
このエントリーは、GMOアドマーケティング Advent Calendar 2018 の 【12/25】 の記事です。
GMOアドマーケティングとしては初のAdvent Calendar参戦です。
こんにちは。GMOアドマーケティングの佐藤です。弊社では今年3つのマイクロサービスにKubernetesを導入しました。minikubeのローカル環境で開発、ステージング環境でテスト後、本番環境にデプロイします。弊社ではGKEを使っていますが、ローカルではうまくいっても、本番にデプロイした際に、いくつかのトラブルに見舞れることがありましたので、その内容と解決方法を共有できればと思います。
1. Preemptive VM Instanceが買えない場合がある
広告のサービスはピーク時間帯とアイドル時間帯でアクセスが10倍以上違う場合があるため、アクセスに応じてオートスケールするように設定しています。現在の構成は、例えば3ノードは確約利用割引で年間契約をすることで最大 57% の割引が適用され、もう3ノードはpreemptive instance という、24時間以内に終了してしまう、通常より最大80%の割引を受けれるインスタンスを利用しています。オートスケールする方のインスタンスにはこちらのpreemptive instanceを利用しています。
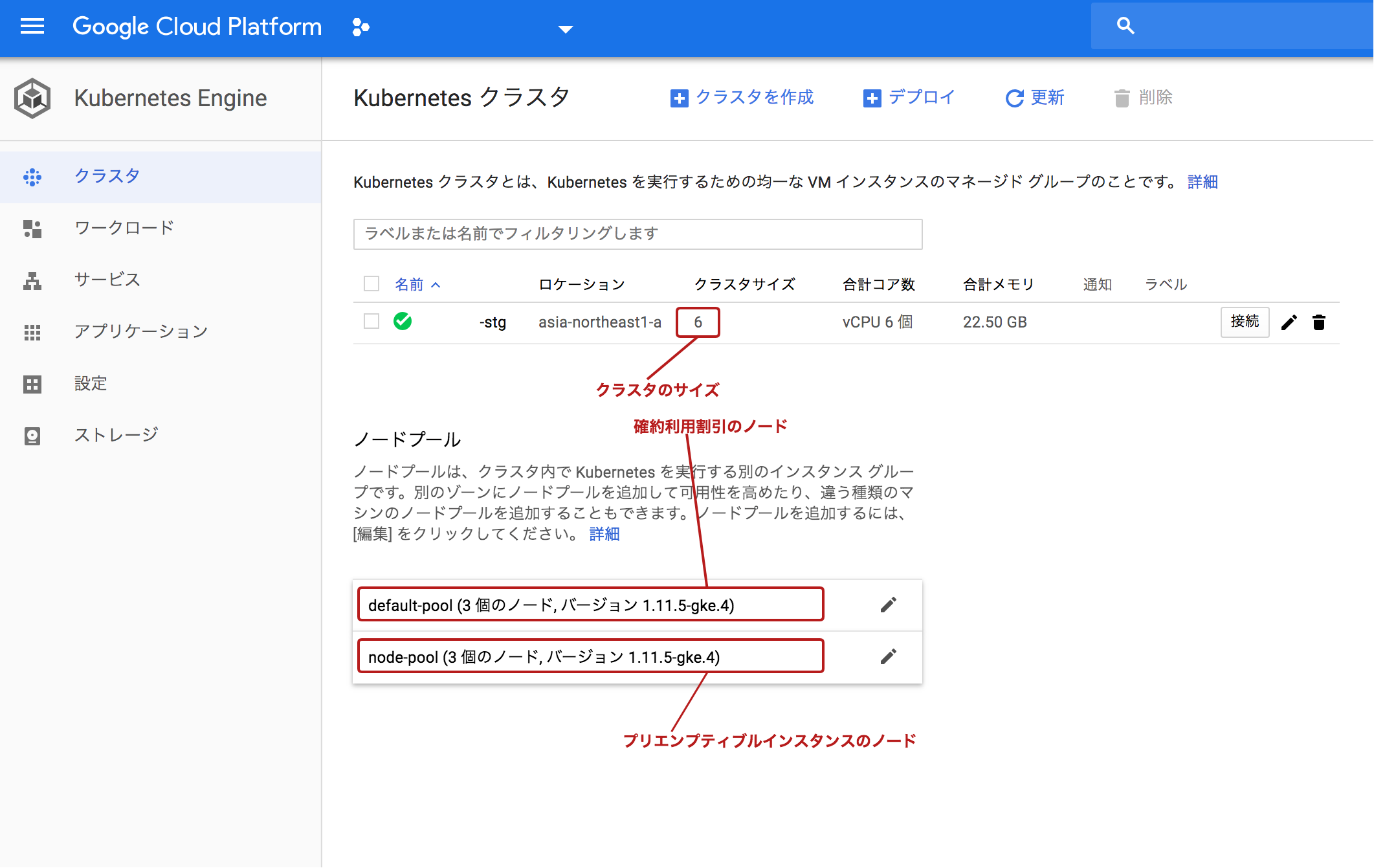
ただ、運用を行っている中で、在庫の問題か、Preemptive Instanceが買えないケースに遭遇しましたので以下のような対応をしました。
まずはデフォルトのノードを作ります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
gcloud container clusters create ${CLUSTER_NAME} \ --addons HorizontalPodAutoscaling,HttpLoadBalancing,KubernetesDashboard \ --cluster-version ${CLUSTER_NODE_VERSION} \ --disk-size ${NODE_DISK_SIZE} \ --disk-type "pd-standard" \ --enable-autorepair \ --enable-autoscaling --min-nodes ${MIN_NODES} --max-nodes ${MAX_NODES} --num-nodes ${START_NODES} \ --enable-autoupgrade \ --image-type "COS" \ --machine-type ${TYPE_OF_MACHINE} \ --maintenance-window "00:00" \ --network "default" \ --no-enable-basic-auth \ --no-enable-cloud-logging \ --no-enable-ip-alias \ --no-issue-client-certificate \ --project ${PROJECT_NAME} \ --scopes "https://www.googleapis.com/auth/cloud-platform" \ --subnetwork "default" \ --zone=${ZONE} |
次にpreemptive instanceのノードを作ります。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
gcloud container node-pools create "node-pool" \ --disk-size ${NODE_DISK_SIZE} \ --disk-type "pd-standard" \ --enable-autorepair \ --enable-autoscaling --min-nodes ${MIN_PREEMP_NODES} --max-nodes ${MAX_PREEMP_NODES} --num-nodes ${START_PREEMP_NODES} \ --enable-autoupgrade \ --image-type "COS" \ --machine-type ${TYPE_OF_MACHINE} \ --preemptible \ --project ${PROJECT_NAME} \ --scopes "https://www.googleapis.com/auth/cloud-platform" \ --zone=${ZONE} |
さらにDeploymentの設定で、Node Affinityを設定します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
--- apiVersion: apps/v1 kind: Deployment spec: template: metadata: affinity: # OPTION 1) run NOT on preemptive nodes # nodeAffinity: # requiredDuringSchedulingIgnoredDuringExecution: # nodeSelectorTerms: # - matchExpressions: # - key: cloud.google.com/gke-preemptible # operator: DoesNotExist # OPTION 2) if possible run on preemptive nodes nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - preference: matchExpressions: - key: cloud.google.com/gke-preemptible operator: Exists weight: 100 |
上記の設定の場合、Option1の場合は、基本的にはDefault Node PoolにPodを配置します。Option2の場合は、基本的にはPreemptive Node Poolを使用しますが、Preemptive Node PoolにInstanceが獲得できなかった場合には、Default Node Poolを利用するようにします。
2. Default Node PoolにInstanceが想定より多く居座る問題と、Pod作成時の注意点
1.の問題に関連する問題なのですが、上記の設定をしていると、Preemptive Instanceの取得が失敗すると、Default Node PoolのInstanceが使用されます。Preemptiveインスタンスと違い、24時間では終了されず、確約利用割引もないため、そのまま高いインスタンスが居座ってしまいます。そのため、弊社では、Default Nodeと Preemptive Nodeが何個になっているべきかをチェックし、想定通りになっていない場合には Nodeを終了するようなスクリプトを作成し、Kubernetes Jobとして定期実行しています。Kubernetesのpodを作成するときに重要な点として
- あるノードが突然killされても大丈夫なようにpod内のアプリケーションを作成する
- あるノードが突然killされても大丈夫なようにpodを配置する(SPOFを無くす)
- どの順番でpodが起動しても問題ないように設定をする
- 突然Nodeがkillされても負荷等に問題が無いようにある程度余裕を持ってリソースを割り当てる
があります。上記を守っていれば、特定Nodeをkillしたり、Preemptive Instanceなどが突然終了しても問題なく自動で復旧できます。
3. resource requests と resource limits の設定
Kubernetesクラスタ内で動かすpodには、ノードに要求するCPU, Memoryのリソースを定義する resource.requestsと、そのpodで利用できるリソースの最大値を定義する resource.limitがあります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
apiVersion: v1 kind: Pod metadata: name: busybox-sleep spec: containers: - image: busybox name: busybox args: - sleep - "1000000" resources: requests: cpu: 600m memory: 100Mi limits: cpu: 750m memory: 300Mi |
CPUは1coreで1000mの計算です。上記設定の600mだと、1coreの6/10を要求します。memoryは Mibを指定します。ここで設定の際にいくつか気をつけなければならない点があります。
- 設定ファイルの合計要求リソースがノードの合計リソースを下回っていてもデプロイできない場合がある
- requestsを設定すると、実際に使っていなくても、設定ファイルの合計値が物理ノードの合計値を超えることができません。また上記の設定で 1core 1G Memory のノード3つで構成した場合、3個まではpodを増やせます。4つめは合計値が600m x 4で2400なので、3core = 3000を下回っているので、一見デプロイできるように見えますが、実際は下図のようにデプロイできません。
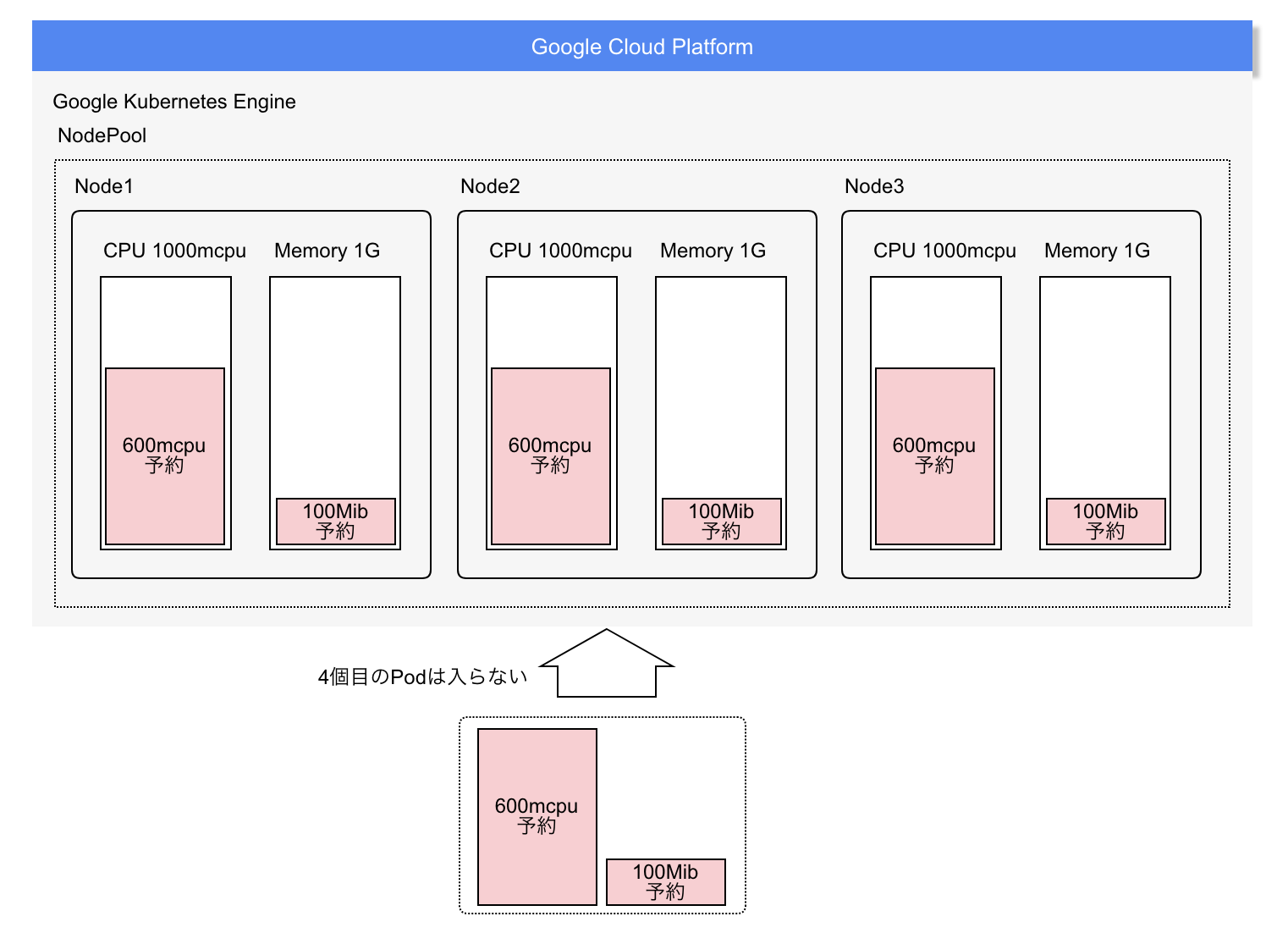
- requestsを設定すると、実際に使っていなくても、設定ファイルの合計値が物理ノードの合計値を超えることができません。また上記の設定で 1core 1G Memory のノード3つで構成した場合、3個まではpodを増やせます。4つめは合計値が600m x 4で2400なので、3core = 3000を下回っているので、一見デプロイできるように見えますが、実際は下図のようにデプロイできません。
- 実際は1core 1000mcpuが割り当てられるわけではない
- 実際のnodeは1core(Standard1)のノードを起動しても、1000mを使えるわけではないです。下の図を見ると実際には、940mしか割り当てられていません。つまり、resources.requests.cpu に 1000を割り当てると1podもデプロイすることができません。
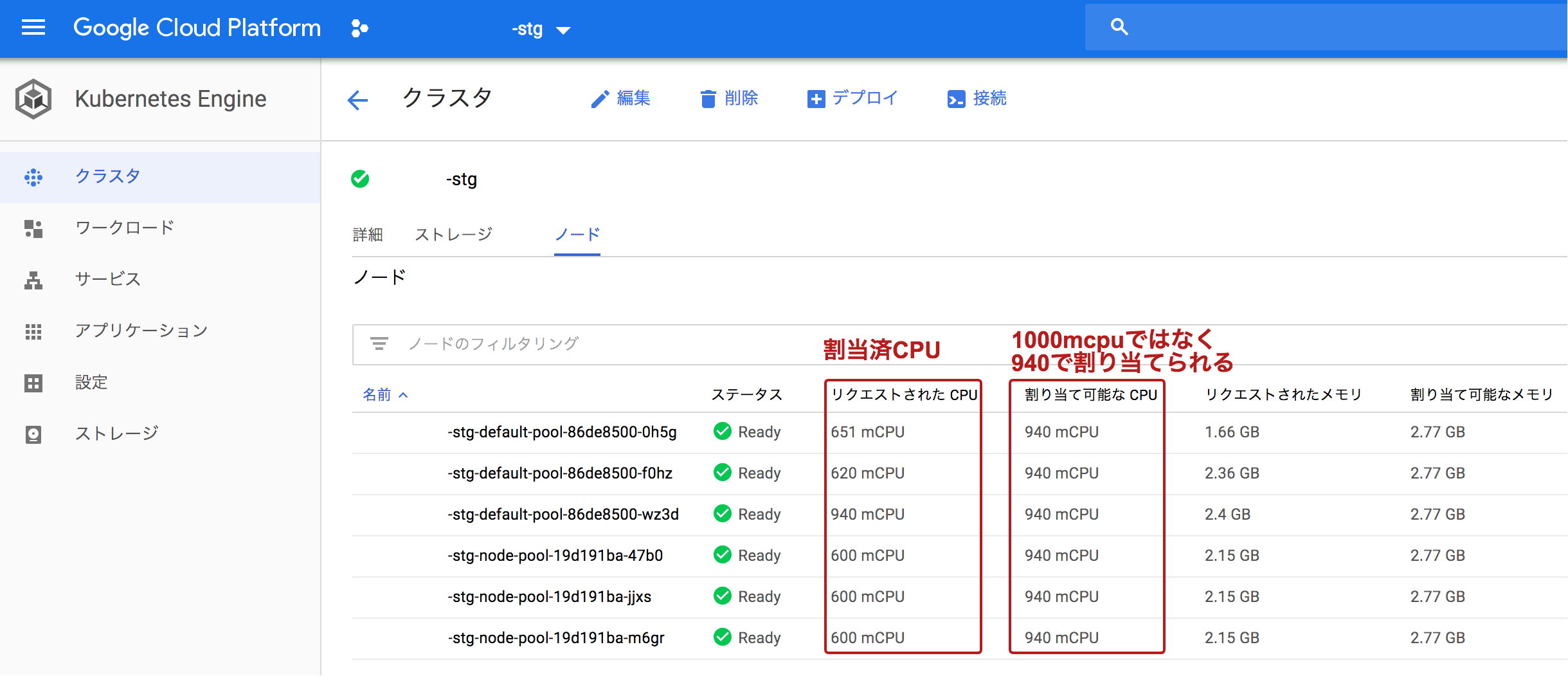
- 実際のnodeは1core(Standard1)のノードを起動しても、1000mを使えるわけではないです。下の図を見ると実際には、940mしか割り当てられていません。つまり、resources.requests.cpu に 1000を割り当てると1podもデプロイすることができません。
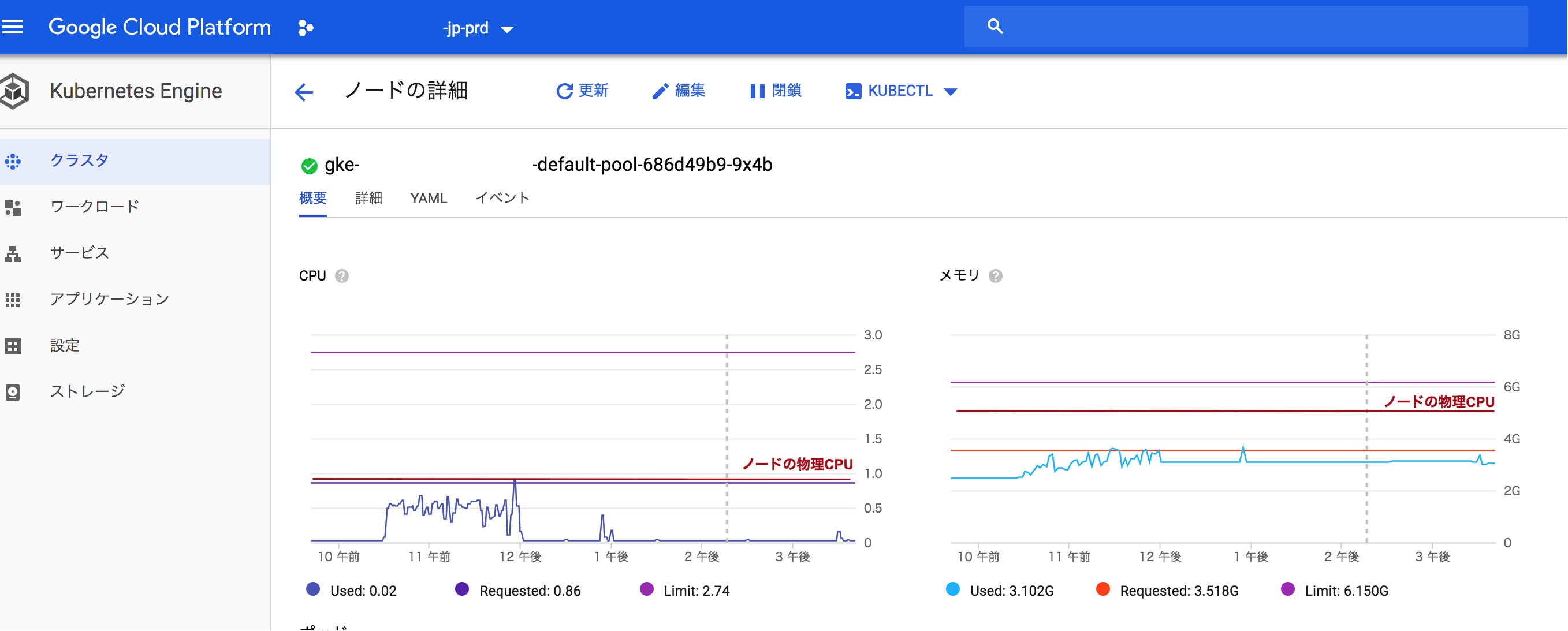
- Pod AutoScalerの設定
- limits.cpuは設定ファイルの合計値が物理ノードの最大値を超えても、遅くなるだけで問題ありません。limits.memoryはアプリケーションが memory limitを超えて memoryを確保しようとするとOOM killerがprocessをkillします。また、1ノード内のpodのMemoryの合計がNodeのMemoryを超える場合、同じくOOM killerが発生します。podのオートスケールは例えば、「CPUが50%超えたらスケールする」と設定した場合、resources.requestsの 50%を超えるとオートスケールが実行されます。
4. 不良のnodeを引き当ててしまう
まれにネットワークカードなどが物理的に壊れているインスタンスがノードが割り当てられてしまうことがあります。その場合、podが突然終了したり、再起動を繰り返したりすることがあります。その場合
|
1 |
kubectl delete node nodename |
などでノードを削除しても、同じ物理サーバを使ってノードを作成してしまうため問題が解決されない場合があります。その場合は
|
1 |
gcloud compute instances delete instancename |
などのコマンドや GCEの管理画面上から、直接削除を行っています。削除が終わると、Kubernetesが設定に従って、自動的にインスタンスを増やそうとします。この点はまだ自動化できていないので、今後の解決したい課題でもあります。
5. 常にproduction環境を再構築できるようにしておく
現在Kubernetes関連のプロジェクトは活発に開発が行われており、頻繁に本体のバージョンアップも行われています。ただしごく稀に不安定なバージョンがリリースされることもあります。Ingressに大きな変更がある時や、Kubernetes本体のバージョンを上げる場合は、別に新しいproductionクラスターを作り、GSLBを利用して一部のトラフィックを流すようにして、問題なければ、全部のトラフィックを新本番に切り替えて、旧本番クラスターを削除するようにしています。GSLBは “さくらのクラウド” のGSLBを使っています。 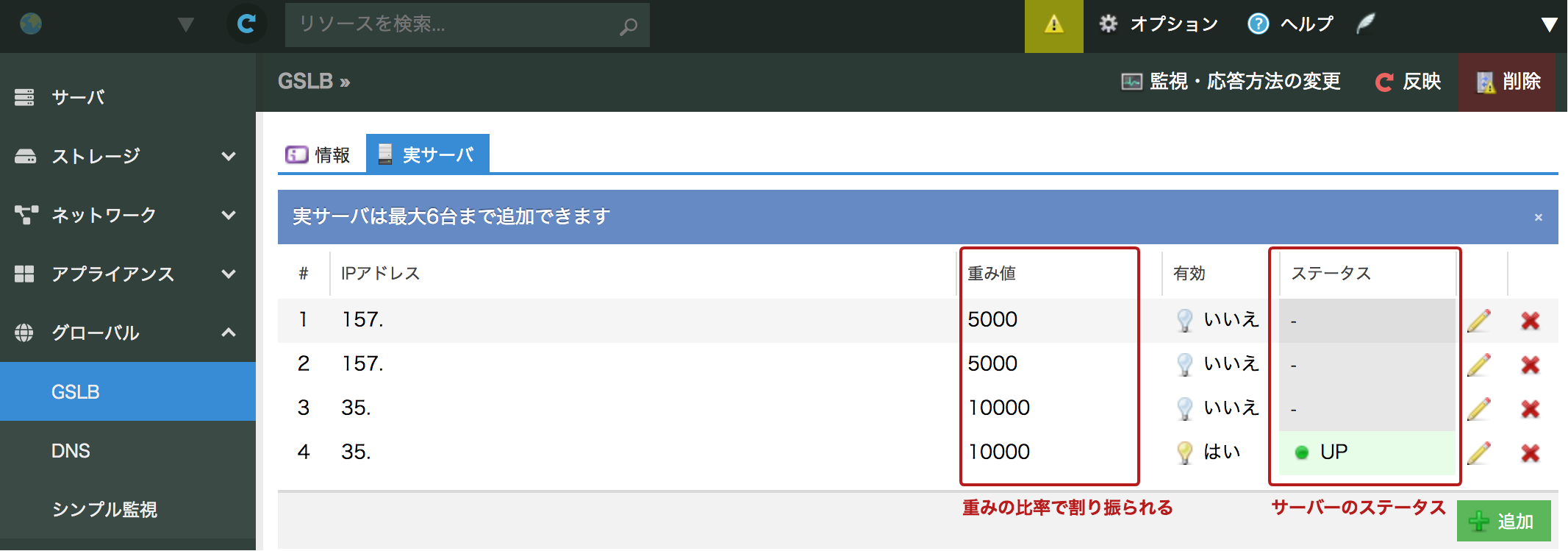
DNSのCNAMEにGSLBのアドレスを書くことによって、GSLBの重み設定に従って負荷を振り分けてくれます。また振り分け先IPアドレスの死活監視も行っており、対象サーバが接続できなくなると自動的に振り分け先から外してくれます。GSLBを用いることで、アプリケーションによってはマルチリージョン化、マルチクラウド化なども簡単に行うことができます。Kubernetesのクラスタ名は productname-production-version など、バージョン番号をつけており、環境構築も Kubernetes以外に、Terraform, Google Cloud Manager, gcloudコマンドなどを利用して、すぐに新しいproduction環境を作れるようにしています。
Kubernetesについては社内でまだまだやれることは多いですが、インフラチーム、SREチームが行わなければならない運用を減らせることができていると感じています。溜まったノウハウなどがあったらまた投稿できたらと思います。
本日でAdvent Calendar 2018も最終日ですが、ぜひ今後も投稿をウォッチしてください!
■エンジニアによるTechblog公開中!
https://techblog.gmo-ap.jp/
■Wantedlyページ ~ブログや求人を公開中!~
https://www.wantedly.com/projects/199431
■エンジニア採用ページ ~福利厚生や各種制度のご案内はこちら~
https://www.gmo-ap.jp/engineer/
■エンジニア学生インターン募集中! ~有償型インターンで開発現場を体験しよう~
https://hrmos.co/pages/gmo-ap/jobs/0000027

