
はじめに
GMO NIKKOの吉岡です。
みなさん、生成AIは活用してますか?
ChatGPTに始まり、Claude3やGeminiなど、実用的なAIがどんどん出てきてますね。
自分も使ってはきましたが、課金が気になってしまいます。
これではサービスに組み込むことは難しいですよね。
そのためローカルで動くLLMを追ってきましたが、今年に入って実用的な日本語を返すことができるモデルがいくつか出てきているので、サーバー構成からインストール方法、LLMの起動まで紹介しようと思います。
ローカルLLMを動かす上で一番重要なのはGPUのVRAMです。
LLMは7B、13B、70Bモデルが多いですが、量子化しない場合、必要なVRAM容量は動かすモデルの大体2倍なので、13Bモデルでは26GのVRAMが必要です。
NVIDIAのGPUを使ったCUDAが前提になっているのですが、一般向けでは24Gモデルが最大で、それ以上必要であれば複数台構成にする必要があります。
マザーボードもそれに合ったものを選ばなければいけないので、サーバー構成も重要です。
サーバー構成
CPU:Core i5-13500T 14core 20thread 1.2GHz TDP35W
マザーボード:PRIME H770-PLUS D4
GPU:NVIDIA RTX 3090 24G
GPU:NVIDIA RTX 3060 12G
Memory: DDR4 32G
電源:Corsair HX1200
CPU
サーバーとして動かすので、CPUに関してはTDPが低く、仮想化しやすいスレッド数の多いものを選んでます。CPUの種類やチップセットに合ったマザーボードを選択する必要があります。
マザーボード
はじめに動かそうとしていたGPUがNVIDIAのサーバー用GPUだったため、BIOSからResizable BARやAvobe 4G Decodingなどの設定ができる新しめのマザーボードを用意する必要がありました。
また、高性能なGPUは複数スロットを占有してしまうため、複数GPUに対応したスロットの多いマザーボードだけでなく、余裕のあるケースも必要です。
GPU
GPUはCUDAの使えるNVIDIA製でメモリの多いものを選びます。
RTX3090は10万円以上するのでNVIDIAのサーバー用GPUで代用しようとしてましたが、頑張って動かしてもGPUパススルーができなかったり、高温になってソフトが落ちたりと多くの問題が発生して諦めました。
Memory
メモリが少ないとLLMロードのタイミングで落ちるので、GPUメモリと同じくらいあると良さそうです。
電源
電源は1000W以上で、電源効率の良いものを選んでおけば問題なさそうです。

準備
OS:Ubuntu Server 24.04 LTS
ドライバ:nvidia-driver-535-server
Ubuntu Server 24.04 LTSインストール
以下のページからUbuntu Server 24.04 LTSをダウンロードしてインストールします。
Ubuntuを入手する | Ubuntu | Ubuntu
インストール後、GPUが物理的に認識されているか確認
|
1 |
lspci -nn | grep -i nvidia |

nouveauドライバ無効化
LinuxでNvidiaのGPUを使うためにnouveauドライバを無効化します。
|
1 2 3 4 |
echo 'blacklist nouveau' | sudo tee -a /etc/modprobe.d/blacklist-nouveau.conf echo 'options nouveau modeset=0' | sudo tee -a /etc/modprobe.d/blacklist-nouveau.conf cat /etc/modprobe.d/blacklist-nouveau.conf sudo update-initramfs -u |
NVIDIA Driverインストール
|
1 2 3 4 |
sudo add-apt-repository ppa:graphics-drivers/ppa sudo apt update sudo apt install -y nvidia-driver-535-server sudo reboot |
nvidia-smiコマンドでGPU毎の温度や消費電力、使用メモリが表示できます。
|
1 |
nvidia-smi |

cudaインストール
Python関連のパッケージをインストールしておきます。
|
1 |
sudo apt install wget git git-lfs python3 python3-venv python-is-python3 |
以下のURLからCUDAインストール
CUDA Toolkit Archive | NVIDIA Developer
上記URLからバージョンとOSを選択すればインストール用コマンドが表示されますが、2024年5月30日現在、ubuntu24が選択できないため、コマンドからインストールします。

|
1 2 |
sudo apt install nvidia-cuda-toolkit nvcc -V |
LLM
LLM:microsoft/Phi-3-medium-128k-instruct · Hugging Face 14B
LLMは14BのPhi-3-Mediumを使ってみます。
Phi-3はSLMと呼ばれるみたいですが、14BであればLLMに含めてもいいのではないでしょうか。
git clone
フォルダを作成し、huggingfaceからcloneします。
大きなファイルがあるため、git lfsが必要です。
|
1 2 3 4 |
mkdir llm cd llm git lfs install git clone https://huggingface.co/microsoft/Phi-3-medium-128k-instruct |
パッケージインストール
venvでPython環境を分けてインストールします。
|
1 2 3 |
python -m venv venv source venv/bin/activate pip install torch torchvision torchaudio accelerate transformers <span class="s1">flash_attn</span> |
サンプルコード実行
まずはサンプルコードを実行してみます。
vi sample.pyとして以下を保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import torch from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline torch.random.manual_seed(0) model_id = "Phi-3-medium-128k-instruct" model = AutoModelForCausalLM.from_pretrained( model_id, device_map="cuda", torch_dtype="auto", trust_remote_code=True, ) tokenizer = AutoTokenizer.from_pretrained(model_id) messages = [ {"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"}, {"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."}, {"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"}, ] pipe = pipeline( "text-generation", model=model, tokenizer=tokenizer, ) generation_args = { "max_new_tokens": 500, "return_full_text": False, "temperature": 0.0, "do_sample": False, } output = pipe(messages, **generation_args) print(output[0]['generated_text']) |
以下コマンドで実行します。
|
1 |
python sample.py |

エラーになってしまいました。
OutOfMemoryと言われているので、VRAMが足りないみたいです。
2台合わせてVRAM36Gあるので足りないことはないと思うのですが、nvidia-smiコマンドで確認します。
watch nvidia-smiコマンドで2秒間隔で確認できます。

どうもRTX3090にしかロードされていないようです。
コードを変更して、複数台構成に対応させてみます。
以下のようにdevice_map=”cuda”をdevice_map=”auto”に変更します。
|
1 2 3 4 5 6 |
model = AutoModelForCausalLM.from_pretrained( model_id, device_map="auto", torch_dtype="auto", trust_remote_code=True, ) |
メモリロードはどうでしょうか?
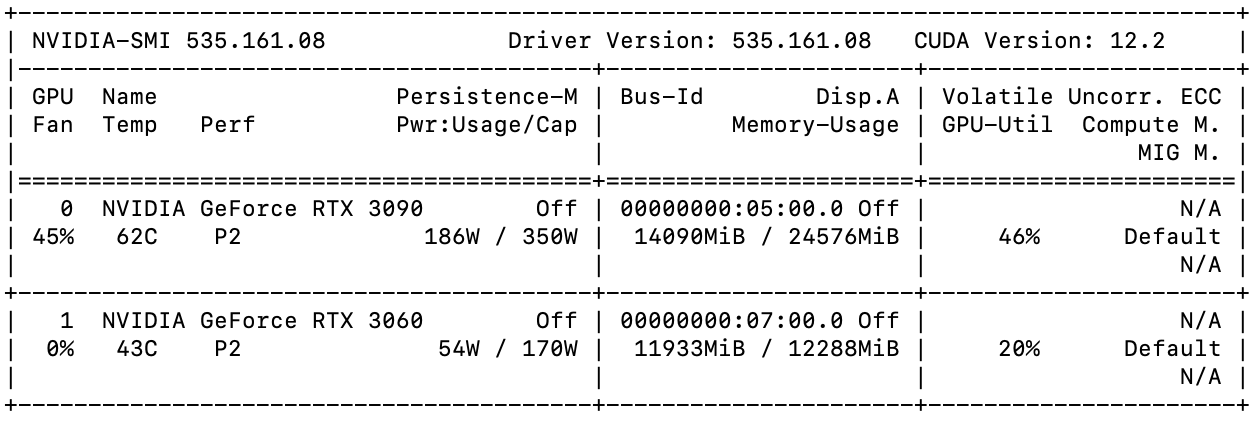
ちゃんと分散して読み込まれているようです。

2x + 3 = 7の方程式も説明しながら解いてくれました。
日本語で回答
日本語で回答してもらうようにプロンプトを追加して、再度実行します。
|
1 |
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation? 日本語で回答してください。"} |

ちゃんと日本語で説明して正しい回答をしてくれましたが、日本語での回答:と同じ内容を繰り返してしまってます。おそらく質問が英語だからだと思います。
計算問題
プロンプトを日本語のみに変更して実行してみます。
|
1 |
{"role": "user", "content": "時速500kはマッハいくつですか?計算式など詳細を日本語で回答してください。"} |

今度は日本語の回答のみを返してくれました。
こんな計算までできるんですね。
複数情報を与えて計算
情報を与えて営業キャッシュフローマージンを計算してみます。
|
1 |
{"role": "user", "content": "NVIDIA社の2025会計年度第1四半期売上高は260億ドルで、営業キャッシュフローは153億ドルです。営業キャッシュフローマージンはいくつですか?計算式など詳細を日本語で回答してください。"} |

営業キャッシュフローマージンという内容を理解して、与えた情報を元に割合まで出してくれました。
GPUの需要が高いのですごい利益になってますが、一般向けGPUはもう少し安くしてほしいものです。
まとめ
無事サーバーでLLMを動かすことができました。
Phi-3-Mediumは適当に選びましたが、日本語の回答精度も高く、計算もできるLLMがローカルで動かせるのに驚きました。
今回はサンプルを動かすだけなので、毎回LLMを読み込み、回答まで1分近くかかってしまってますが、APIサーバーとして動かしている時は数秒で返すことができてます。
GPUが高価なので動かすハードルは高いですが、ローカルで動作する環境は便利なので、興味ある方はぜひチャレンジしてみてください。
