こんにちは。GMOアドマーケティングのN.Sです。
弊社ではビッグデータを入出力する際に一部Cloud Dataflow(以下Dataflow)を使っています。
読み込むファイルが2つあった場合、それらをインプットする方法が分かるまで結構苦戦したため、備忘録的に記載します。
環境
CloudFunctions version: 1.0.0
Dataflow SDK version: 2.4.0
ドキュメント
Dataflowバージョン2.X以上はApacheBeamを基にしているため、そちらのドキュメントを読む。
apache beamの副入力に関するドキュメント
Side Inputsの項目を読むと、副入力をPCollectionViewに変換し、withSideInputsメソッドを使って同一パイプラインにマージするようです。
処理の流れ
今回はサンプルとして、生徒のテスト結果から、合格者のみ出力するプログラムを作ります。
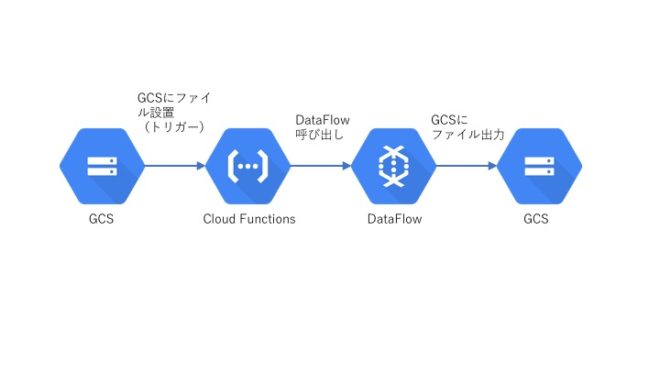
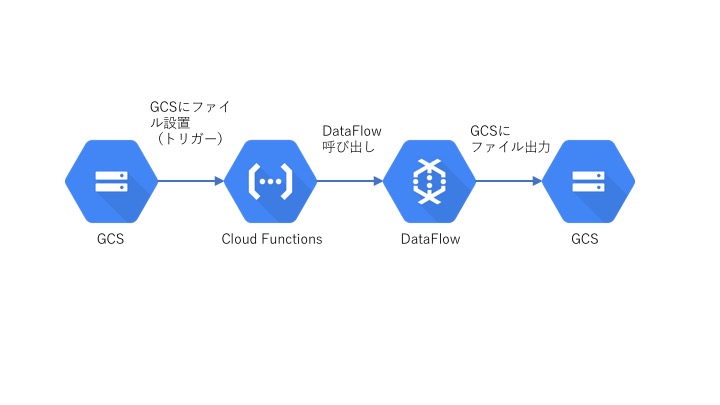
①Google Cloud Strage(以下GCS)にテスト結果ファイルを置く。
②CloudFunctionsが①をトリガーにして起動。Dataflowを呼び出す。
③Dataflowにてファイル読み込み・フィルター処理・書き込みを行う。
GCS→CloudFunctions→Dataflow→GCS
Dataflowで読み込むファイルは2種類(主入力と副入力)
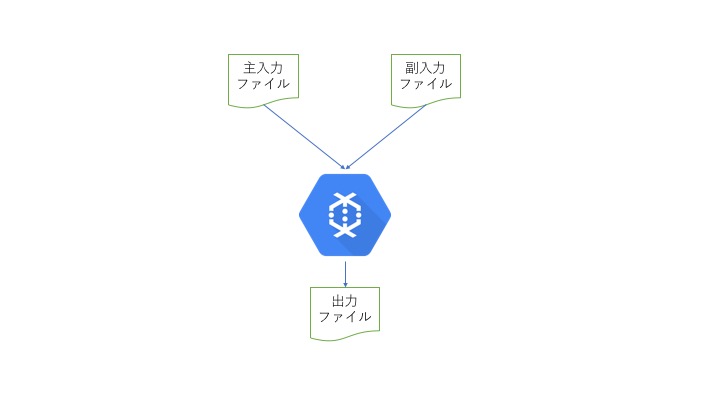
※上記二枚の画像は当社が作成したもの
用意するファイル
dataflow_test_20180309.csv(生徒のテスト結果)
|
1 2 3 |
Alisa,100 Bob,50 Cathy,30 |
sub.txt(合格ライン定義)
|
1 |
40 |
Cloud Functions
ここではGCSに置かれたファイル名を取得し、Dataflowにパラメータとして渡して実行している。
index.js
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
const { google } = require('googleapis'); exports.makeFile = function (event, callback) { const PROJECT_ID = 'XXXXXXXX'; const file = event.data; const filename = file.name; if (!filename.match(/^dataflow_test_/)) { console.log('not target file.'); callback(); return; } // 日付を抜き出す d = filename.match(/dataflow_test_(\d+).csv/); const date = d[1]; // dataflowを呼ぶ google.auth.getApplicationDefault(function (err, authClient, projectId) { if (err) { throw err; } if (authClient.createScopedRequired && authClient.createScopedRequired()) { authClient = authClient.createScoped([ 'https://www.googleapis.com/auth/cloud-platform', 'https://www.googleapis.com/auth/userinfo.email' ]); } const dataflow = google.dataflow({ version: 'v1b3', auth: authClient }); dataflow.projects.templates.create({ projectId: PROJECT_ID, resource: { parameters: { inputFile: `gs://${file.bucket}/${file.name}`, }, jobName: `sample-job-${date}`, gcsPath: 'gs://sample-staging01/template/TestTemplate' } }, function (err) { if (err) { console.error(err); } callback(); }); }); console.log("DataFlow end."); callback(); }; |
Dataflow
CloudFunctionsから指定されたファイルと副入力ファイル(sub.txt)を読み込み、
両ファイルをマージした結果をGCSに出力する(output.csv)。
Main.java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
import org.apache.beam.sdk.Pipeline; import org.apache.beam.sdk.io.TextIO; import org.apache.beam.sdk.options.*; import org.apache.beam.sdk.transforms.DoFn; import org.apache.beam.sdk.transforms.ParDo; import org.apache.beam.sdk.transforms.View; import org.apache.beam.sdk.values.PCollection; import org.apache.beam.sdk.values.PCollectionView; public class Main { private static final int INDEX_SCORE = 1; public static interface MultipleSourcesOptions extends PipelineOptions { @Description("Path of the file to read from") ValueProvider getInputFile(); void setInputFile(ValueProvider value); } public static void main(String[] args) { MultipleSourcesOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(MultipleSourcesOptions.class); String subFilePath = "gs://sample-bucket01/sub.txt"; String outputPath = "gs://sample-bucket01/output.csv"; Pipeline pipeline = Pipeline.create(options); // 主入力 PCollection inputMain = pipeline .apply(TextIO.read().from(options.getInputFile())); // 副入力 PCollection inputSub = pipeline .apply(TextIO.read().from(subFilePath)); // 副入力を主入力で扱うため、PCollectionViewに変換する PCollectionView subView = inputSub.apply(View.asSingleton()); // 主入力と副入力をマージ PCollection mergedPCollection = inputMain.apply(ParDo .of(new DoFn<String, String>() { @ProcessElement public void processElement(ProcessContext c) { String line = c.element(); String[] columns = line.split(","); int score = Integer.parseInt(columns[INDEX_SCORE]); // 副入力を取得 int threshold = Integer.parseInt(c.sideInput(subView)); // スコアが40点以上のみ出力 if (score > threshold) { c.output(line); } }}).withSideInputs(subView)); // ファイル書き込み mergedPCollection.apply(TextIO.write().to(outputPath)); // Pipelineを実行 pipeline.run().waitUntilFinish(); } } |
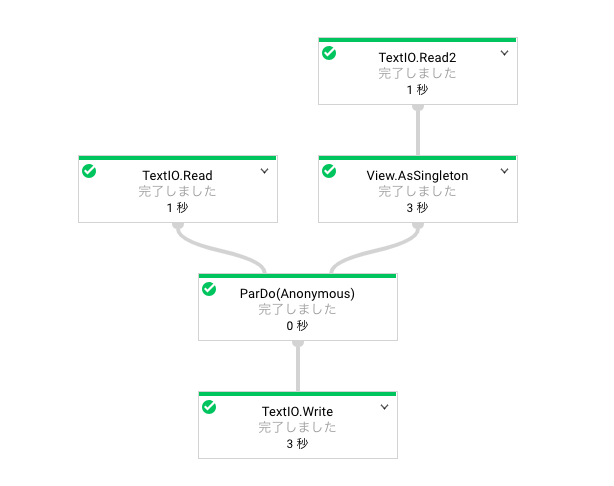
ジョブ詳細
Dataflowジョブの詳細を見ると、2つのリソースを読み込んでで実行していることが分かります。
結果
結果ファイルを見ると、期待通り合格ライン(40点)より高い生徒だけ出力されています。
|
1 2 |
Alisa,100 Bob,50 |
まとめ
以上、かなりシンプルな例ではありますが、副入力を使用したパイプライン作成方法でした。
実際にビッグデータを使う際などは、PCollection<String>をPCollection<TableRow>に置き換えたりする必要があると思いますが、基本的な作りはそんなに変わらないはずです。
Dataflowはまだ情報が少ない(Version2.0以降は特に)状況ため、見てくださった方にわずかでも役立てれば幸いです。



2019年2月12日
[…] 参考: Cloud Dataflowで複数リソースを読み込む方法 […]