皆さん
こんにちは、GMOアドマーケティングのS.Rです。
今回はよく使われる機械学習のアルゴリズムRodomForestを皆さんへ紹介致します。
この記事を理解するには、中学レベルの数学とPythonの基本知識が必要です。
Random Forestは2001年にLeo BreimanさんからDecision Treeを発展して提案されたアルゴリズムです。それでは、Random Forestを理解していただくために、まずはDecision Treeについて紹介いたします。
1 Decision Tree(決定木)
機械学習の分野において、Decision Tree(決定木)は予測モデルです。ある事項に対する観察結果から、その事項の目標値に関する結論を導きます。内部節点は変数に対応し、子節点への枝はその変数の取り得る値を示します。 葉(端点)は、根(Root)からの経路によって表される変数値に対して、目的変数の予測値を表します。Decision Treeの学習は、元となる集合を属性値テストに基づいて部分集合に分割することにより行うことができます。 この処理は、すべての部分集合に対して再帰的に繰り返されます。 繰り返しは、分割が実行不可能となった場合、または、部分集合の個々の要素が各々1つずつの分類となった段階で終了します。(決定木、2017年8月15日、ウィキペディア日本語版、https://ja.wikipedia.org/wiki/%E6%B1%BA%E5%AE%9A%E6%9C%A8)。
例えば、ある人(山田さん)はゴルフが好きで、時々ゴルフ場へ出かけます。以下の表に山田さんが過去一ヶ月間にゴルフ場へ行った履歴と天気、風、週末などの情報を合わせて集計しました。この情報でDecision Treeのモデルを訓練して今日山田さんゴルフ場へ行くかを予測します。

表1:山田さんのゴルフカレンダー
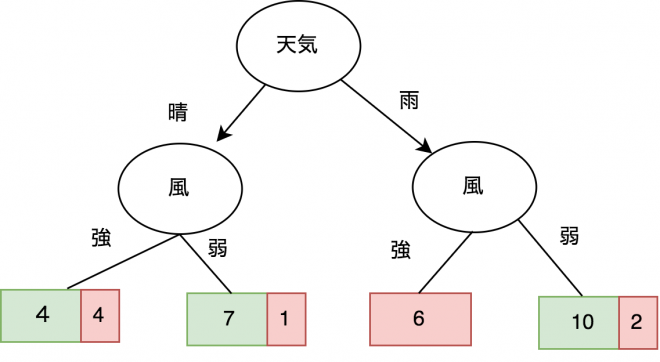
まずDecision Treeを学習します。最初はRoot Nodeに天気でデータを分割します(図1)。分割された結果みると天気が晴れのときに山田さんはゴルフへ行く確率は50%,雨の時は47%です。天気だけで考えると、山田さんがゴルフへ行くかどうかの判別は難しいです。
図1:天気でデータを分割
次に、分割されたデータをさらに「風」の情報で分割します。図2は分割された結果です。分割された結果からみると雨が降ってるかつ風が強い時に山田さんはゴルフへ行かず、晴れてるかつ風が弱い、雨かつ風が弱い時にゴルフへ行く可能性が高いことがわかります。ただし、風が強いかつ晴れの時に山田さんがゴルフへ行くかどうかはまだ判別が難しいです。
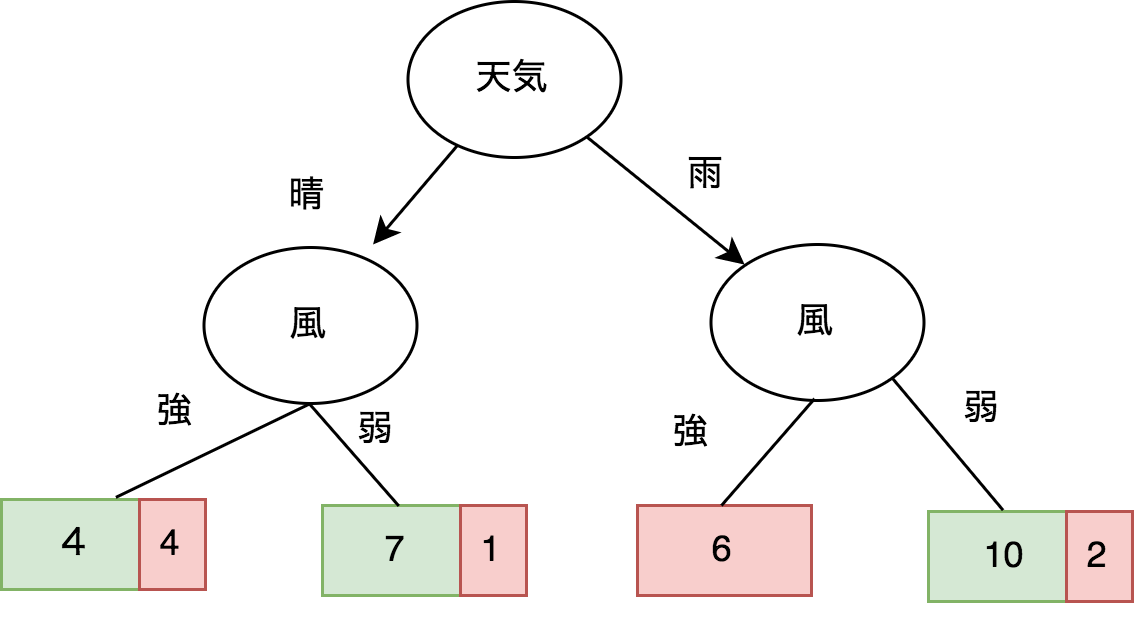
図2:風でデータを再分割
最後に、週末かどうかを特徴として、もう一度教師データを分割します(図3)。分割された結果はDecision Treeの学習した結果です。分割された結果を見ると、晴れの週末に風が強ければ山田さんはゴルフ場へ行く可能性が高いことがわかります。また、晴れの平日に風が強ければ山田さんはゴルフ場へ行かない結果となりました。そこで、山田さんがゴルフ場へ行くかどうかを予測するDecision Treeを学習しました。このDecision Treeで天気、風、週末かどうかなどの情報を分ければ 山田さんがゴルフ場へ行く確率を予測できます(表2)。

図3:Decision Tree
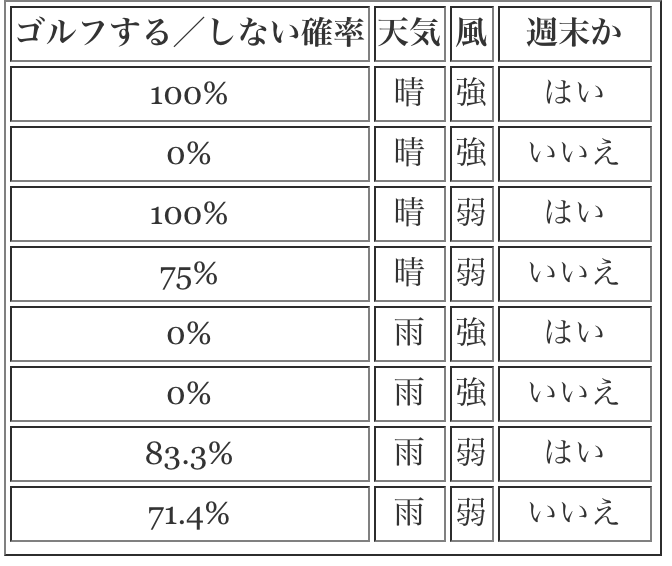
表2:山田さんゴルフ場へ行く確率
2 Random Forest
Decision Treeはアルゴリズムとしてすごく理解しやすいですが大きな欠点があります。その欠点は「Over Fitting」(Overfitting,( 2017/08/24 16:08). In Wikipedia: The Free Encyclopedia. Retrieved from https://en.wikipedia.org/wiki/Overfitting)です。これは、Decision Treeのモデルを訓練する時に教師データのノイズに対する処理を考えてないことが原因です。そのため、Decision Treeのモデルを訓練する時に正解データだけではなくノイズも含めて学習してしまうため、この学習で得られたDecision TreeのモデルはBiasが高いです。つまり、学習したモデルは教師データに対しては高い精度を持つが、実際に運用する際には精度が悪くなるということです。
Random Forestはこの欠点を改良しました。 解決方法はモデルを学習する前に教師データに ランダム性を入れて教師データのSubsetを作り、各SubsetのノイズのBiasを差し引きます。全体で2つのステップがあります。
- 教師データを復元抽出し、N分の新しいデータセットを作成します。よく使われる抽出されたデータセットのサイズはもとのデータセットサイズの平方根です。
- 抽出された新しいデータセットでDecision TreeをN本訓練します。
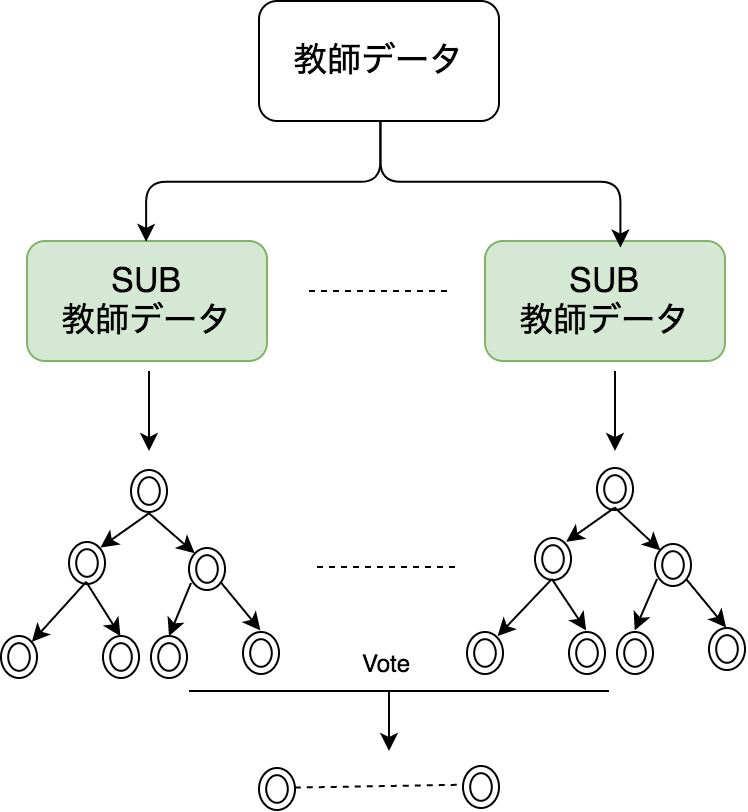
図4:Random Forestの訓練
訓練されたRandom ForestのモデルにDecision TreeがN本あります。予測する時に一つのCaseに対してDecision Treeの予測結果をN個出せます。Random Forestの結果はこのN個結果から”Vote”して点数が高い方で決まります。
3 Merit・Demerit
Random ForestのMerit・Demeritは表3の通りです。

表3:Random ForestのMerit・Demerit
4 Scikit-learnで検証する
最後はPythonの機械学習ツールScikit-learnで、irisの分類問題に対してRandom Forestを試してみましょう。irisの分類問題についてはこちらをご参考下さい。
Scikit-learn、またはPythonをインストールしていない人はこちらを参考してインストールしてください。
Step 1: Library Import
まずScikit-learnのlibraryをimportします。
|
1 2 3 4 5 |
from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier import pandas as pd import numpy as np np.random.seed(0) |
Step 2: Download Training Dataset
irisの教師データをダウンロードします。
|
1 2 3 |
iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names) |
irisの教師データをダウンロードされたデータを確認する為に最初の五つデータをprint outします。ダウンロードに成功すれば表4ような結果が得られます。
|
1 |
df.head() |
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
表4:Random Forestの教師データ
Step 2: Training と Test を分けます
irisの教師データからRandomに80%のデータを抽出しTraining Dataにします。残る部分はTest Dataにします。
|
1 2 |
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75 df.head() |
Step 3: Random Forestのモデルを訓練します
Random Forestのモデルを訓練します。 n_estimatorsは木の数です。n_jobsは並列に実行するjob数です。
|
1 2 3 4 |
features = df.columns[:4] y = pd.factorize(train['species'])[0] clf = RandomForestClassifier(n_estimators=20, n_jobs=2) clf.fit(train[features], y) |
Step 4: モデルの精度を計算します。
Step 2に抽出されたTest Datasetでモデルの精度を計算します。計算に成功すれば表5ような結果が得られます。
|
1 2 |
preds = iris.target_names[clf.predict(test[features])] pd.crosstab(test['species'], preds, rownames=['Actual Species'], colnames=['Predicted Species']) |
| Predicted Species | setosa | versicolor | virginica |
|---|---|---|---|
| Actual Species | |||
| setosa | 13 | 0 | 0 |
| versicolor | 0 | 5 | 2 |
| virginica | 0 | 0 | 12 |
表5:モデルの精度
5 Future Reading
今回はRandom Forestについて紹介しました。いかがだったでしょうか。
Random Forestの原理をさらに深く理解したい方は下記の論文と動画が詳しいのでぜひご覧ください。
- Breiman,Leo. (2001). Random forests. Machine learning, 45(1), 5-32.
- Thales,Sehn Körting(2014).How Random Forest algorithm works,http://www.youtube.com/watch?v=Vja83KLQXZs.
また、Random Forestの実装については下記の記事もおすすめです。



