このエントリーは、GMOアドマーケティング Advent Calendar 2018 の 12/3の記事です。
GMOアドマーケティングとしては初のAdvent Calendar参戦です。
こんにちは、GMOアドマーケティングのS.Rです。
私がSparkのProgramを開発するときに常にあった問題は並列化のチューニングです。
良いチューニングをすればProgramのPerformance を10倍以上の改良できるかもしれません。
今回はSpark に並列化をチューニングするの方法の一つDataFrameのチューニングを皆さんに共有します。
今回のブログを理解いただくためにはSpark UIを利用する知識が必要になりますのでSpark UIに詳しくない方は
前に書いたSpark UIのブログを参考してください。
1 並列化チューニングの二つの目的
並列化のチューニングには二つの目的があります。
一つは指定された処理を分散して複数のThreadで同時に処理することです。
もう一つは1つのThreadで処理するデータ量を均一にすることです。
そうしなければ処理を分散したのに処理にかかる時間は、処理をするデータ量が一番多いThreadに集中してしまいます。
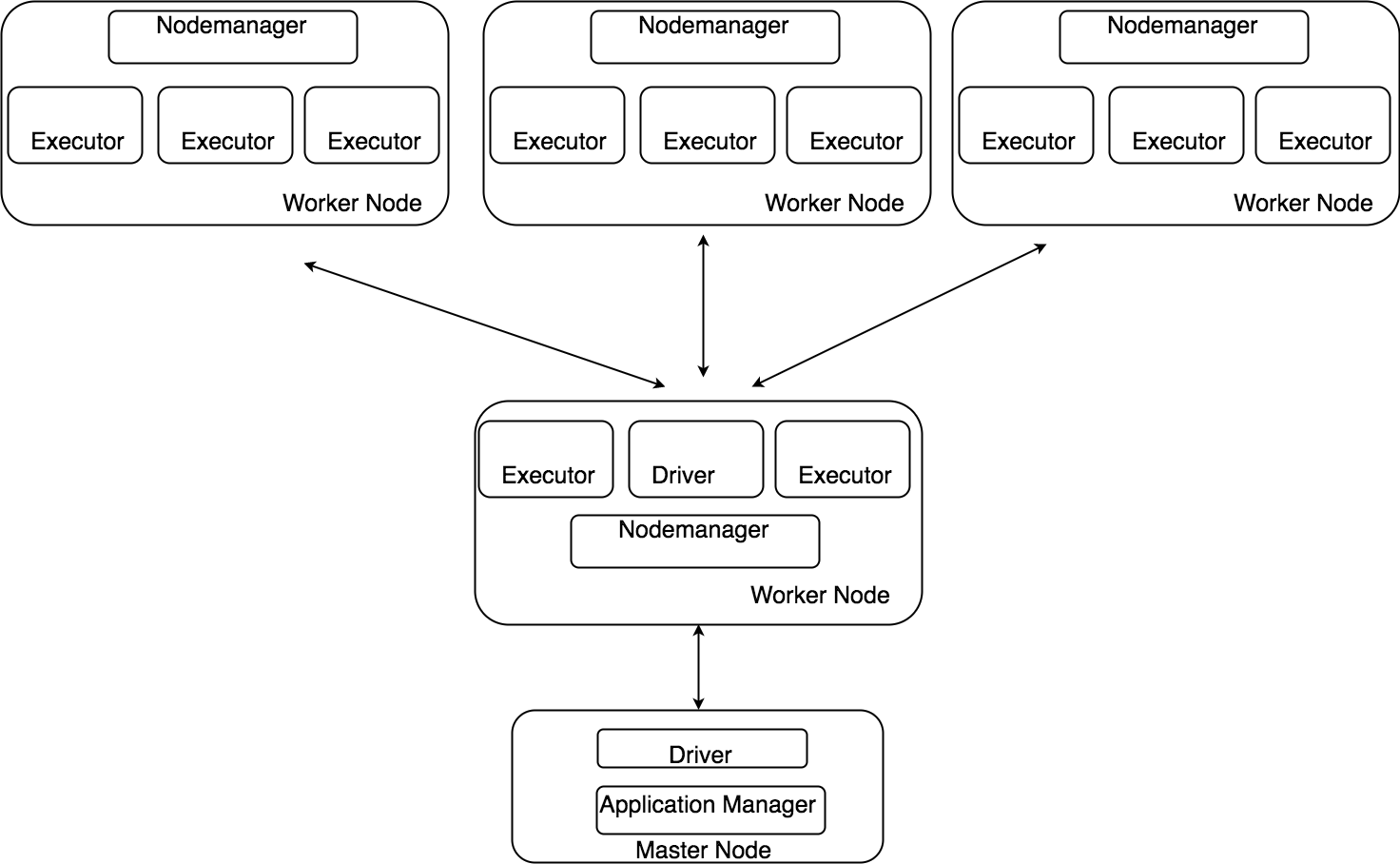
図1の例で説明します。あるデータの1つのThreadでかかる処理時間は1Tです(BLOCK A)。BLOCK Bは均一に4つに分割をして処理時間は0.25Tになります。BLOCK Cは均一ではなく、4つに分割をして処理時間を設定します。BLOCK Cの処理時間は、分割された一番多いデータの処理時間の0.75Tとなります。
2並列化改良の実戦
普段、SparkのProgramを開発するときにBLOCK Cの様な状況がよくあります。今回は素数を探す問題を例として並列化の改良方法を皆さんへ説明します。
今回の例を実行するにはSparkをinstallすることが必要です。Sparkをinstallする方法はSparkの公式ウェブサイトを参考してください。自分のPCにインストールする場合はStandalne Modeでのインストールを参考にしてください。
2.1サンプルコードを作成
- サンプルコードとして素数を探すプログラムをScalaで記述します。下記のコードをfind_prime.scalaというファイル名で保存します。
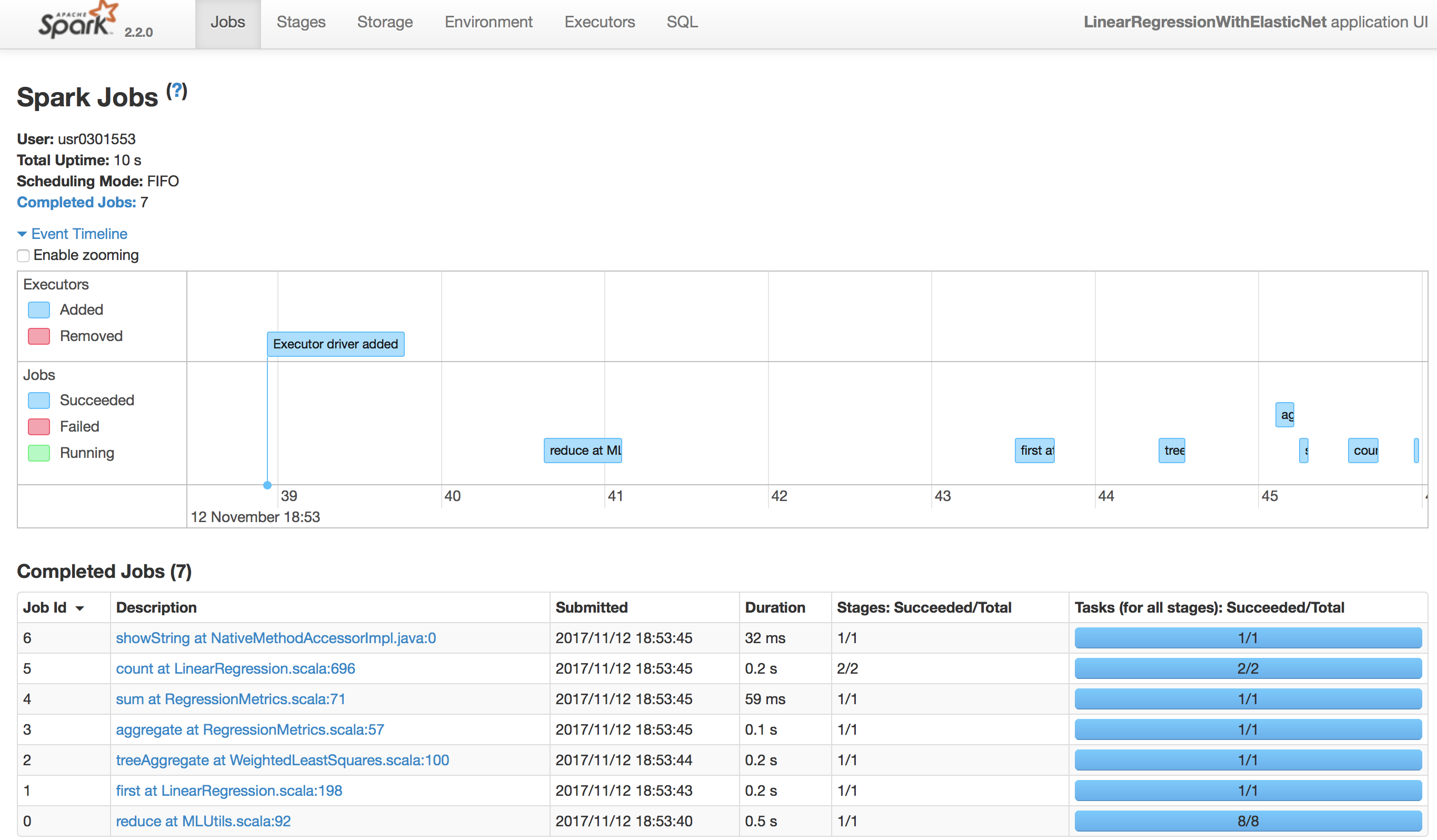
1234567val num = 2500000def find_prime(num:Int):Unit = {val composite = sc.parallelize(2 to num, 8).map(x => (x, (2 to (num / x)))).flatMap(kv => kv._2.map(_ * kv._1))val prime_num = sc.parallelize(2 to num, 8).subtract(composite)prime_num.collect()}find_prime(num) - 下記のコマンドで作成したサンプルコードを実行します。実行を完了した画面は図2です。
1bin/spark-shell -i find_prime.scala
図2:サンプルコードの実行画面 - Browserでhttp://127.0.0.1:4040へアクセスしてSpark WebUI(図3)を見ます。
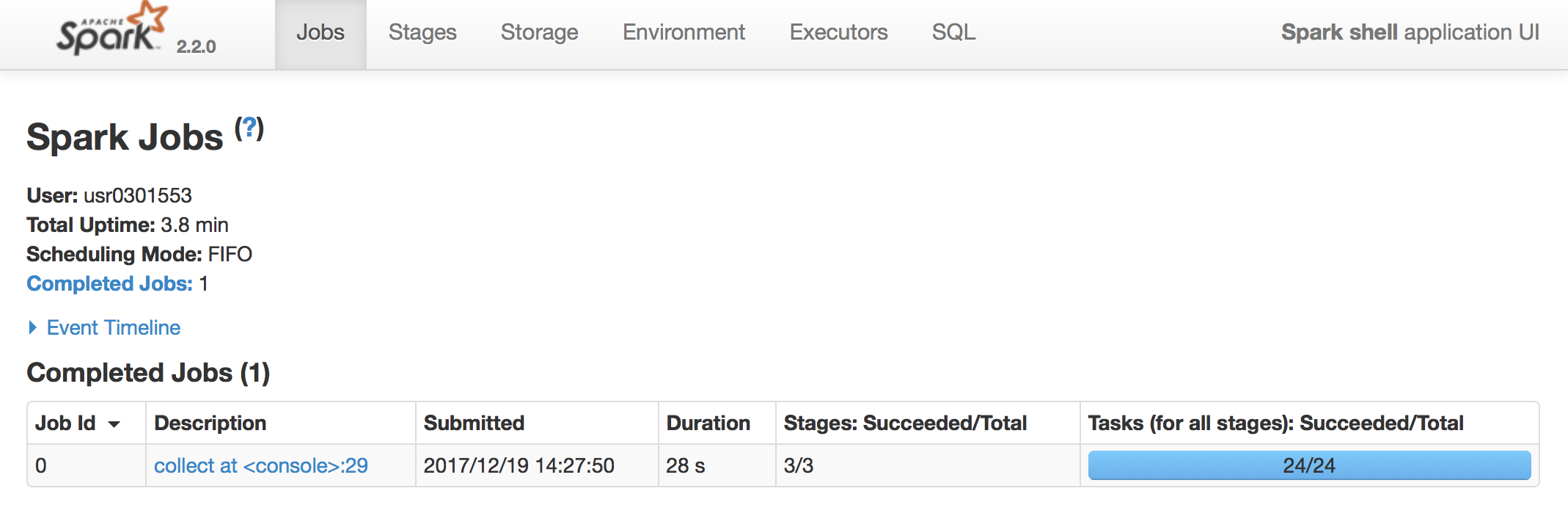
図3: Spark WebUI - 実行したJobの詳細を表示するためにリンク”collect at <console>:29”をクリックします。Jobの詳細画面で”DAG Visualization”をクリックすると図4の様なDAGが見れま(DAGの説明はWIKIPEDIAに参考して下さい)。
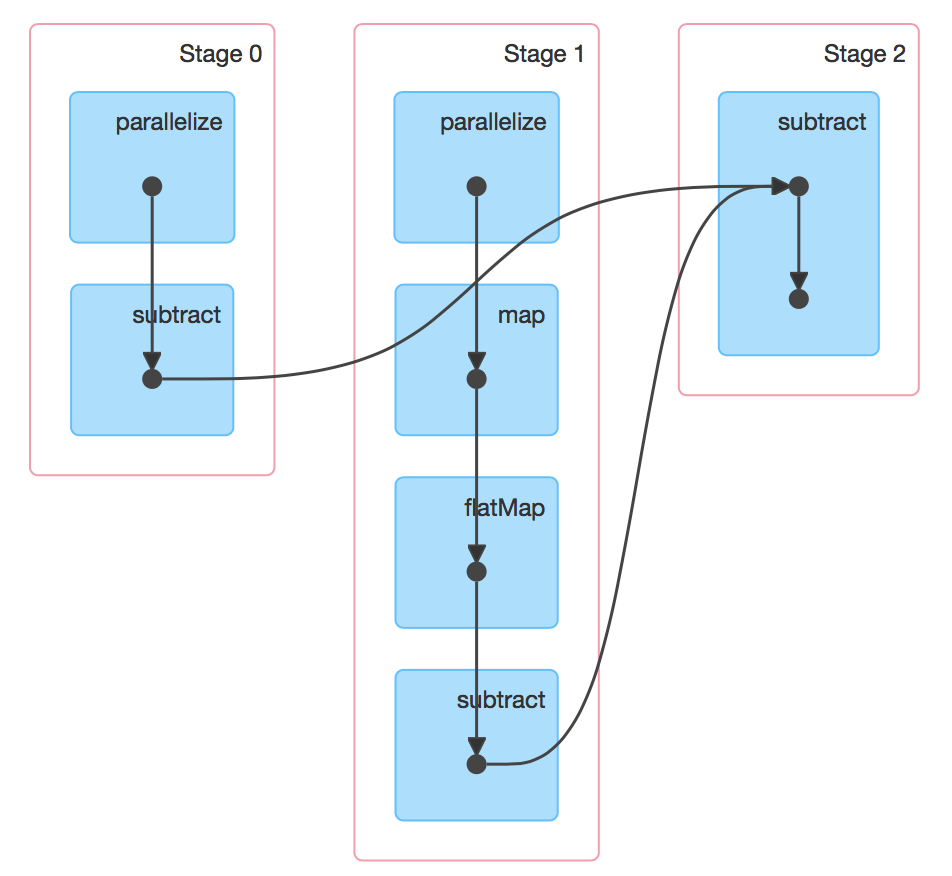
図4: DAG DAGの各stageに対応するScalaのコードは表1となります。
項目Taskで並列した各Threadの実行時間が見れます。Stage ID Scala code Stage 0 sc.parallelize(2 to num, 8).subtract(composite) Stage 1 sc.parallelize(2 to num, 8).map(x => (x, (2 to (num / x)))).flatMap(kv => kv._2.map(_ * kv._1)) Stage 2 sc.parallelize(2 to num, 8).subtract(composite) 表1:stage/Scala code
- Stage 1をクリックして詳細画面へ遷移します。項目Taskで並列した各Threadの実行時間が見れます。

図5:stage 1 各Threadの実行時間 図5を見るとStage 1をThreadで並列実行したのに、95%以上のデータをThread 0が処理していました。Stage 1で各stepに処理したデータの状況は図6です。
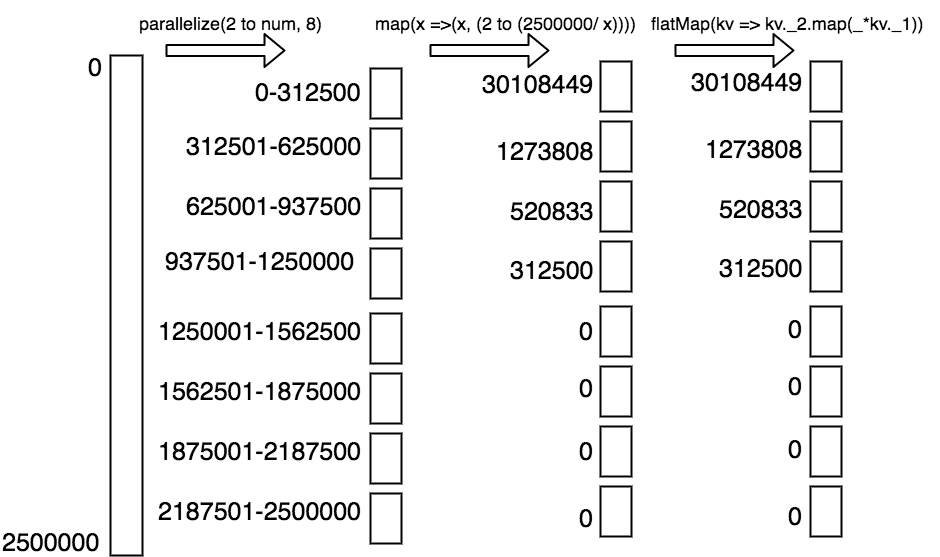
図6: 各Setpで処理したデータの状況 - 図6を見ると”map(x => (x, (2 to (num / x))))”が完了したときに各Threadで処理するデータがアンバランスになっています。そのためmap(x => (x, (2 to (num / x))))”が完了した後に、データを再分割すればPerformanceを改良できると想定できます。この想定に基づいて”map(x => (x, (2 to (num / x))))”の後に”.repartition(8)” を追加します。改良したコードは下記になります。
1234567val num = 2500000def find_prime(num:Int):Unit = {val composite = sc.parallelize(2 to num, 8).map(x => (x, (2 to (num / x)))).repartition(8).flatMap(kv => kv._2.map(_ * kv._1))val prime_num = sc.parallelize(2 to num, 8).subtract(composite)prime_num.collect()}find_prime(num)
- 改良したサンプルコードを実行してSpark Web UIで実行状況を確認します。図7は改良したサンプルコードのDAGです。
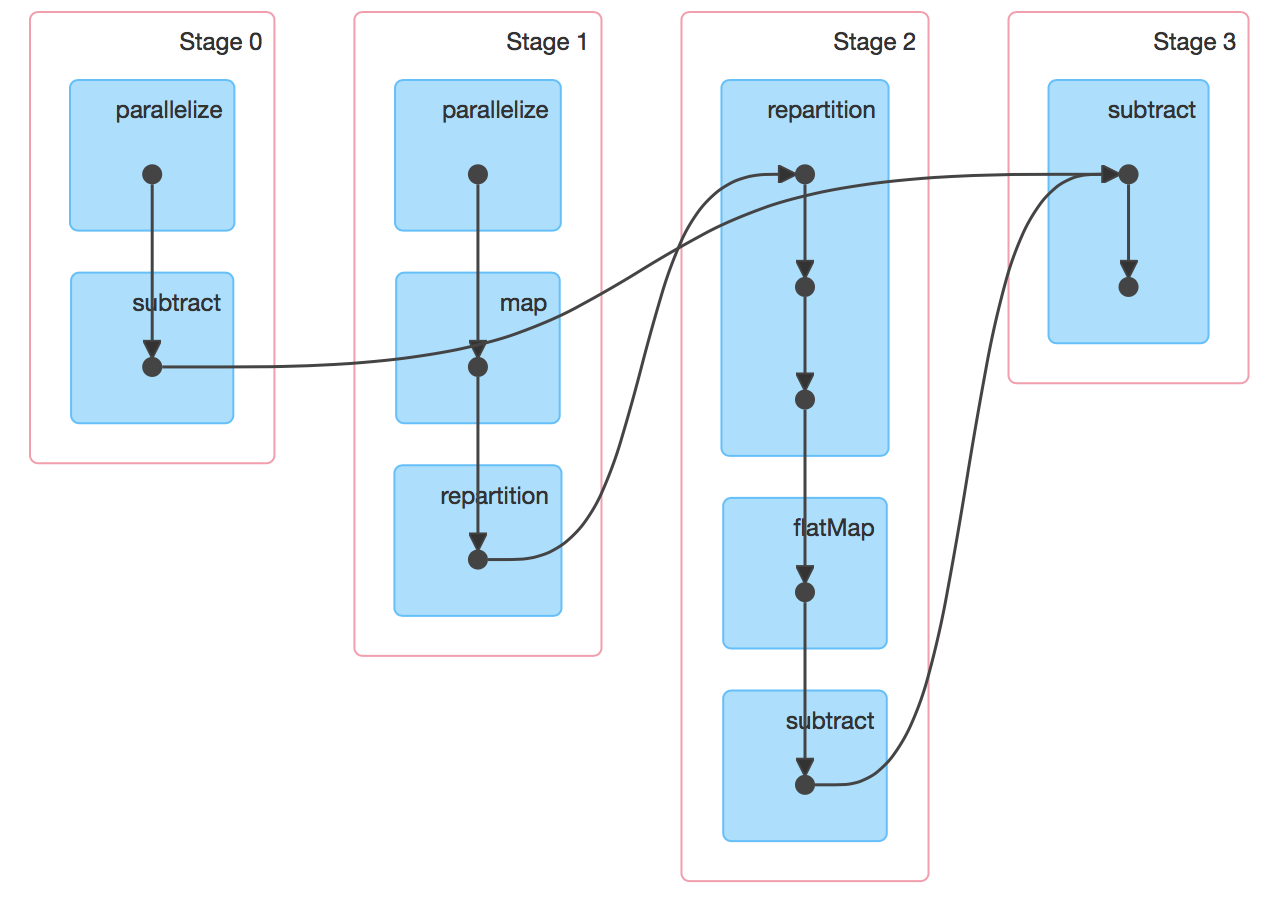
図7: 改良したサンプルコードのDAG。 各StageですべてThreadの実行時間がほぼ均一になりました(図8)。全体の実行時間は25秒から16秒になり、35%改良することが出来ました。

3 まとめ
今回はSpark 並列化のチューニングの一例を紹介しました。いかがでしたでしょうか。
普段、SparkのProgramを開発する時に、SparkのWebUIで並列化が不均一な部分を見つけたら再分割するコードを追加すればProgramのperformanceを大幅に改良できます。機会があれば皆んさんぜひ試してみてください。
明日は「RubyとGoogleスプレッドシートの連携について」についてのお話です。
お楽しみに!
クリスマスまで続くGMOアドマーケティング Advent Calendar 2018
ぜひ今後も投稿をウォッチしてください!
■エンジニアによるTechblog公開中!
■Wantedlyページ ~ブログや求人を公開中!~
https://www.wantedly.com/projects/199431
■エンジニア採用ページ ~福利厚生や各種制度のご案内はこちら~
https://www.gmo-ap.jp/engineer/
■エンジニア学生インターン募集中! ~有償型インターンで開発現場を体験しよう~
https://hrmos.co/pages/gmo-ap/jobs/0000027