
はじめに
この記事は GMOアドマーケティング Advent Calendar 2023 10日目の記事です。
おはようございます。こんにちは。こんばんは。
GMOアドマーケティングのY-Kです。
前回、OpenAIのEmbeddings APIを使って文の意味上の類似度を計算しました。
記事のタイトルをあらかじめベクトル化しておき、新たに与えた記事のタイトルと似た内容の記事タイトルをレコメンドするといった内容でした。
今回はgoogle cloud platform(GCP)を活用して、記事のデータはBigQueryで管理し、Googleが開発したLLM「PaLM」を利用して記事をベクトル化してレコメンドするプログラムを書こうと思います。
GCPは初回登録時にフリートライアルで90日間で300$分のクレジットがもらえるので、お試しの範囲であればお釣りが出ると思います。
円安の影響で、日本円に換算すると約45,000円分です。とてもお得に感じますね。その分、費用も増えていますが・・・
データの準備
前回と同じく、ChatGPTを利用してデータを作成していきます。
AI、猫、ITについての記事のタイトルをそれぞれ5つずつ作成してcsv形式で出力してもらいました。
便利すぎて怖いです。
やりとり:https://chat.openai.com/share/53019d1d-7c1b-4ef2-894e-bb121122e542
できたcsvファイルをBigQueryにアップロードしていきます。
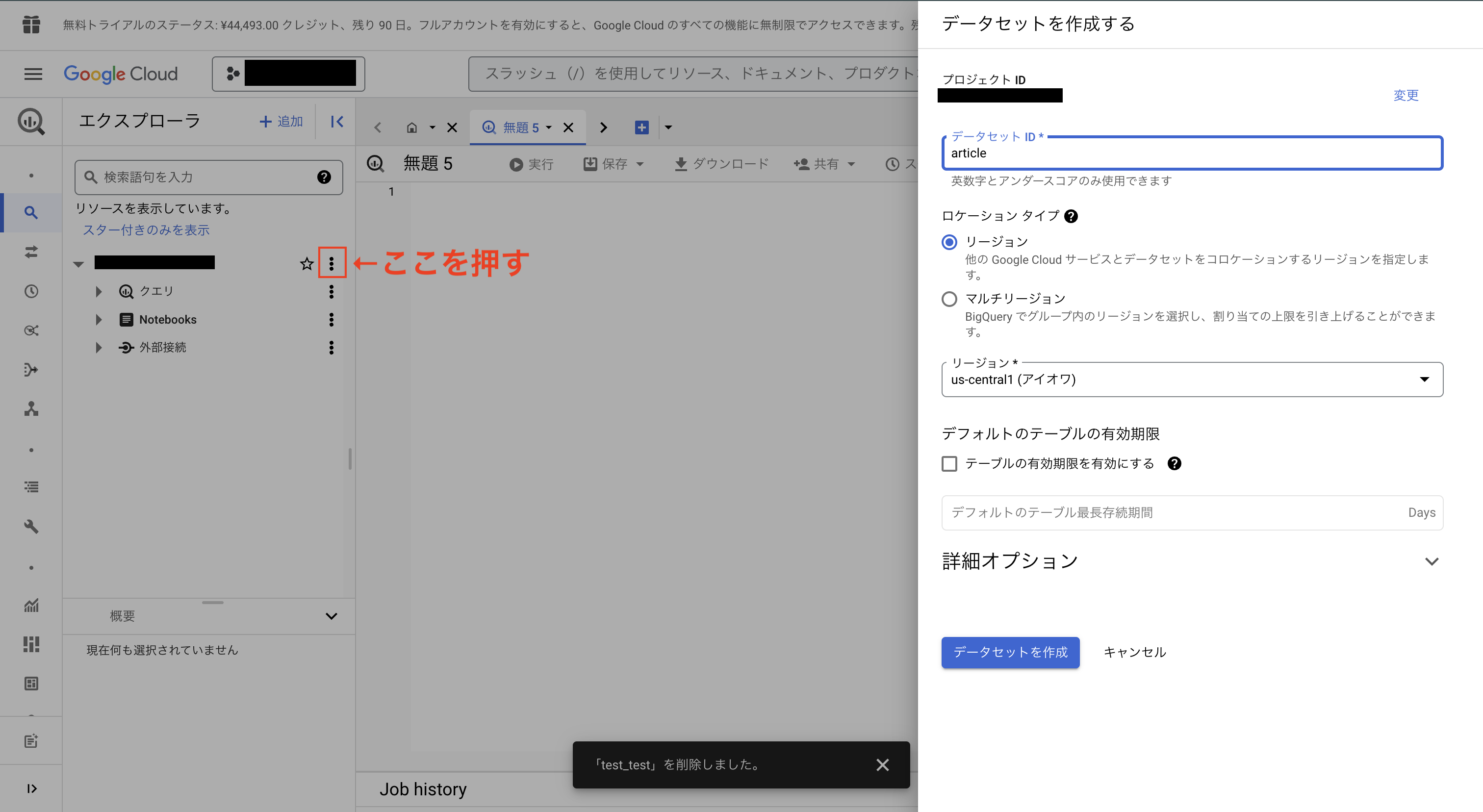
GCPのコンソール画面でBigQueryを選択し、プロジェクトIDをの横の3つの点のところを押してデータセットを作成します。
今回はデータセットIDをarticleに、リージョンをus-central1にします。
データセットを作成したら次はテーブルを作成します。
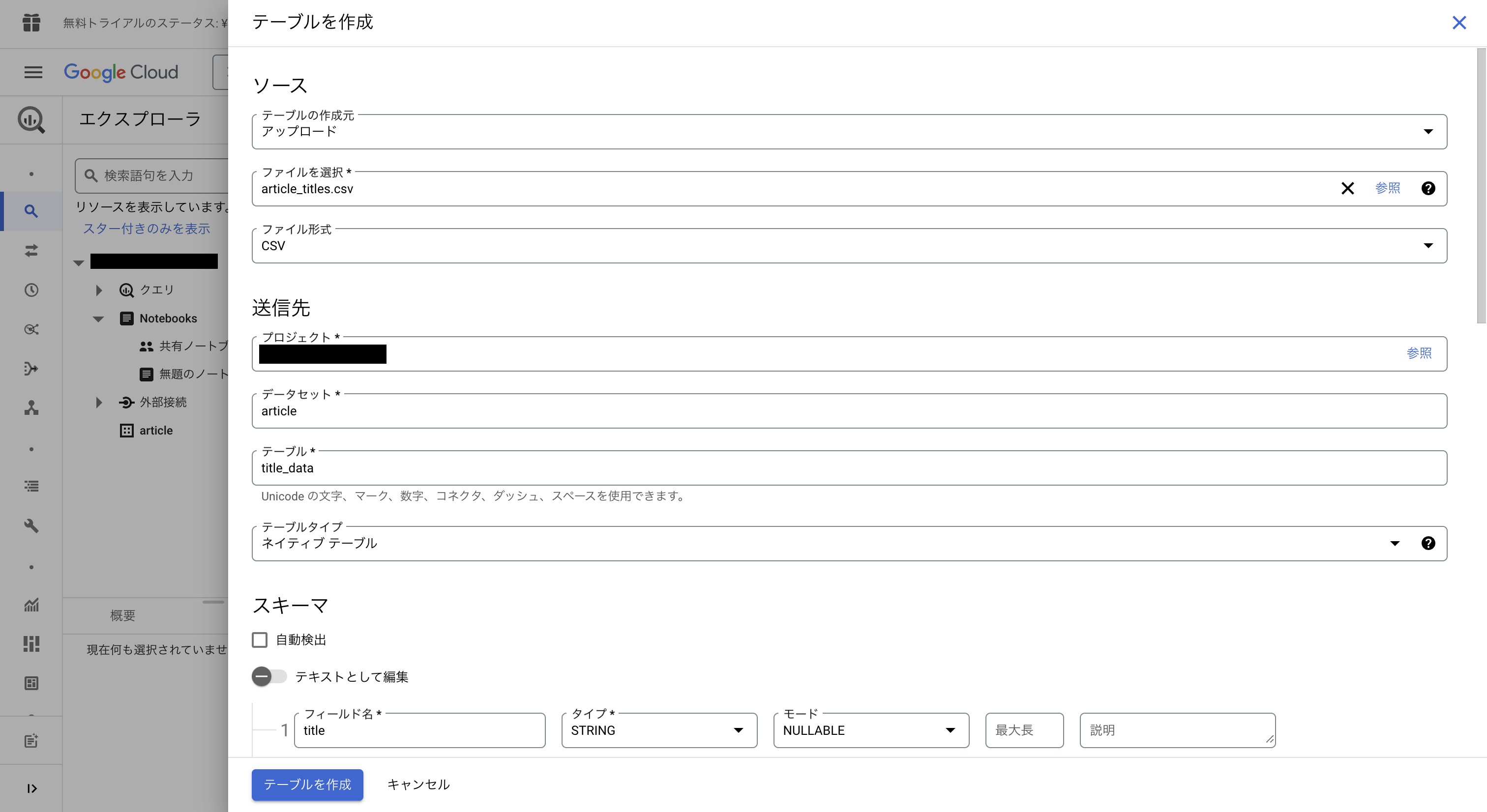
今作ったデータセットの横の3つの点のところを押し、デーブルを作成を選択します。
テーブルの作成元はアップロードを選び、先ほどダウンロードしたcsvファイルを選択します。
テーブルネームを設定します(今回はtitle_data)
スキーマにはtitleと設定。
詳細オプションをの項目を開き、スキップするヘッダー行を1にします。
最後にテーブル作成(青いボタン)を押します。
これで準備完了です。
アップロードしたデータの確認&ベクトル化
それではBigQueryにアップロードしたデータを読み込んでベクトル化してみましょう
前回同様colabで行っていきます。
まずは必要なライブラリのインポートと初期化を行います
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from google.colab import auth from google.cloud import bigquery import vertexai from vertexai.language_models import TextEmbeddingModel import pandas as pd import numpy as np import json import os auth.authenticate_user() PROJECT_ID = '{自分のプロジェクトIDを入れてください}' LOCATION = 'us-central1' vertexai.init(project=PROJECT_ID, location=LOCATION) client = bigquery.Client(project=PROJECT_ID) |
先ほど設定したデータセット名とテーブル名も変数で用意します。
|
1 2 |
dataset_name = 'article' table_name = 'title_data' |
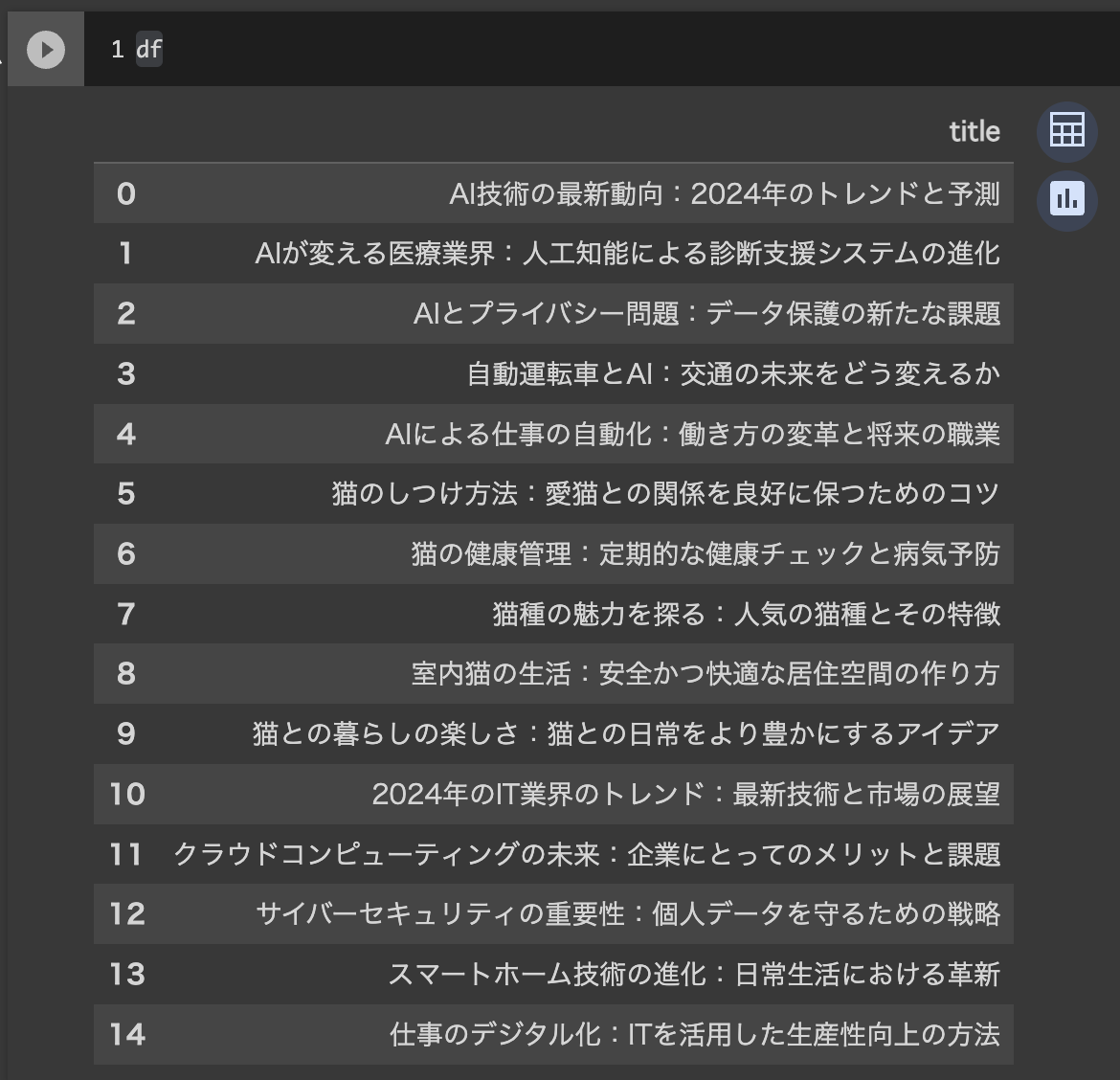
SQLクエリを書いてBigQueryから記事タイトルデータを読み込んでみましょう。
|
1 2 |
query = f'select title from `{PROJECT_ID}.{dataset_name}.{table_name}`' df = client.query(query).result().to_dataframe() |
うまくできていれば以下のようになると思います。
次に、Embeddingに使うモデルを用意します。
今回はPaLM2のgekkoの最新バージョンを利用します。
|
1 2 |
MODEL_NAME = "textembedding-gecko-multilingual@latest" model = TextEmbeddingModel.from_pretrained(MODEL_NAME) |
記事タイトルをベクトル化します。
|
1 |
df['embedding'] = [embeding.values for embeding in model.get_embeddings(df['title'].to_list())] |
うまくいけば、以下のようになっています。

これで、記事タイトルのベクトル化は完了しました。
毎回ベクトル化するのも面倒なので、embeddingの結果もBigQueryにアップロードしてしまいましょう。
BigQueryはリスト型の要素をアップロードできないので、embeddingの結果を文字列に直してからアップロードします。
|
1 2 3 4 5 |
df['embedding_str'] = df['embedding'].apply(str) emb_tabel_name = f'{table_name}_embedding' destination = f'{dataset_name}.{emb_tabel_name}' df[['title', 'embedding_str']].to_gbq(destination, project_id=PROJECT_ID, if_exists='replace') |
BigQueryの画面でも新たにテーブルが作られているのを確認できると思います。
与えられた記事タイトルに近いものをレコメンドする
それでは、記事タイトルを入力するとそれと意味合いが近い記事タイトルをレコメンドするアルゴリズムを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import ast def calc_simu(vector_a, vector_b): array_a = np.array(vector_a) array_b = np.array(vector_b) # コサイン類似度の計算 cosine_similarity = np.dot(array_a, array_b) / (np.linalg.norm(array_a) * np.linalg.norm(array_b)) return cosine_similarity # target_sentence: 対象となる記事タイトル # database_df: 記事タイトルとそのベクトルが保存されているdataframe # recommend_num:いちどにレコメンドしたい記事数 def recomend_article(target_sentence, database_df, recomend_num): target_emb = model.get_embeddings([target_sentence])[0].values database_df['score'] = database_df['embedding_str'].apply(lambda x: calc_simu(target_emb, ast.literal_eval(x))) return database_df.sort_values('score', ascending=False).head(recomend_num) |
完成です。単純ですね。
先ほどから利用しているデータテーブル「df」を利用しても良いのですが、BigQueryにデータが上がっているのかの確認も兼ねて、読み込んでみます。
|
1 2 |
query = f'select title, embedding_str from `{PROJECT_ID}.{dataset_name}.{emb_tabel_name}`' database_df = client.query(query).result().to_dataframe() |
それでは結果を見てみます。
recomend_article()に検索対象の記事のタイトルとBigQueryから読み込んだベクトルデータ、レコメンドしたい数を入力すると結果が確認できます。
ためしに、「AIと人間の共存:技術革新が生活にもたらす変化」といった記事のタイトルに対してどういったものがレコメンドされるのかを見てみます。
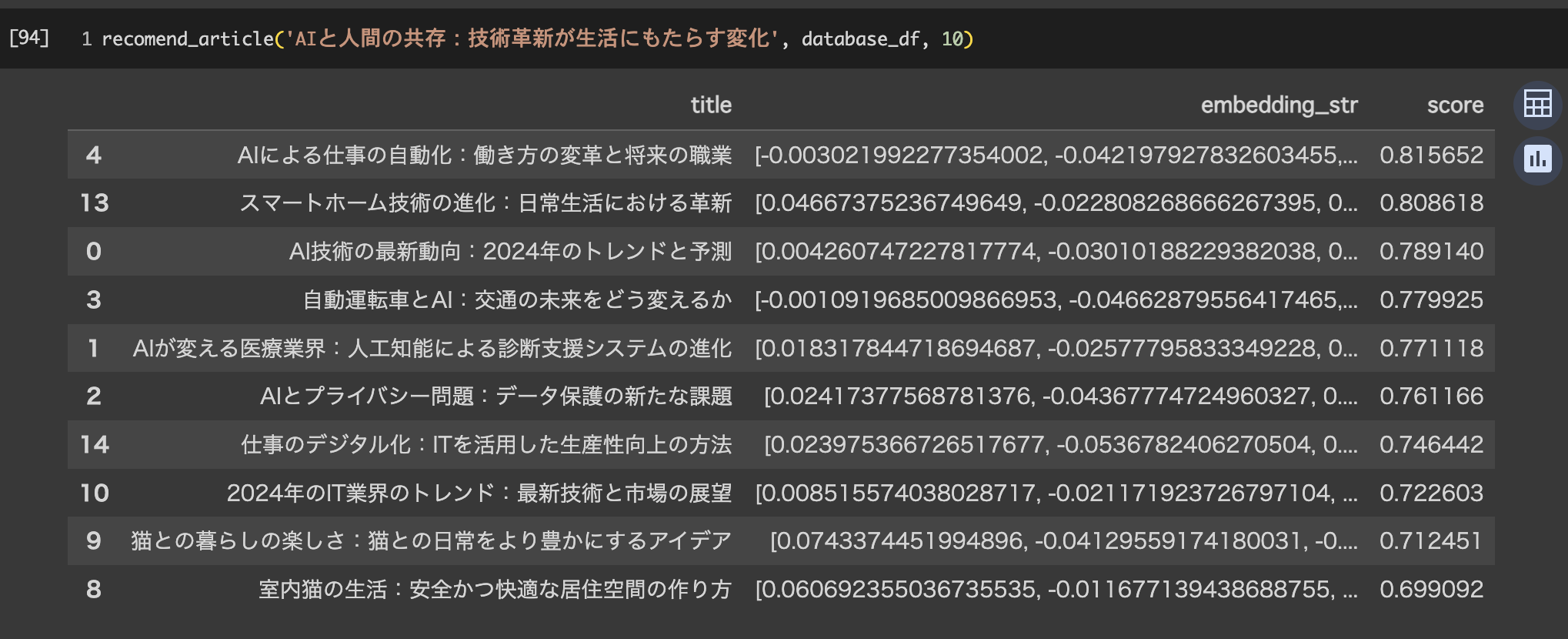
結果は上から類似度が高い順に並ぶようにしています。
scoreは与えた記事タイトルとの類似度を表したものです。(-1 ≦ score ≦ 1)
情報技術が生活に与える影響 > AI > IT > 猫 といった感じでレコメンドされています。
他にもいくつか適当に確認してみます
データベースに無いものに焦点を当ててみます。
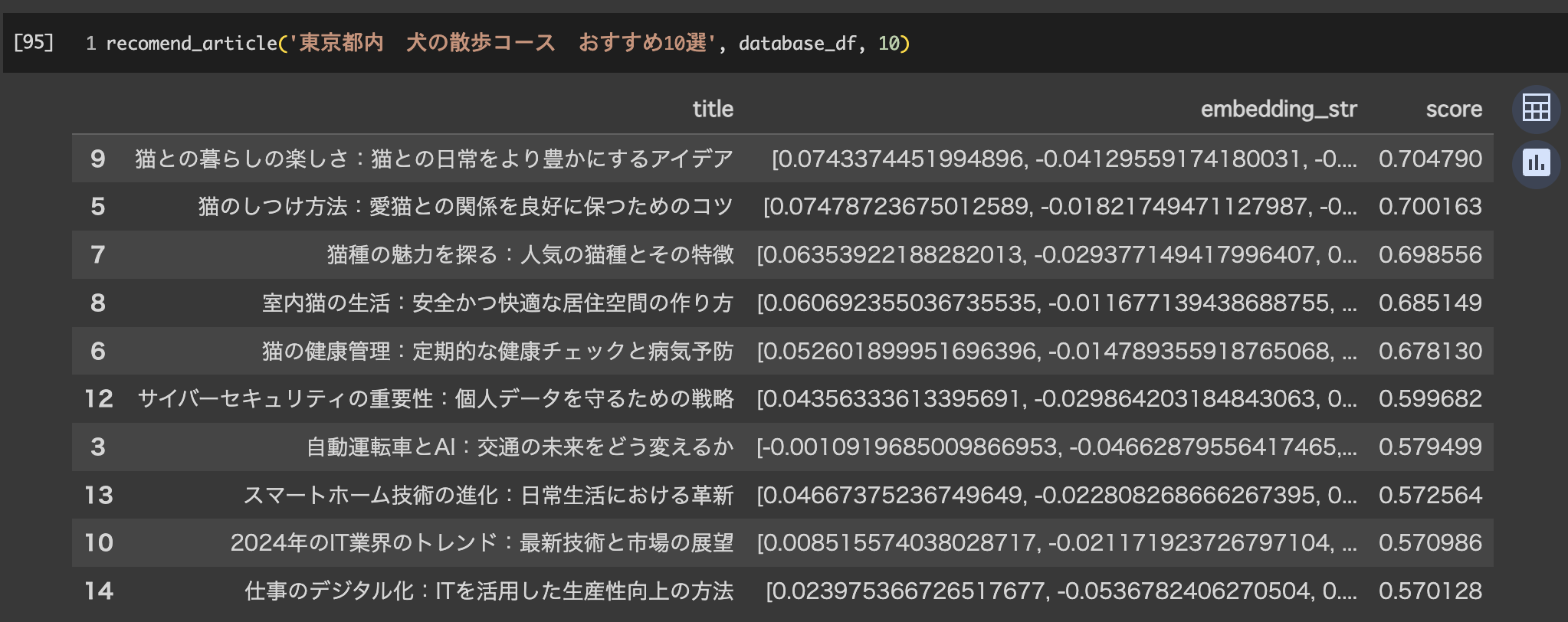
scoreは全体的に下がっていますが、ペット関連として猫の記事が出ています。
他にも
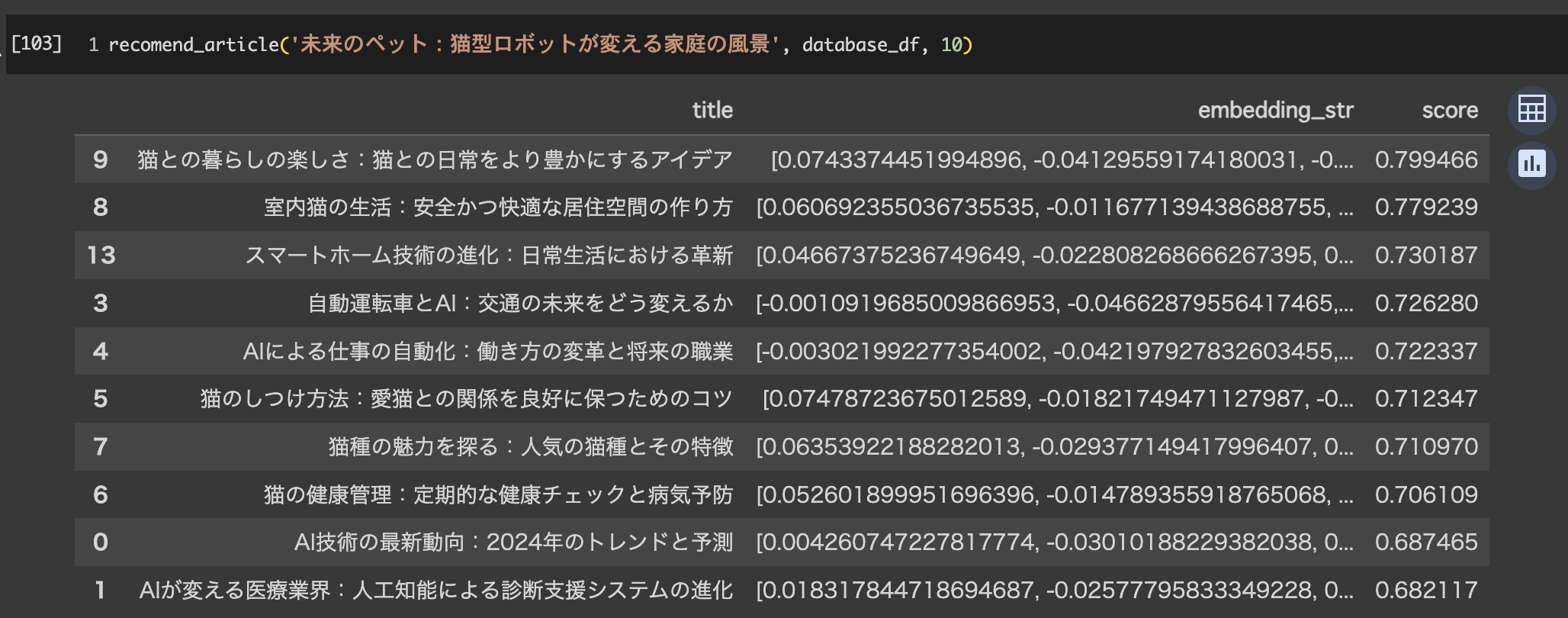
猫についての記事と情報技術と人間の生活といったものが上位に来ています。
おわりに
今回はGCPを利用し、記事データをBigQueryで管理、ベクトル化もPaLMで行い、記事タイトルベクトルに対するベクトル検索を行いました。(セマンティックサーチなどとも呼ばれます)
記事タイトルの代わりに歌詞データを利用すれば、気になったフレーズを入力するとその意味合いが含まれる歌をレコメンドするシステムなども作れたりします。
ベクトルの次元数が多く、文のベクトルの表現空間が広くなっているので、単語を入れて検索するといった使い道よりも、ある程度詳しい内容がある文からある程度詳しい文を検索するといった使い方で真価を発揮すると思います。
また、今回は、ベクトル化の部分やベクトル検索の部分を自分で行いましたが、BigQueryではクエリを書いて保存しているデータをベクトル化することができたり、ベクトル化したデータをvertexAIのベクトル検索にアップロードすると記事をPOSTするとレコメンド記事を返してくれるAPIのようなものが楽に作成できます。
次回はその辺に触れて書いていこうと思います。
ここまで読んでくださりありがとうございました。
明日はM.Nさんによる「Four Keysの仕組みを深掘りする」です。
引き続き、GMOアドマーケティング Advent Calendar 2023 をお楽しみください!
■採用ページはこちら!
■GMOアドパートナーズ 公式noteはこちら!


