今回は、QiitaAPI + Yahooの日本語形態素解析API を用いて、Qiitaで流行りのワードを抽出してみようと思います!
この記事でやること
- QiitaAPI + Yahooの日本語形態素解析API を用いて、Qiitaの記事タイトルの形態素解析を行う。
- GAS上でAPIを動かし、その結果をシートに出力する。
- 結果の解析を行い、形態素解析によって記事タイトルに含まれやすいワードを抽出し、考察する。
QiitaAPIで記事名を取得しよう!
- アクセストークンを発行しましょう
まずはアクセストークンの発行を行います。
今回は記事名さえ取得すれば問題ないので、read_qiitaのスコープだけ有効にしておきましょう。
また、アクセストークンは発行後に画面を切り替えると再表示出来なくなるので注意が必要です。
- APIを叩いてみましょう
さっそく、APIを叩いてみましょう。
XXXXXXXXXの箇所には作成したアクセストークンを入れてください。$ curl -H 'Authorization: Bearer XXXXXXXXXXXXXX' 'https://qiita.com/api/v2/items'
正しく実行出来ていれば、記事のタイトル……だけでなく中身も含めてすべてが表示されているかと思います。
これだと今回の目的には適していませんから、記事名だけを取得するように変更したいですね。
取得した情報の加工を行うために、コードを書くことにします。
今回は内容からしてシートへの書き出し等も行いたいので、Google Apps Scriptを利用します。
適当にGoogleスプレッドシートを作成し、スクリプトエディタを開きましょう。 - GASでAPIを叩こう
今回は、下記コードのようなやり方でGASからAPIを叩きました。
APIのパラメータに関しては、QiitaAPIの公式ドキュメントを参考にしてください。
今回はテストですので、”per_page=10″ で記事を10件だけ取得するようにしています。
qiitaApiTestを叩いた時の出力結果は、Qiitaの記事名やURLが表示されてしまう都合上、このブログには載せられないのですが……だいたい下記のような形で出力されるかと思います。1234567891011121314151617181920212223242526272829303132333435363738394041424344function qiitaApiTest() {let articleArray = getQiitaArticle("?per_page=10");articleArray.forEach(function(article){article.checkVariable()});}function getQiitaArticle(urlParams) {const ACCESS_TOKEN = "XXXXXXXXXXXXXXXXX"const END_POINT = "https://qiita.com/api/v2/items"let headers = {'Authorization' : 'Bearer ' + ACCESS_TOKEN};let options = {"method" : "GET","headers" : headers,}//外部へアクセスさせるlet response = UrlFetchApp.fetch(END_POINT + urlParams, options);let json = JSON.parse(response.getContentText());let articleArray = [];json.forEach(function(item, i){let article = new QiitaArticle(item["id"], item["created_at"], item["title"], item["url"], item["likes_count"])articleArray.push(article);});return articleArray;}class QiitaArticle {constructor(id, created_at, title, url, likes_count) {this.id = id;this.created_at = created_at;this.title = title;this.url = url;this.likes_count = likes_count;}checkVariable() {console.log("id:" + this.id + " created_at:" + this.created_at + " title:" + this.title + " url:" + this.url + " likes_count:" + this.likes_count);}}これでQiitaAPIの記事名一覧を取得する方法が解りました。1id:記事ID created_at:2021-10-15T18:27:43+09:00 title:記事名 url:https://qiita.com/ユーザーID/items/記事ID likes_count:0
次は、これを文字列解析して、頻出する単語を取り出していきます。
Yahooの日本語解析APIで形態素解析してみよう!
Yahooの日本語形態素解析APIを利用して、記事名一覧を解析していきます。-
- アプリケーションIDを取得する
こちらの手順に従って、アプリケーションIDを取得します。
- アプリケーションIDを取得する
- とりあえず叩いてみよう
まずは出来るだけ少ないコードでAPIへのリクエストを行ってみました。
出力結果1234567891011121314151617function apiTest() {result = morphologicalAnalysis(getMerosuText());console.log(result.getContentText());}function morphologicalAnalysis(text){let CLIENT_ID = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXX';let requestUrl = "http://jlp.yahooapis.jp/MAService/V1/parse?appid="+CLIENT_ID+"&results=ma,uniq&sentence="+text;let result = UrlFetchApp.fetch(requestUrl);return result}function getMerosuText() {return `メロスは激怒した。必ず、かの邪智暴虐の王を除かなければならぬと決意した。`}取れてはいるようですが、XMLで返ってくるため非常に分かり辛いです。1<?xml version="1.0" encoding="UTF-8" ?><ResultSet xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:yahoo:jp:jlp" xsi:schemaLocation="urn:yahoo:jp:jlp https://jlp.yahooapis.jp/MAService/V1/parseResponse.xsd"><ma_result><total_count>24</total_count><filtered_count>24</filtered_count><word_list><word><surface>メロス</surface><reading>めろす</reading><pos>名詞</pos></word><word><surface>は</surface><reading>は</reading><pos>助詞</pos></word><word><surface>激怒</surface><reading>げきど</reading><pos>名詞</pos></word><word><surface>し</surface><reading>し</reading><pos>助動詞</pos></word><word><surface>た</surface><reading>た</reading><pos>助動詞</pos></word><word><surface>。</surface><reading>。</reading><pos>特殊</pos></word><word><surface>必ず</surface><reading>かならず</reading><pos>副詞</pos></word><word><surface>、</surface><reading>、</reading><pos>特殊</pos></word><word><surface>かの</surface><reading>かの</reading><pos>連体詞</pos></word><word><surface>邪智</surface><reading>じゃち</reading><pos>名詞</pos></word><word><surface>暴虐</surface><reading>ぼうぎゃく</reading><pos>名詞</pos></word><word><surface>の</surface><reading>の</reading><pos>助詞</pos></word><word><surface>王</surface><reading>おう</reading><pos>名詞</pos></word><word><surface>を</surface><reading>を</reading><pos>助詞</pos></word><word><surface>除か</surface><reading>のぞか</reading><pos>動詞</pos></word><word><surface>なけれ</surface><reading>なけれ</reading><pos>助動詞</pos></word><word><surface>ば</surface><reading>ば</reading><pos>助詞</pos></word><word><surface>なら</surface><reading>なら</reading><pos>助動詞</pos></word><word><surface>ぬ</surface><reading>ぬ</reading><pos>助動詞</pos></word><word><surface>と</surface><reading>と</reading><pos>助詞</pos></word><word><surface>決意</surface><reading>けつい</reading><pos>名詞</pos></word><word><surface>し</surface><reading>し</reading><pos>助動詞</pos></word><word><surface>た</surface><reading>た</reading><pos>助動詞</pos></word><word><surface>。</surface><reading>。</reading><pos>特殊</pos></word></word_list></ma_result><uniq_result><total_count>24</total_count><filtered_count>24</filtered_count><word_list><word><count>2</count><surface>。</surface><reading/><pos>特殊</pos></word><word><count>2</count><surface>し</surface><reading/><pos>助動詞</pos></word><word><count>2</count><surface>た</surface><reading/><pos>助動詞</pos></word><word><count>1</count><surface>、</surface><reading/><pos>特殊</pos></word><word><count>1</count><surface>かの</surface><reading/><pos>連体詞</pos></word><word><count>1</count><surface>と</surface><reading/><pos>助詞</pos></word><word><count>1</count><surface>なけれ</surface><reading/><pos>助動詞</pos></word><word><count>1</count><surface>なら</surface><reading/><pos>助動詞</pos></word><word><count>1</count><surface>ぬ</surface><reading/><pos>助動詞</pos></word><word><count>1</count><surface>の</surface><reading/><pos>助詞</pos></word><word><count>1</count><surface>は</surface><reading/><pos>助詞</pos></word><word><count>1</count><surface>ば</surface><reading/><pos>助詞</pos></word><word><count>1</count><surface>を</surface><reading/><pos>助詞</pos></word><word><count>1</count><surface>メロス</surface><reading/><pos>名詞</pos></word><word><count>1</count><surface>必ず</surface><reading/><pos>副詞</pos></word><word><count>1</count><surface>暴虐</surface><reading/><pos>名詞</pos></word><word><count>1</count><surface>決意</surface><reading/><pos>名詞</pos></word><word><count>1</count><surface>激怒</surface><reading/><pos>名詞</pos></word><word><count>1</count><surface>王</surface><reading/><pos>名詞</pos></word><word><count>1</count><surface>邪智</surface><reading/><pos>名詞</pos></word><word><count>1</count><surface>除か</surface><reading/><pos>動詞</pos></word></word_list></uniq_result></ResultSet>
このままでは扱い辛いので、加工などまで行うコードに書き換えてみました。
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162function morphologicalAnalysisApiTest() {let urlParams = "?results=ma,uniq";wordArray = morphologicalAnalysis(getMerosuText(), urlParams);wordArray .forEach(function(word){word.checkVariable()});}function morphologicalAnalysis(text, urlParams){const CLIENT_ID = 'XXXXXXXXXXXXXXXXXXX';const requestUrl = "http://jlp.yahooapis.jp/MAService/V1/parse" + urlParams;let sentence = {'sentence': text,'appid' : CLIENT_ID};let options = {'method' : 'post','payload' : sentence};// XML形式で結果が返ってくるため、パースして利用する。let rawRes = UrlFetchApp.fetch(requestUrl, options);let parseRes = XmlService.parse(rawRes.getContentText());// 今回のタスクに用いるword属性の取り出しを行う。レスポンスの構造は公式ドキュメント参照。let nameSpace = XmlService.getNamespace("urn:yahoo:jp:jlp");let rootElement = parseRes.getRootElement();let uniqResult = rootElement.getChild("uniq_result", nameSpace);let wordList = uniqResult.getChild("word_list", nameSpace);let words = wordList.getChildren("word", nameSpace);let wordArray = [];for (let i = 0; i < words.length; i++) {let surface = words[i].getChild("surface", nameSpace).asElement().getText();let pos = words[i].getChild("pos", nameSpace).asElement().getText();let count = words[i].getChild("count", nameSpace).asElement().getText();let word = new Word(surface, pos, count);wordArray.push(word);}return wordArray;}function getMerosuText() {return `メロスは激怒した。必ず、かの邪智暴虐の王を除かなければならぬと決意した。`}class Word {constructor(surface, pos, count) {this.surface = surface;this.pos = pos;this.count = count;}checkVariable() {console.log("surface:" + this.surface + " pos:" + this.pos + " count:" + this.count);}} - こちらのmorphologicalAnalysisApiTestを叩いてみた結果はこんな感じです!
悪く無さそうな感じがしますね!123456789101112131415161718192021surface:。 pos:特殊 count:2surface:し pos:助動詞 count:2surface:た pos:助動詞 count:2surface:、 pos:特殊 count:1surface:かの pos:連体詞 count:1surface:と pos:助詞 count:1surface:なけれ pos:助動詞 count:1surface:なら pos:助動詞 count:1surface:ぬ pos:助動詞 count:1surface:の pos:助詞 count:1surface:は pos:助詞 count:1surface:ば pos:助詞 count:1surface:を pos:助詞 count:1surface:メロス pos:名詞 count:1surface:必ず pos:副詞 count:1surface:暴虐 pos:名詞 count:1surface:決意 pos:名詞 count:1surface:激怒 pos:名詞 count:1surface:王 pos:名詞 count:1surface:邪智 pos:名詞 count:1surface:除か pos:動詞 count:1
少なくとも、どの語がどれだけ出現したのかは正しく取れていそうです。
あとはこれを先程の記事名に対して行えば、それっぽい結果が得られるはず!
ふたつのAPIをくっつけてみよう!
取得した記事名を日本語解析APIに流し込みます。冒頭に書いた通り、今回の目的はQiitaで流行っているワードを抽出することです。
何をもって流行りのワードとするかは突き詰めれば変わってきそうですが、
今回は単純に形態素の出現数で考えることにします。
日本語解析APIのなかで形態素の出現数は算出されていますから、QiitaAPIで取得した記事名をすべてくっつけて日本語解析APIに流せば……とも思ったのですがリクエストが大きすぎると叱られてしまいました。
すべてを一度に解析するのは難しそうなので、下記のように100記事タイトルごとに解析を掛けて、後から集計をする形で進めていきます。
コードは下記の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
function main() { let joinTitle = ""; let resultArray = [] for (let i = 1; i <= 10; i++) { joinTitle = ""; // 一度に取得出来る記事数は100件までなので、ページを分けて取得する(100件*10ページ) let articleArray = getQiitaArticle("?page=" + i + "&per_page=100"); articleArray.forEach(function(article, i){ // 文字コードによっては日本語解析API内でエラーが出るため除外する。 let safeTitle = article.title.replace(/[^\u4E00-\u9FFFぁ-んァ-ヶa-zA-Zー]+/g, ''); joinTitle = joinTitle + safeTitle; }); if (joinTitle != null) { let wordArray = morphologicalAnalysis(joinTitle, "?results=ma,uniq&filter=9"); wordArray.forEach(function(word){ // 既に出現していた形態素であった場合、countの加算のみを行う let duplicateWord = resultArray.find(rWord => rWord.surface == word.surface) if (duplicateWord === undefined) { resultArray.push(word); } else { duplicateWord.count = parseInt(duplicateWord.count) + parseInt(word.count); } }); } } resultArray.forEach(function(word){ word.checkVariable() }); } |
それでは、結果を確認してみましょう。
結果を確認してみよう!
上記のコードそのままで実行した場合(記事数最大1000件/新着順)、記事タイトルに含まれる形態素の上位30件は下記の通りでした。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
方法 63 環境 32 メモ 31 自動 30 アプリ 29 作成 29 表示 26 実装 25 更新 25 開発 24 数 24 構築 23 とき 23 データ 23 ため 22 JavaScript 21 エラー 21 取得 21 LGTM 21 デイリー 21 ランキング 21 ファイル 20 初心者 20 インストール 20 関数 20 使用 19 備忘 19 時 18 ネットワーク 18 |
……なるほど。さっぱり参考になりませんね!
ぼんやりと、javascriptが流行ってるのかなー、くらいのことしかわかりません。
もしかして、QiitaAPIで記事を取得する際のパラメータが悪いのでしょうか。
今回のコードだと page: 1~10, per_page: 100 で指定していますから、最新1000件の記事を解析している筈です。
ドキュメントによると、queryを指定することでQiitaの記事検索ページと同じように検索出来るようです。
いろいろと指定して試してみました。
query=title:コロナ
記事タイトル最大1000件を解析したうち、形態素の上位30件を提示します。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
コロナ 277 新型 202 コロナウイルス 175 対策 64 データ 63 感染者 49 ウィルス 46 サイト 45 禍 42 感染症 41 状況 38 分析 34 話 34 感染 33 可視 31 予測 29 東京都 25 作成 24 陽性 23 Python 22 情報 22 こと 20 開発 19 グラフ 18 患者 18 発生 17 アプリ 16 COVID 16 モデル 16 |
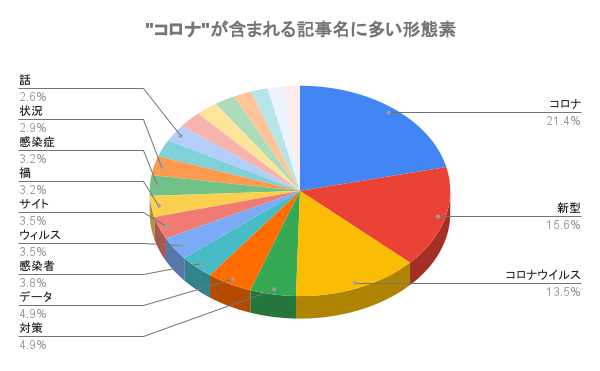
おぉ偏った。コロナは “新型コロナ” や “コロナウイルス” のような文言で書くことが多いでしょうから、上位3件は非常に納得のいく結果です。
あとは、みなさんどういう”サイト”で情報を確認するのかですとか、”分析”やら”可視”、”予測”あたりの記事を投稿していらっしゃることがわかります。”Python”を使った記事が多いようですね。
query=title:GMO
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
GMO 29 クラウド 14 タイプ 8 決済 8 インストール 7 サーバー 7 リンク 7 GMOPG 6 Plus 6 API 5 VPS 5 あおぞら 5 ネット 5 銀行 5 カード 4 コイン 4 ペイメント 4 利用 4 実験 4 登録 4 sunabarAPI 3 アプリ 3 クレジット 3 ゲートウェイ 3 データ 3 処理 3 勉強会 3 取引 3 手順 3 方法 3 |
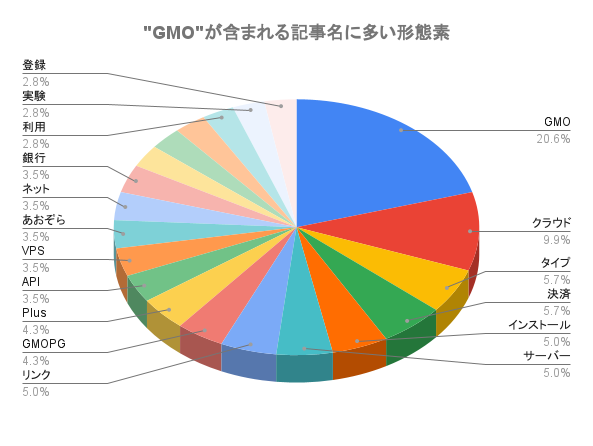
こちらに関しては、記事件数が55件と少なかったので、目視での確認も行ってみました。
“クラウド”が多く出てきているのは、GMOクラウドVPSやGMOアプリクラウドの設定に関する記事が多いため。
次点で印象に残る決済関係(“あおぞら”、”ネット”、”銀行”、”決済”など)に関しては、GMOあおぞらネットさんが公開している sunabarAPIを試してみた記事が多いためのようです。
目視確認と計算結果がおおよそ紐付いているので、それなりに正しく計算出来ていそうな気がします。
query=tag:Javascript
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
JavaScript 170 React 60 方法 60 関数 47 表示 45 アプリ 36 作成 33 入門 30 実装 30 取得 29 人 29 今日 29 処理 29 同期 28 画像 27 オブジェクト 24 初心者 23 機能 23 値 21 エラー 21 配列 21 変数 20 開発 20 データ 19 違い 19 ため 18 コンポーネント 18 時 18 要素 18 Nodejs 17 |
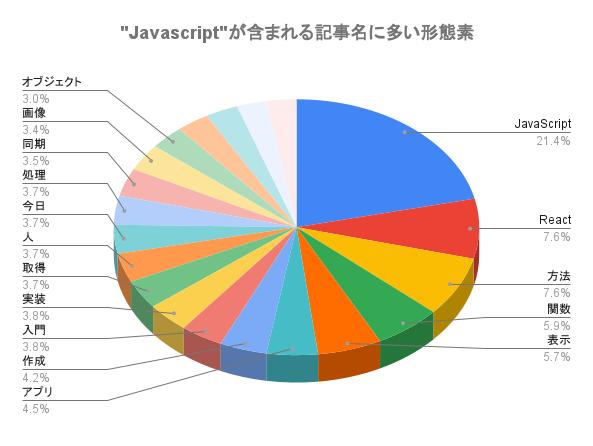
1000記事中に60記事も”React”が付いているのが特徴的でしょうか。
“Nodejs”(コード中で.を除去したので、正確にはNode.js)が上の方に出てきてるのも面白いです。
注目を浴びている関連技術を探すのに使えるかもしれません。
おわりに
形態素解析って結構めんどうなイメージがありましたが、APIを使うと楽に出来るもんですね!分析対象の抽出方法を上手いこと調整すれば、より精度が上げられそうです。
今回はQiitaの記事を対象にしましたが、TwitterAPIを使ってつぶやきを抽出したり、小説をまるまる一冊分解析したりしてみても楽しそうです。今後も機会があったら色々と遊んでみようと思います。
それでは、ありがとうございました!


