最近花粉気味のCTO室のHadoopエンジニアのJ.Nです。
2月18日 Developers Summit 2016 でApache Sparkを使ったリコメンドシステムの研究成果について発表してきました。
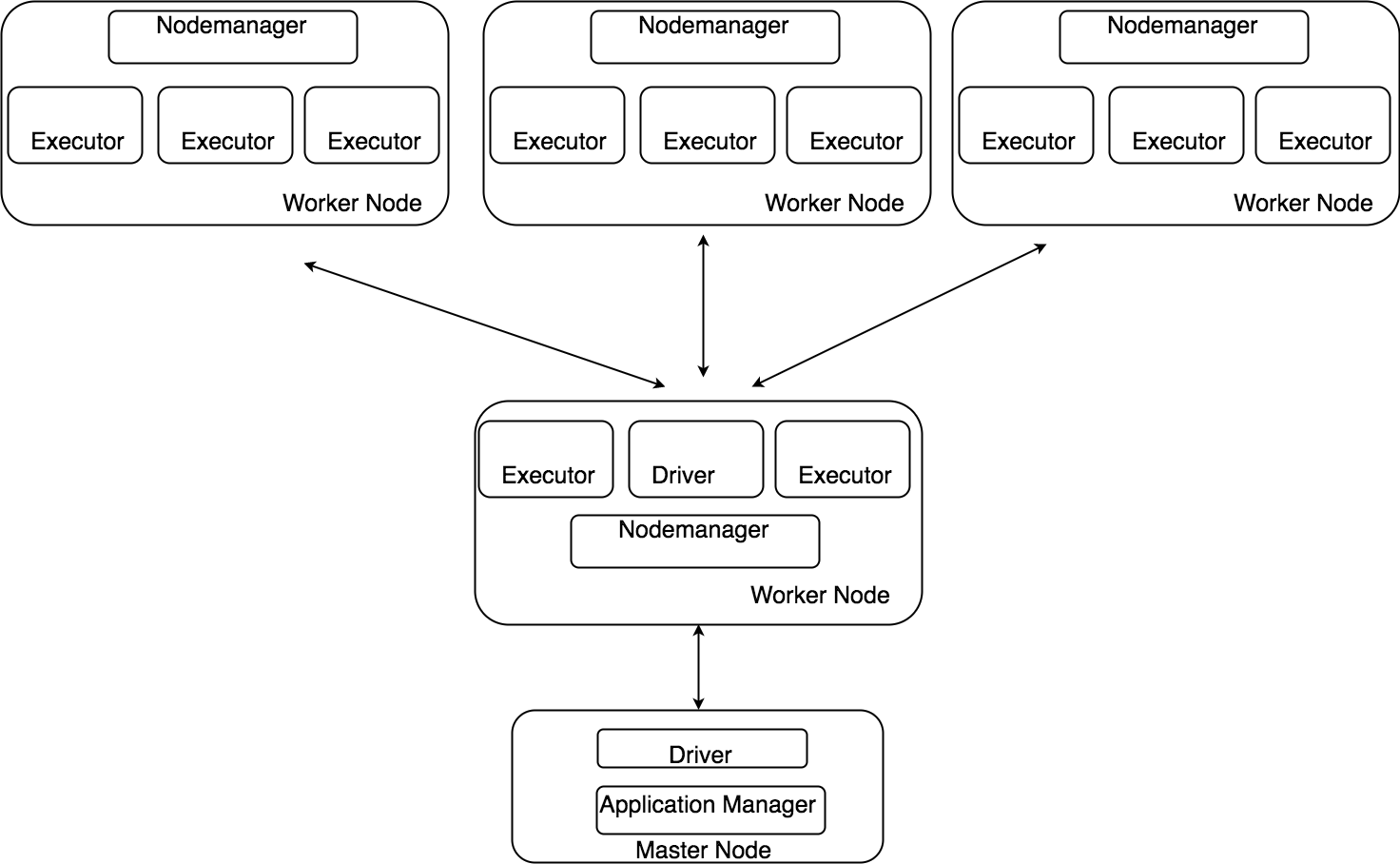
Apache Sparkはインメモリの並列分散処理基盤です。以前の記事にも解説があります。
最近GMOアドパートナーズグループのエンジニア内では熱い分野です。


デブサミで登壇するのは初めてなので緊張しました。

Spark Streamingを使って「NHKのつぶやきビッグデータのクローンを作ってみた」というテーマでお話しました。
またクローンだけでは面白くないので、内部でSpark(集計) -> Kafka(レポート結果の受送信) -> Ruby (集計に基づくレコメンド)
というシステムを構築しました。


資料はスライドシェアにもアップしています。
GMOアドパートナーズのノウハウをエンジニア界隈に還元し発展していくためにも今後こういったイベントや勉強会には定期的に参加したいと思っていますので、面白い勉強会を開催される会社さんがいれば是非お声かけください。