
はじめに
GMOアドマーケティングのS.Sです。
プロダクトに機能追加などを行った時に、プロダクトの各種指標にどのような影響があったか簡単に調べたいことがあります。
そこで今回はpandasを使って時系列データをふわっと分析する方法についてみていきたいと思います。
データフレームの作成
はじめに分析を行う対象となるダミーデータを用意します。
ダミーデータは二つのグループ(AとB)について、2020-04-01から2020-05の下旬のある日(具体的には記事を書いた日)まで得られているとします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import numpy as np import pandas as pd np.random.seed(0) dates = pd.date_range("2020-04-01", pd.to_datetime("today"), freq="1D") rA = np.random.normal(size=(len(dates),)) vA = [0] for i in range(len(dates)): vA.append(vA[-1] * 0.75 + rA[i]) vA = np.array(vA)[1:] df_A = pd.DataFrame({"date": dates, "group": "A", "value": vA}) rB = np.random.normal(size=(len(dates),)) vB = [0] for i in range(len(dates)): vB.append(vB[-1] * 0.75 + rB[i]) vB = np.array(vB)[1:] df_B = pd.DataFrame({"date": dates, "group": "B", "value": vB}) df = pd.concat((df_A, df_B)) |
例えばここでは前月の1ヶ月間を対象に集計を行いたいとします。
二つの時点の間の日付の列を生成するにはpd.date_range関数を使います。
集計を行った月が5月だとして、pd.offsets.MonthBegin(), pd.offsets.MonthEndを用いると、それぞれ前月の初日と末日を指し示すことができます。
freqではどのような周期で日付を生成するかを指定します。3Dや1Wにすると3日単位や1週間単位の日付も得られます。
|
1 2 3 |
q1 = df.loc[lambda x: x["date"].isin(pd.date_range(pd.to_datetime("2020-05-30").to_period("1M").to_timestamp() + pd.offsets.MonthBegin(-1), pd.to_datetime("2020-05-30").to_period("1M").to_timestamp() + pd.offsets.MonthEnd(-1), freq="1D"))]\ .set_index(["date", "group"]).unstack(-1) |
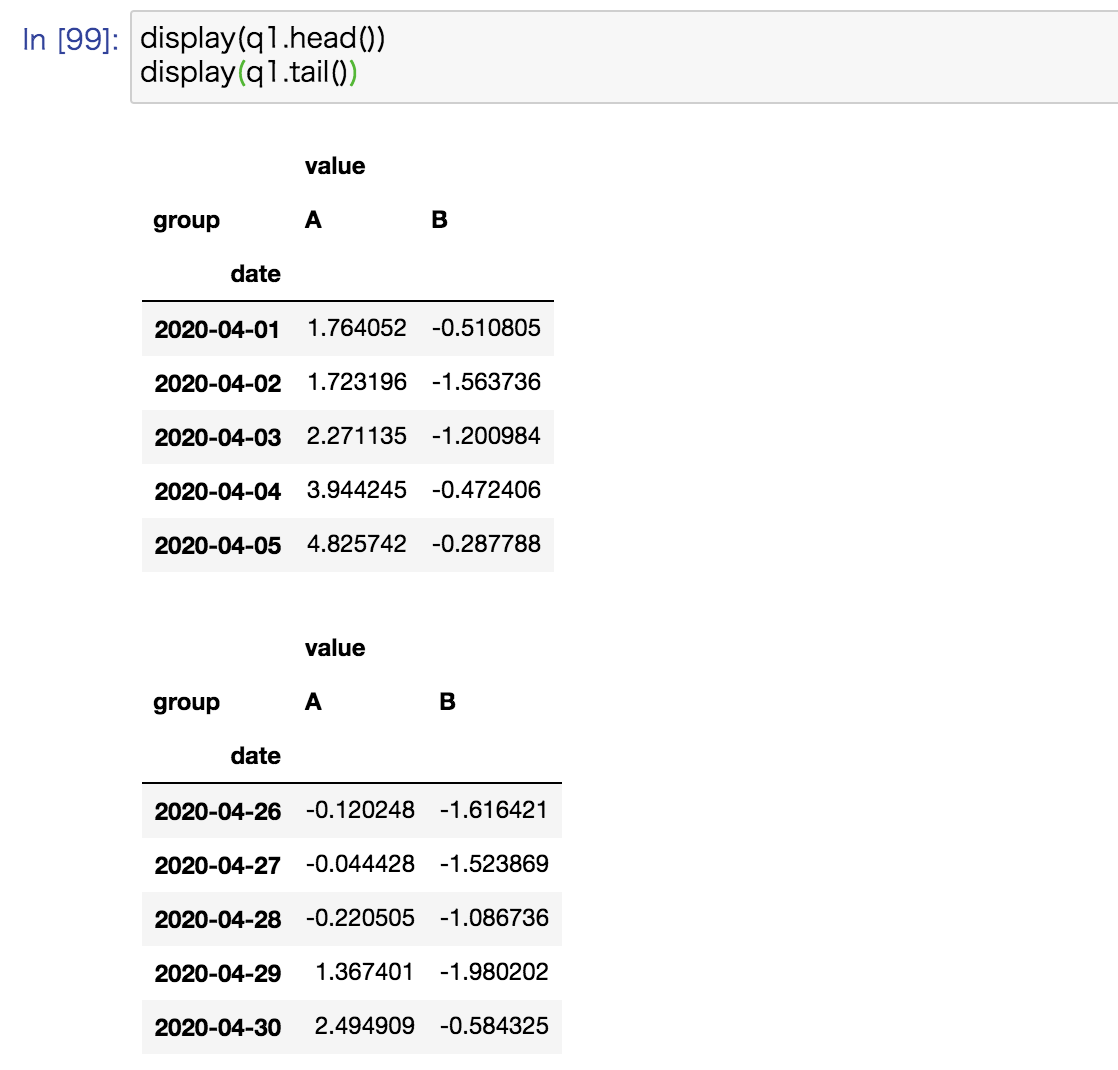
移動平均と標準偏差の計算
次に移動平均と標準偏差を計算してみます。大まかなトレンドはあるものの、日単位でみると変動があってわかりにくいケースだと、少し傾向がつかみやすくなることもあります。
|
1 |
q1.rolling(5).agg(["mean", "std"]).rename_axis(["col", "group", "type"], axis=1).head(10) |
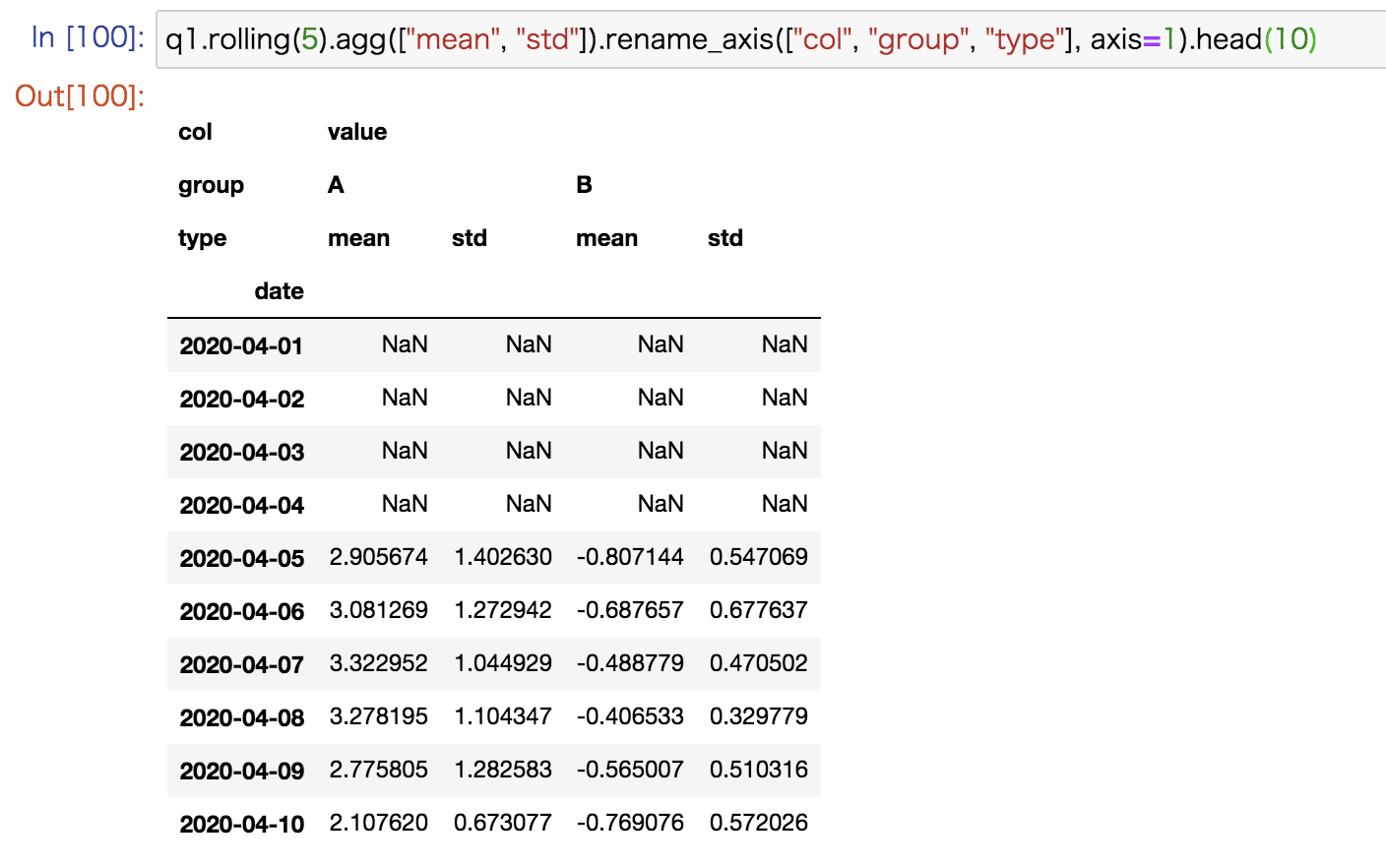
さきほどの移動平均と標準偏差をplotしてみたのが以下の図です。
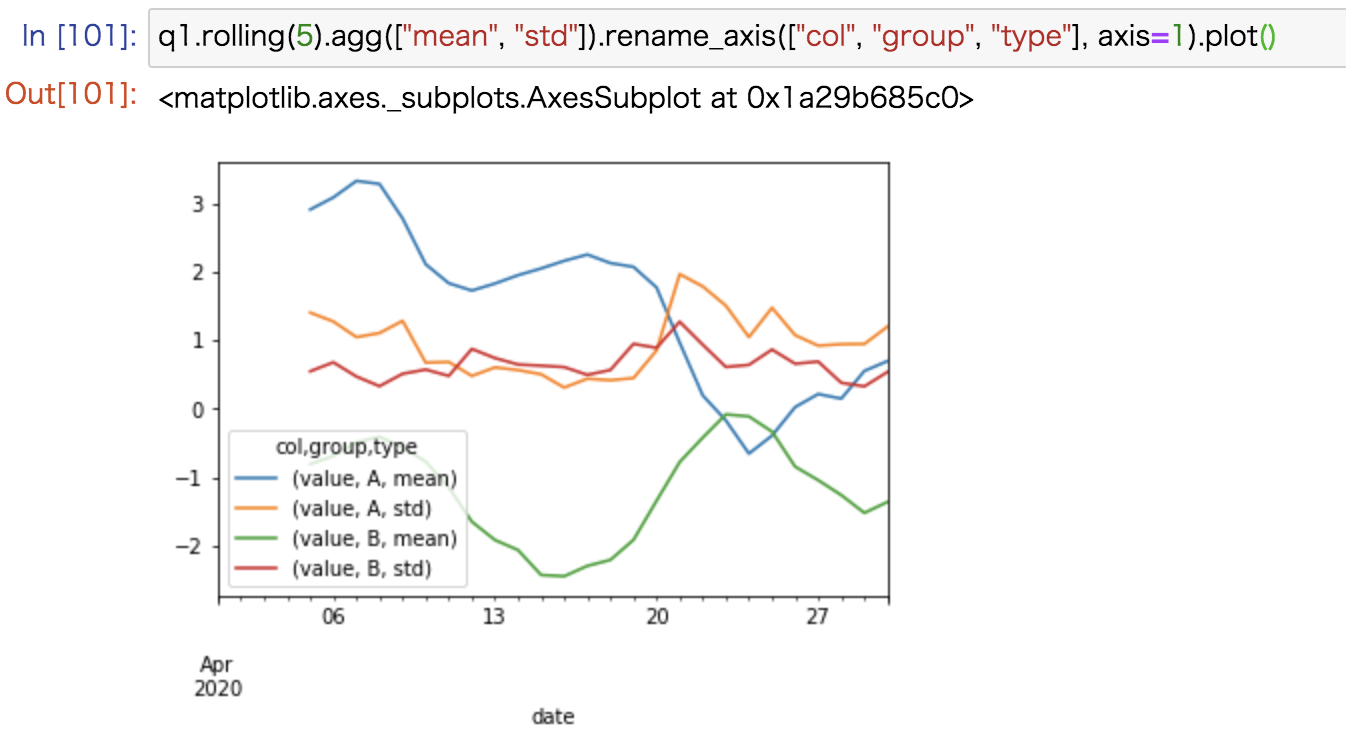
移動平均はwindowをスライドさせながら平均と分散を計算しますが、系列に合わせてwindowを広げていきながら集約を行うこともできます。
ここではさきほどと同様に平均と標準偏差を計算してみました。
|
1 |
q1.expanding().agg(["mean", "std"]).rename_axis(["col", "group", "type"], axis=1).head(10) |
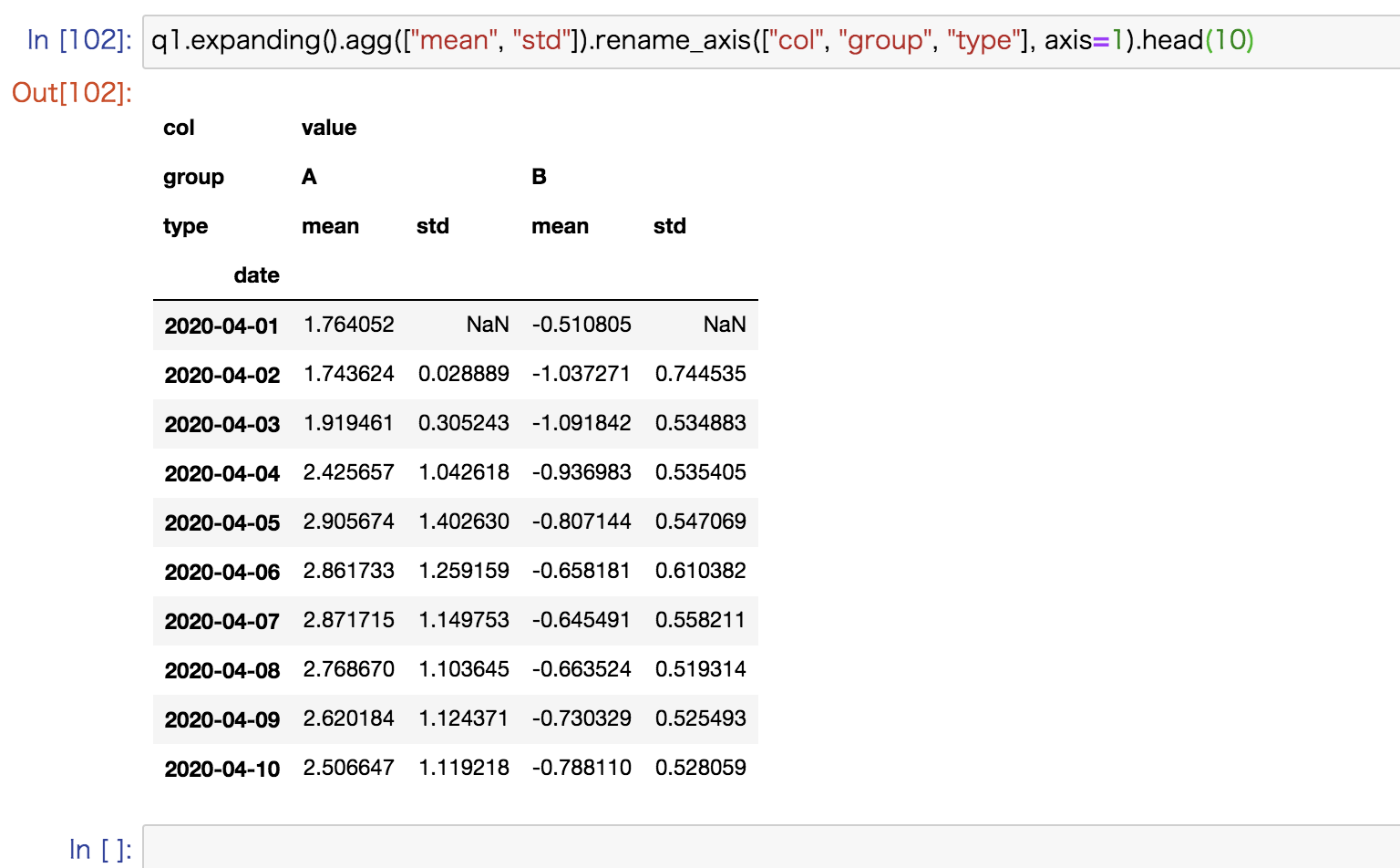
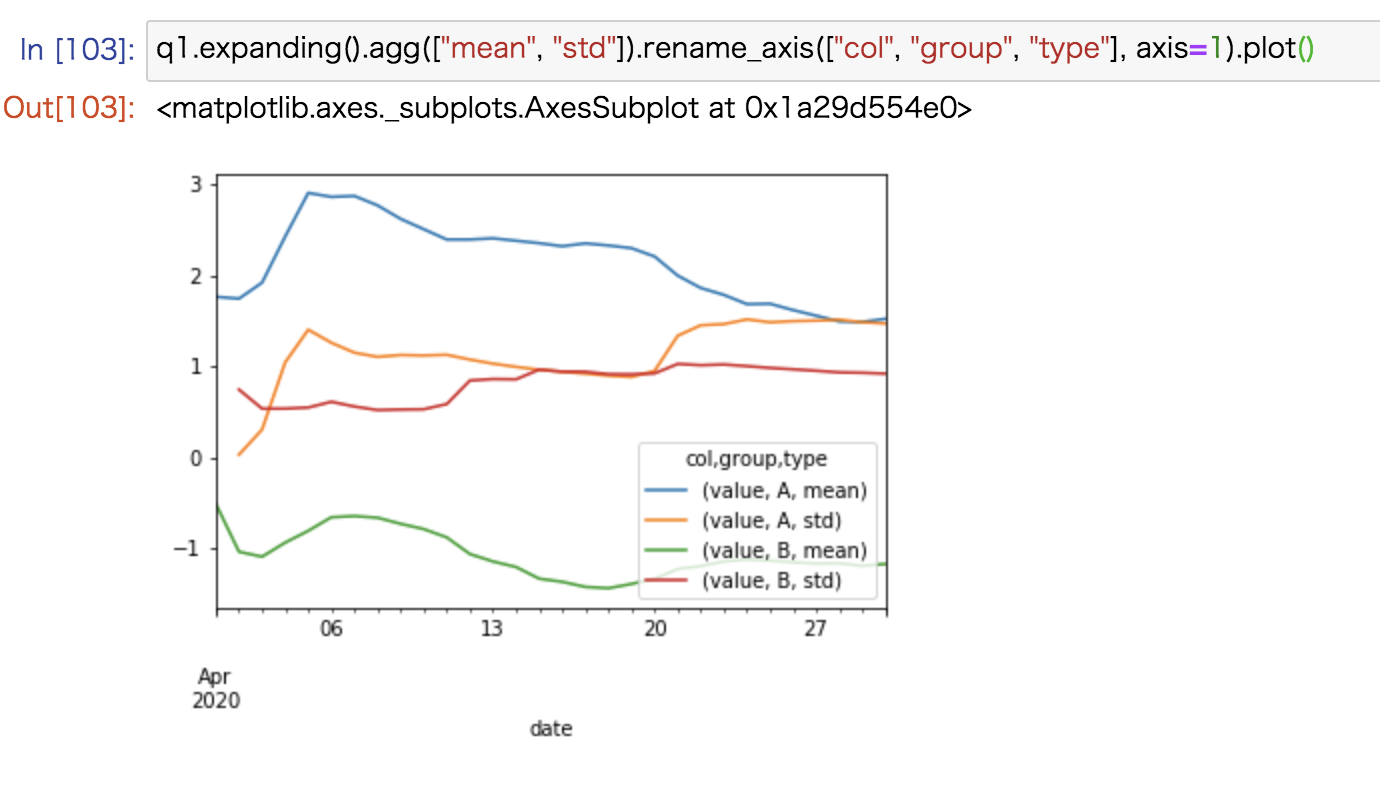
expanding windowを使った場合の平均と標準偏差をplotしたのが以下の図となります。
さきほどの図と比べると時間経過とともに変動が小さくなっています。
集計に使う周期の変更
1日単位の系列データをさらに集計して1週間単位の量に集約することも、resample関数を使うことでできます。
ここでは平均をとってみました。
|
1 2 |
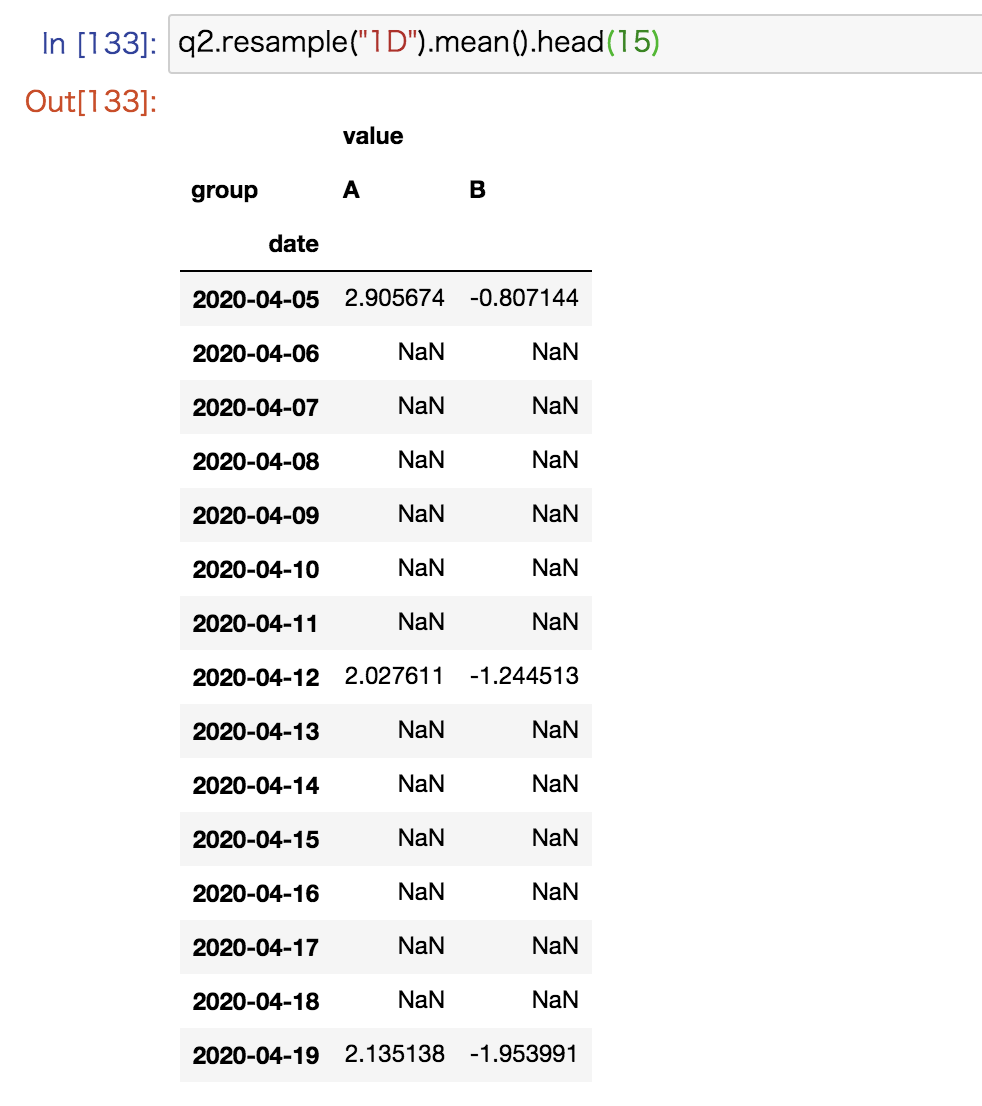
q2 = q1.resample("1W").mean() q2 |

以下のように1週間ごとの周期が粗いデータをそれよりも細かい1日の周期でresampleすると、データがないところはNaNで埋まります。
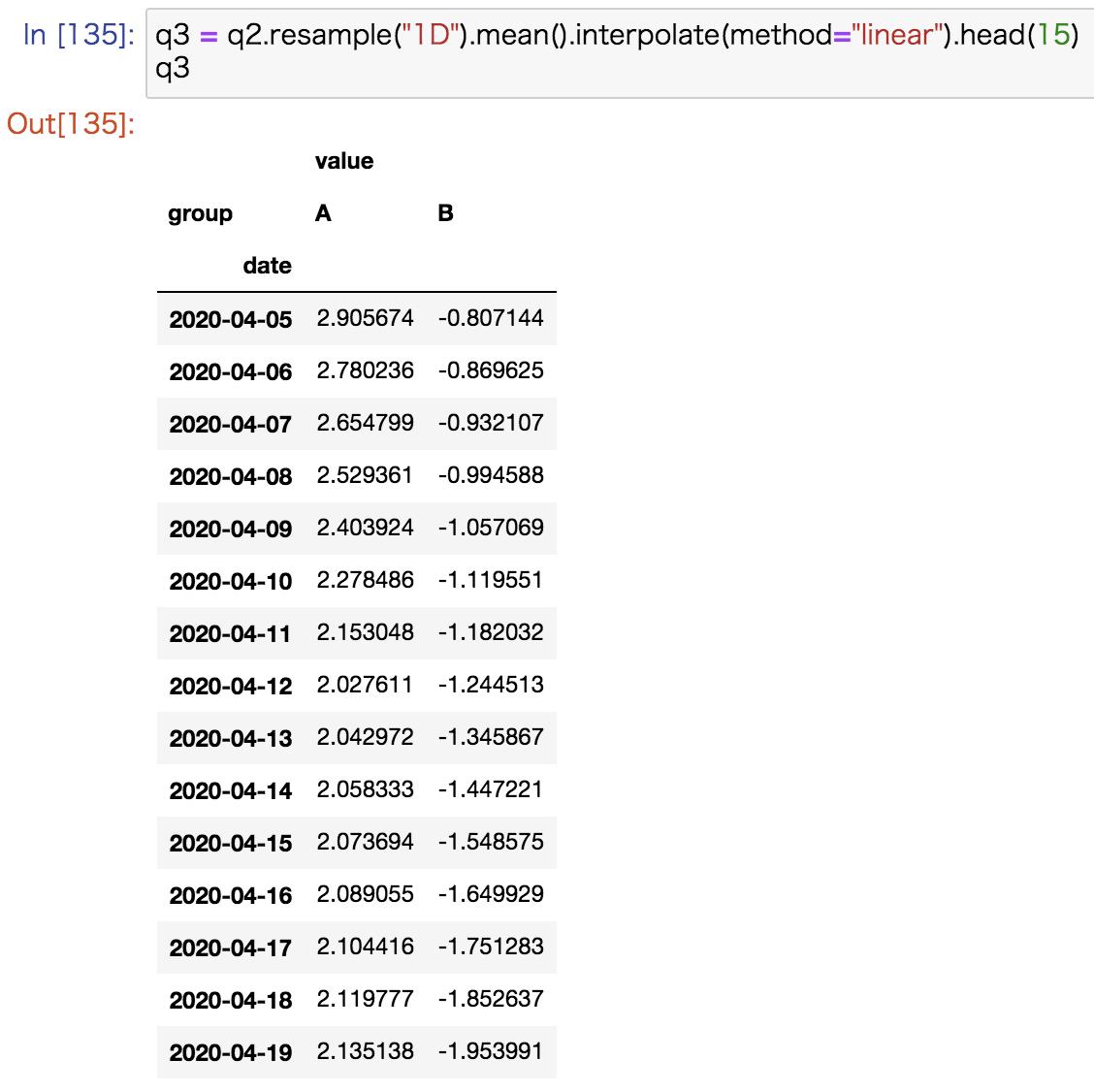
系列の性質によっては補完処理を行って、空の部分をおおまかに埋めることもできます。
methodに指定する引数を変更することで線形以外の補完を行うこともできます。
|
1 2 |
q3 = q2.resample("1D").mean().interpolate(method="linear").head(15) q3 |
その他細かい操作
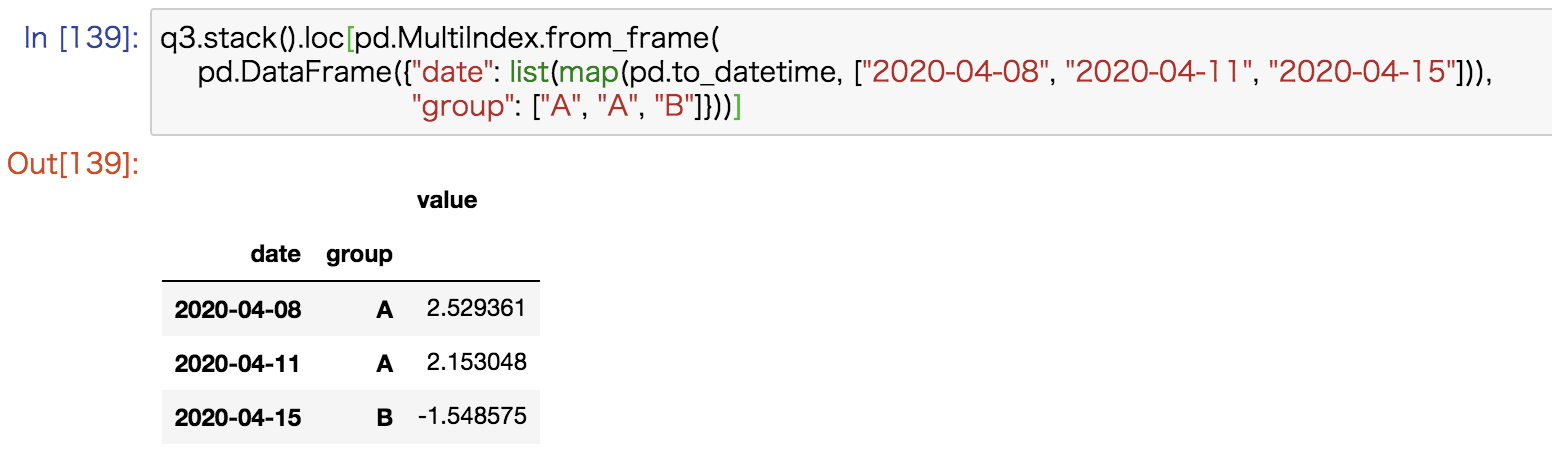
DataFrameから(日付, グループ)のペアに対して対応する値を取得したいときは次のようなコードで実現できます。
他のデータフレームの一部のカラムに対応する値を、インデックスのついたテーブルから取得したいときに便利です。
|
1 2 3 |
q3.stack().loc[pd.MultiIndex.from_frame( pd.DataFrame({"date": list(map(pd.to_datetime, ["2020-04-08", "2020-04-11", "2020-04-15"])), "group": ["A", "A", "B"]}))] |
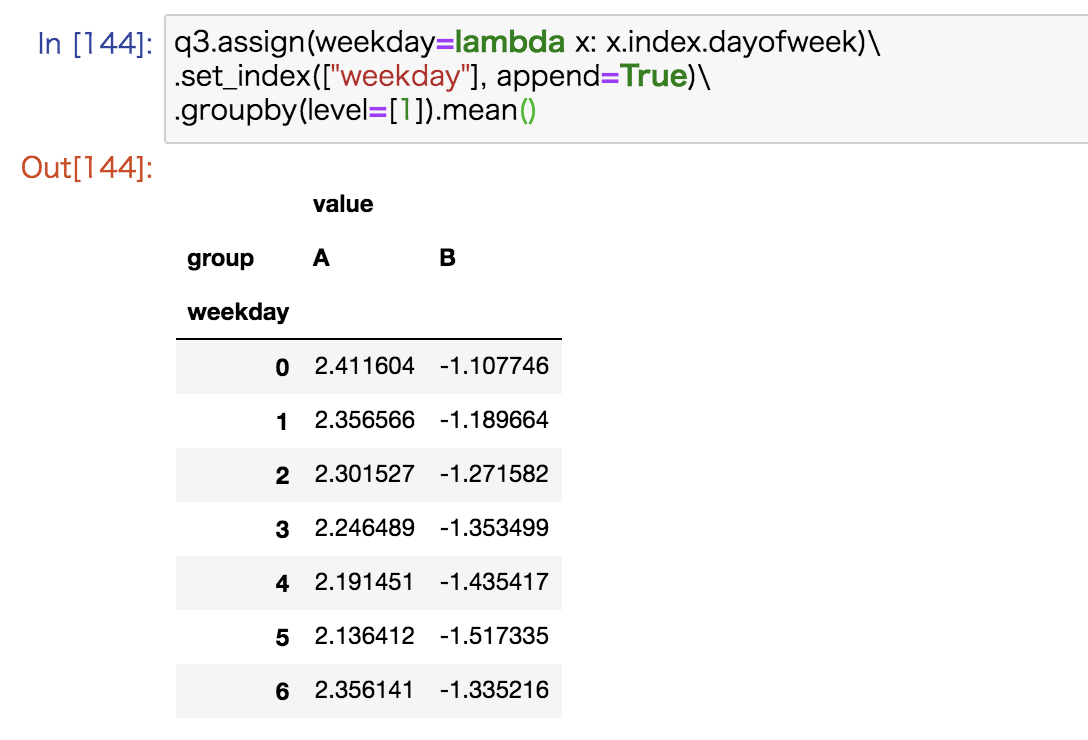
今回のデータでは周期的な増減の傾向はないですが、データによっては曜日ごとに増減があるか知りたいこともあります。
そのような場合は例えば次のコードで曜日別の平均を算出できます。
|
1 2 3 |
q3.assign(weekday=lambda x: x.index.dayofweek)\ .set_index(["weekday"], append=True)\ .groupby(level=[1]).mean() |
以上簡単にではありますが、pandasを使った時系列データ分析の初歩として簡単な時系列データの処理について紹介してみました。


