをクリックすることでさらに詳細のJobを確認することができます。
今回は例としてJob 5(count at LinearRegression.scala:696)をクリックしてみます。
図4はJob 5の詳細画面です。
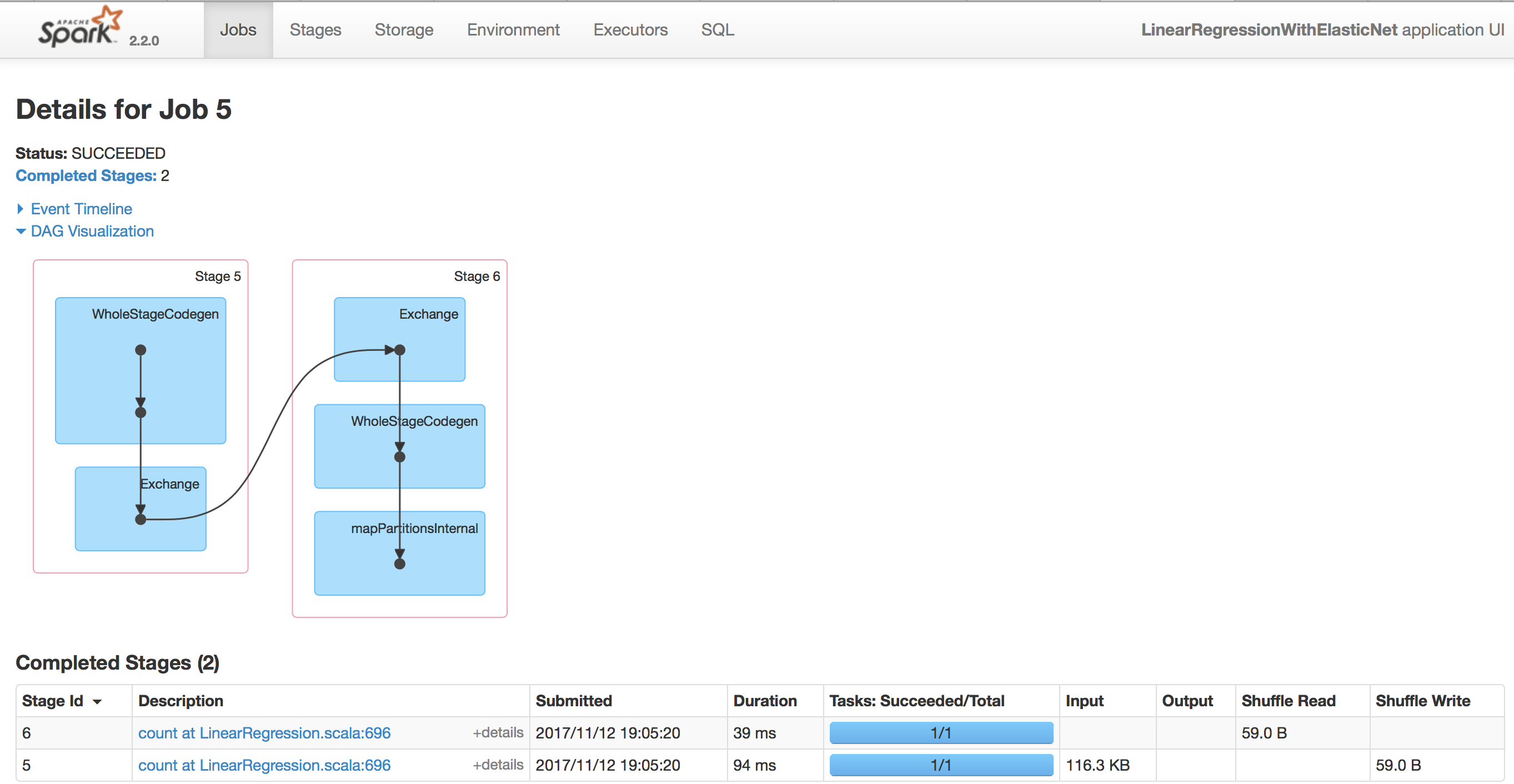
図4:Job の詳細
Jobの詳細画面にはstageが並んでいます。気になるstageのDescription項目をクリックするとさらに詳細な情報を確認することができます(図5)。
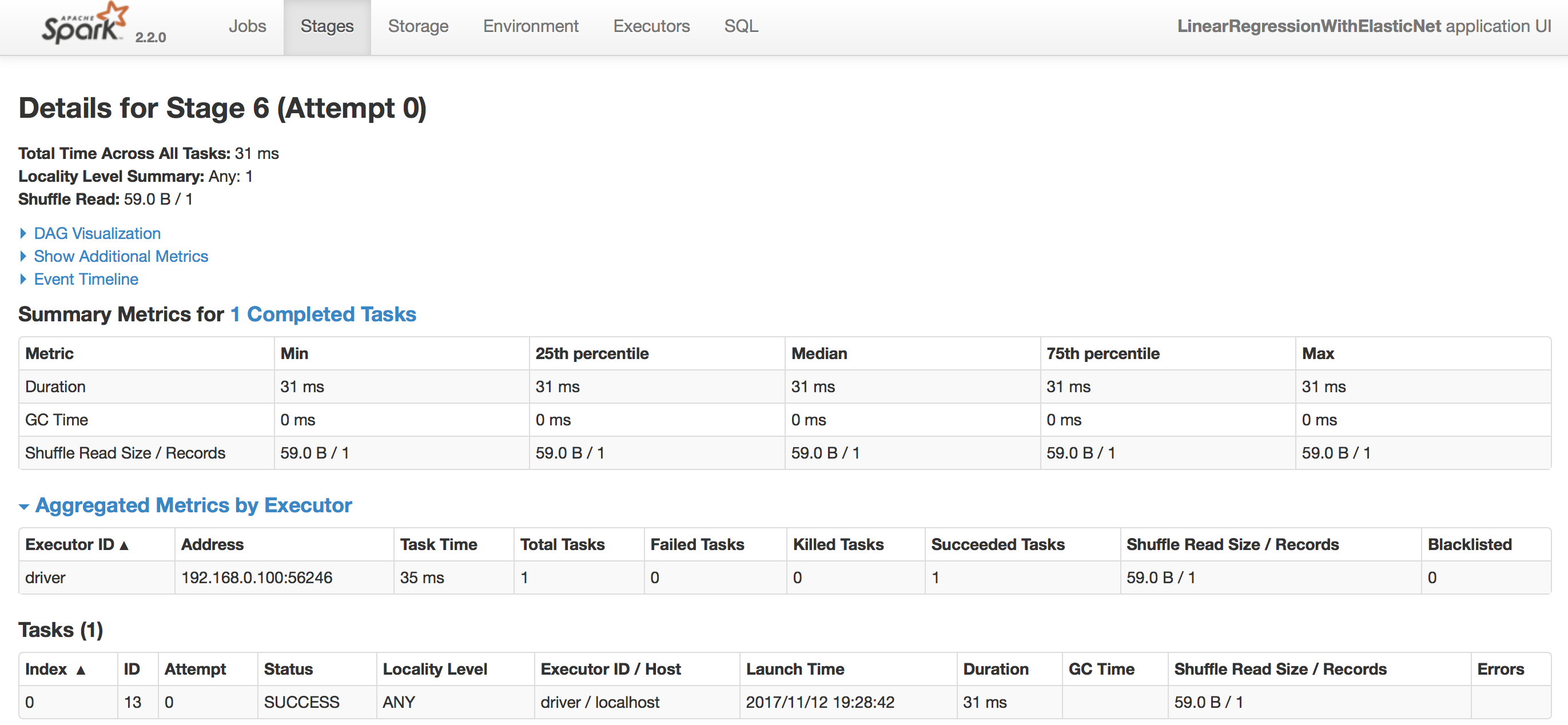
図5:Stage の詳細
- Stages
Tab Stagesで全てのStagesのListが確認できます。気になるStagesをクリックすることで、そのStageの詳細を確認することができます(図6)。
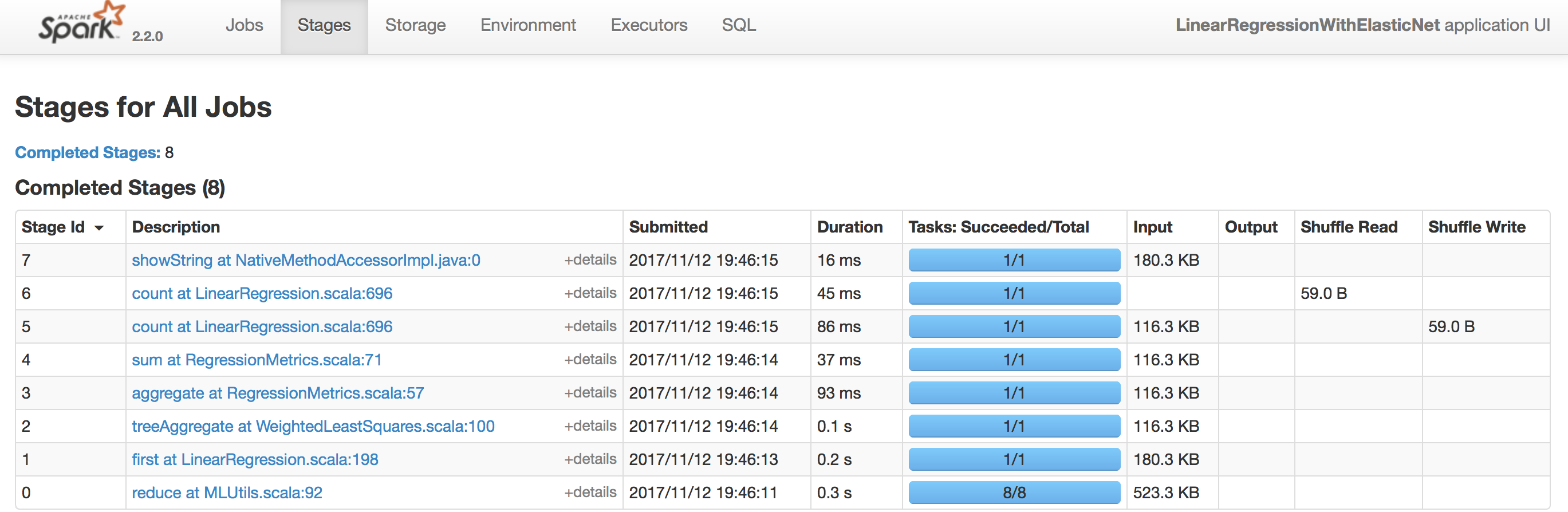
図6:Tab Stages
- Storage
Storageで当InstanceのStorageの状況を確認できます。今回のSample CodeではRDDの詳細はないのでStorgeの詳細画面はBlankになりました(図7)。

図7:Stage の詳細
- Executors
Executorsで当Executorsの詳細状況を確認できます(図8)。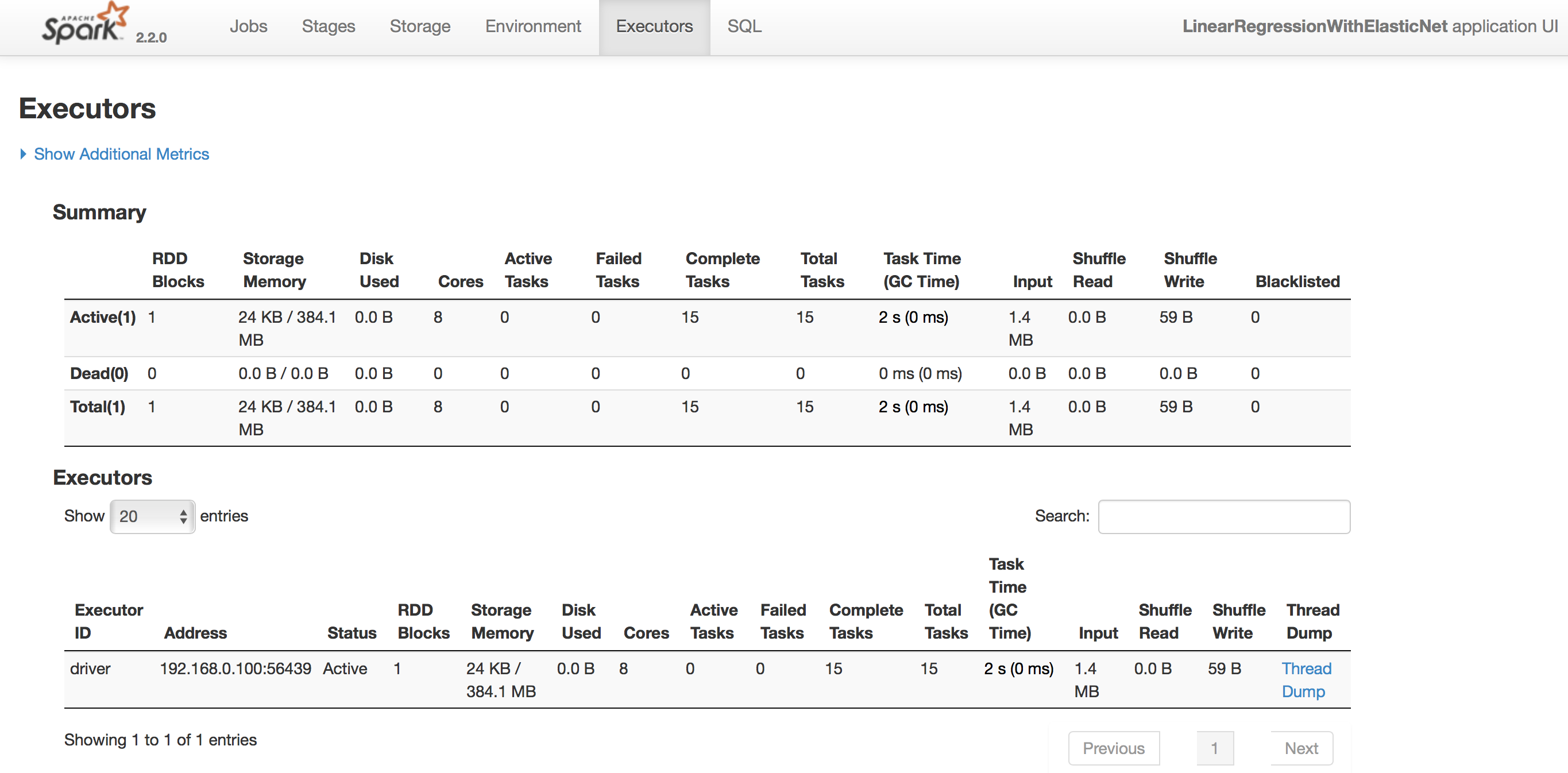
図8:Executors の詳細
- SQL
SQLでSubmitしたCodeで実行されたSQLの詳細状況を確認できます(図9)。
気になるStepのDescriptionをクリックして当Stepの詳細情報を確認できます。
今回は例としてID: 1(first at LinearRegression.scala:198)をクリックしてみました。
図10はクリック後の遷移画面です。
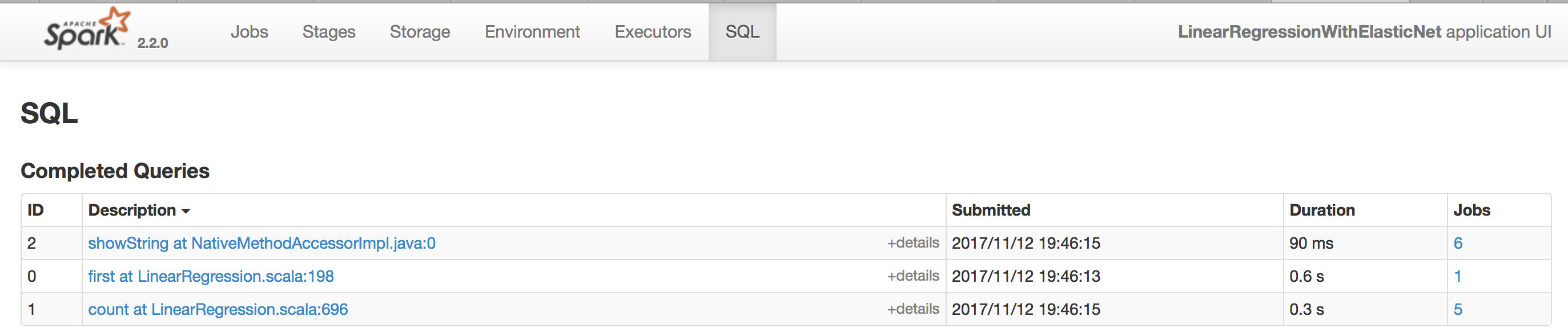
図9:SQLの詳細
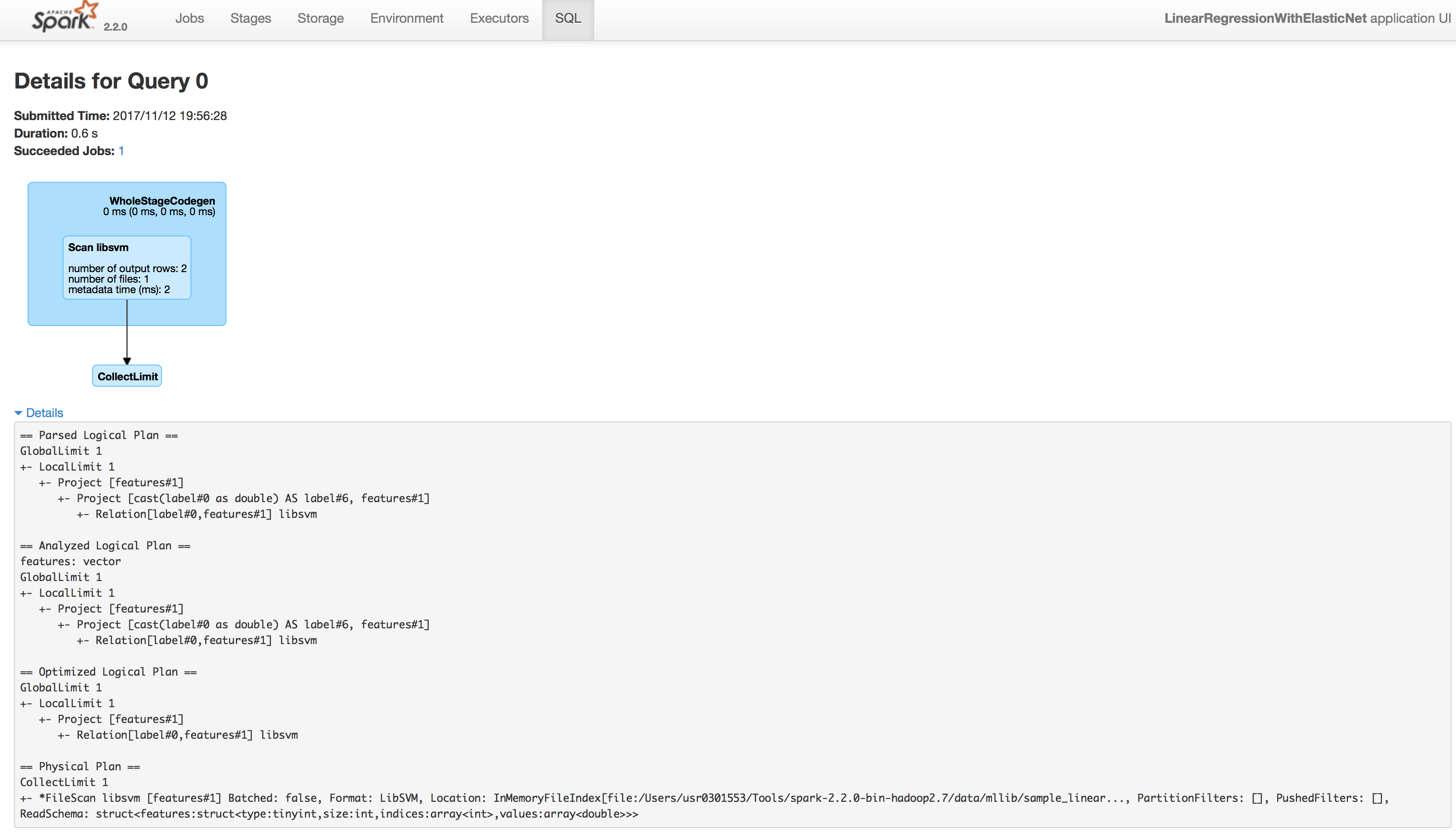
図10:SQLの詳細状況
5 まとめ
今回はSparkのWebUIについて紹介しました。いかがだったでしょうか。
私は以前、大規模なデータのSparkのProgramを開発していたときに一番悩んだのは、メモリ不足によるエラーを解決することでした。
現在はSparkのWebUI を利用することでProgramの各部分の処理時間、メモリの使用量などの状況を全て確認できるようになりました。
これにより、Programのエラー解決がスムーズになるので、皆さん興味があればSparkのProgramを開発する時にぜひ試してください。