記事内容
今回の記事で扱う内容は下記のようになります。
(どれも頭に “Google Apps Scriptを使って” が付きます)
今回は尺の都合上、前編と後編に区切って投稿させて頂きます。
それぞれの記事で紹介する内容は下記の通りです。
- 前編
- 記事のブックマーク数を得る方法 (簡単なAPIの利用方法)
- 記事タイトルを得る方法 (スクレイピング)
- 後編
- 全記事のURLを取得する方法 (sitemap.xmlのクローリング)
- Googleスプレッドシートの操作方法
- 定期実行処理
- Slackへの投稿方法
はじめに
こんにちは! GMOアドマーケティング、TAXELチームに配属された新卒エンジニアのY.Oです!
私の入社後、社内からTECHブログ(このブログ)の活性化の為にはてなブックマーク数を可視化したい!
という要望が挙がり、新卒の私が勉強を兼ねて対応を行うことになりました。
そこで作成する事になったのが、はてなブックマーク数集計ツールです。
“Linuxサーバー上でRubyのスクリプトを定期実行しGoogleスプレッドシートに投稿を行い、
その情報を別のRubyスクリプトで読み込んでSlackへ週一間隔でポストする”
…といった、少し複雑な方法で昨年11月頃にツールの作成を行い、
TECHブログの全記事のブックマーク数の自動集計とSlackへの投稿を実現しました。
しかし、作ってみた後に業務でGoogle Apps Scriptを扱う機会があり、
シートの操作や定期実行処理のやりやすさから、
スプレッドシートへの書き込み/集計やSlackへの投稿程度の処理であれば、
GASを利用した方が簡単に実現出来そうだと感じた為、
勉強を兼ねて「GASを使ったはてなブックマーク数集計ツール」を改めて製作する事にしました。
せっかくですので、この記事で作り方を共有します。
やりたいこと
今回作成するツールで実現したい事をざっくりとまとめると、こんな感じになります。
- このブログの全記事のブックマーク数を集計したい
- 集計したブックマーク数をSlackに投稿したい
- 集計前のブックマーク数も確認出来るようにしたい
データを集計するとなるとDBに保存して…といったやり方も多いですが、
今回はGoogleスプレッドシートを扱う事にします。
理由としては、下記の通りです。
- プログラミングの知識が無い人でも確認・編集が可能
- データベースを用意する必要が無い
- ピボットテーブルを利用して簡単に集計が出来る
- 定期実行処理がGUI上で簡単に設定出来る
- データベースを用意すると管理・運用が面倒
- GASを使えばスプレッドシート上で全て完結させられる
一番下の項目が、最も大きな要因だと思います。
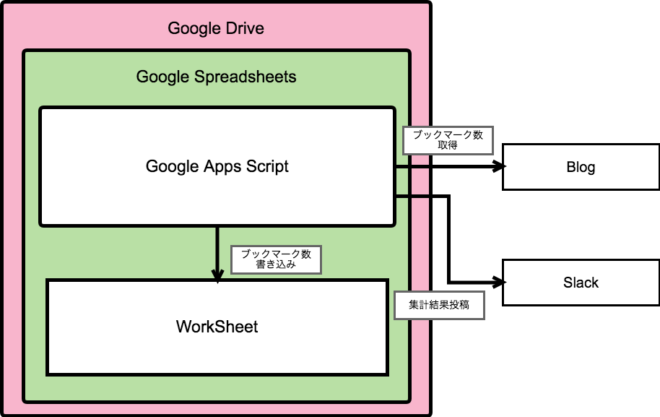
Googleスプレッドシート上で動くGASを利用すれば、
スプレッドシート上で全て完結させられそうです、すごい。
図にするとこんなイメージでしょうか、シンプルに実現させられそうですね。

手順を考えてみよう
まずは、どんな手順で作れば良いか考えてみましょう。
今回の作業で必要な機能をざっと考えると、こんな感じでしょうか。
① 全記事のURLを取得する
② 記事から情報を取得する(全記事に対して実行)
・記事からブックマーク数を取得する
・記事からタイトルを取得する
③ 取得した情報をスプレッドシートに書き込む
④ スプレッドシートから情報を読み取る
⑤ Slackに投稿するメッセージを作成する
⑥ Slackに投稿する
それでは、これらの機能を作っていきましょう。
処理の順番通りに作っていっても良いのですが、
一番最初に記事URLの取得をやるとちょっと作業として重たいので、
まずは②の作業から始めていきます。
シートに書き込む情報を取得してみよう!
それでは早速、シートに書き込む情報の取得(ブックマーク数 / タイトル / URL)を進めていきましょう!
各記事のURL毎に取得しシートに書き込む…といった作業になると推測できますが、
一気にやろうとすると難しいので、やる事を小分けにしていきましょう。
- シートに書き込む情報を取得する
- ブックマーク数
- タイトル
- URL
- 取得したタイトル/ブックマーク数をシートに書き込む
- 上記処理を全記事に対して実行する方法を考える
それでは、一つずつ進めて行きましょう。
記事URLからブックマーク数を取得する
ここから暫くは、記事URLが分かっている前提で進めさせて頂きます。
(記事URLをどう取得するかに関しては後述します)
当然の事ながらURLにはブックマーク数は付いていませんので、別の手段で取得する必要があります。
はてなブックマーク数に関してはブックマーク件数取得APIというものが公開されているので、
こちらを利用してブックマーク数の取得を行いましょう。
GASではかなりシンプルにWebAPIへリクエストを送る事が出来ますので、
下記のようなコードだけで実現可能です。
|
1 2 3 4 5 6 7 8 9 |
function main() { Logger.log(fetchHatenaBookmark('http://techblog.gmo-ap.jp/2017/10/11/%E3%82%B3%E3%83%BC%E3%83%89%E3%83%AC%E3%83%93%E3%83%A5%E3%83%BC%E3%82%92%E6%80%96%E3%81%8C%E3%81%A3%E3%81%A6%E3%81%84%E3%81%9F%E6%96%B0%E5%8D%92%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%8B%E3%82%A2%E3%81%8C/')); } function fetchHatenaBookmark(url) { var requestUrl = "http://api.b.st-hatena.com/entry.count?url=" + url; var result = JSON.parse( UrlFetchApp.fetch(requestUrl) ); return result; } |
|
1 2 |
# Logger [17-12-26 16:03:19:025 JST] 21.0 |
この関数をGASに貼り付けて実行すると、無事に結果が返ってくるかと思います。
実際にツールとして運用する際は例外処理なども必要かと思いますが、
今回はコレで良しとしましょう。
記事URLからタイトルを取得する
ブックマークは簡単に取ることが出来ましたが、タイトルは少し工夫が必要で、
URLからHTMLを取得しタイトル要素を特定して取得する…といった作業が必要になります。
ちょっと難しそうですが、やって行きましょう。
まずはHTMLを取得してみましょう、下記コードだけで実装出来ます、かんたん。
|
1 2 |
var response = UrlFetchApp.fetch(url); //HTTPResponseを取得 var html = response.getContentText('UTF-8'); //文字コードを指定してHTMLコンテンツを取得 |
次にHTMLからタイトルタグだけを抜き出す作業を進めていきましょう。
正規表現と呼ばれる方法でも出来るのですが…それだと抜き出す対象が増えた時ちょっと面倒なので、ライブラリを使って楽しましょう。
(怠惰はプログラマの三大美徳の一つです、出来るだけ手間を減らしましょう)
今回はParserライブラリを使用します、下記手順に従って導入してみてください。
- リソース => ライブラリを指定
- スクリプトID(M1lugvAXKKtUxn_vdAG9JZleS6DrsjUUV)を入力
- 追加を押す
- バージョンを設定
- 保存
Parserライブラリの使い方は簡単です。
例として、下記のようなHTMLがあったとすれば、
|
1 2 |
<h1>タイトル</h1> <p>本文</p> |
下記コードで “タイトル” が取得出来ます。
fromで指定した文字列とtoで指定した文字列で囲んだ間を取得するだけですので、非常にシンプルです。
|
1 |
Parser.data(html).from("<h1 class=\"entry-title\">").to("</h1>").build() |
このブログのHTMLのタイトルは<h1 class=”entry-title”>と</h1>に囲まれていますので、
下記コードで取得する事が出来ますね。
|
1 2 3 4 5 6 7 8 9 |
function main() { Logger.log(fetchArticleTitle('https://goo.gl/9htre4','<h1 class=\"entry-title\">', '</h1>')); } function fetchArticleTitle(url, from_str, to_str) { var response = UrlFetchApp.fetch(url); //HTMLを取得 var html = response.getContentText('UTF-8'); //文字コードを変換 // dataに指定したHTML中に含まれる、fromに指定した文字列からtoに指定して文字列までの文字列を取得する(buildで文字列、iterateで文字配列) return Parser.data(html).from(from_str).to(to_str).build() } |
|
1 2 |
# Logger [17-12-26 16:04:52:168 JST] コードレビューを怖がっていた新卒エンジニアが始めた対策 |
終わってみればたった4行でタイトルを取得する事が出来てしまいました。
全記事のURLを取得しよう!
次に、全記事のURLを取得していきましょう!
記事のURLを取得する方法にも色々あると思うのですが、今回はsitemap.xml(以下サイトマップ)を解析する方法で進めていこうと思います。
サイトマップというのは、GoogleさんがWebサイトを調べる際に利用するWebサイトの地図のようなもので、大きめのWebサイトであれば大抵配置されています、このブログの場合はこのページですね。
XMLの構成を見ると、下記のようになっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<sitemapindex xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9 http://www.sitemaps.org/schemas/sitemap/0.9/siteindex.xsd" xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <sitemap> <loc>https://techblog.gmo-ap.jp/sitemap-misc.xml</loc> <lastmod>2017-12-18T05:13:15+00:00</lastmod> </sitemap> <sitemap> <loc>https://techblog.gmo-ap.jp/sitemap-pt-post-2017-12.xml</loc> <lastmod>2017-12-15T08:03:27+00:00</lastmod> </sitemap> <sitemap> <loc>https://techblog.gmo-ap.jp/sitemap-pt-post-2017-11.xml</loc> <lastmod>2017-11-29T08:37:34+00:00</lastmod> </sitemap> #以下略 |
見ての通りlocタグの中に各月別のサイトマップへのリンクが入っていますので、まずはコチラを取得してみましょう。
先程紹介したParseライブラリを利用しても出来るとは思うのですが、
ちょっと大変ですので HTML/XML parser for Google Apps Script を使用しましょう。
スクリプトIDは 1Jrnqmfa6dNvBTzIgTeilzdo6zk0aUUhcXwLlQEbtkhaRR-fi5eAf4tBJ です、
先程と同様に導入してみてください。
このライブラリは先程のParserと異なり、文字列では無くタグやID、クラス名などを指定して要素を取り出す事が出来ます。
下記のようなコードを書いて、locタグの中身を取り出してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
function main() { fetchAllArticleUrl('https://techblog.gmo-ap.jp/sitemap.xml'); } function fetchAllArticleUrl(sitemap_url) { var res = UrlFetchApp.fetch(sitemap_url).getContentText(); var doc = XmlService.parse(res), xml = doc.getRootElement(), locs = parser.getElementsByTagName(xml, 'loc'); // xmlに含まれるloc要素を配列で取得する Logger.log(loca[0].getValue()); } |
|
1 |
[17-12-26 17:02:59:443 JST] https://techblog.gmo-ap.jp/sitemap-misc.xml |
上記コードを実行すると、sitemap一番上のxmlが取得出来たかと思います。
このxmlから更に記事のURLを取得してみましょう。
記事のURLもlocタグの中に書かれているので、下記のようなコードで取得出来る筈です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
function main() { articleUrls = fetchAllArticleUrl('https://techblog.gmo-ap.jp/sitemap.xml'); articleUrls.forEach(function(url){ Logger.log(url); }); } // 引数として受け取ったsitemap_urlを利用して全記事のURLを取得する function fetchAllArticleUrl(sitemap_url) { var result = []; var locs = fetchElementByUrl(sitemap_url, 'loc'); // 月別のsitemapを取得する // 取得した月別url毎に、記事URLを取得しresultに追加する。 locs.forEach(function(loc){ var articles = fetchElementByUrl(loc.getValue(), 'loc'); articles.forEach(function(article){ result.push(article.getValue()); }) }); return result; } // 引数として受け取ったurl(xml)に含まれるtag要素の配列を返却する function fetchElementByUrl(url, tag) { var res = UrlFetchApp.fetch(url).getContentText(); var doc = XmlService.parse(res), xml = doc.getRootElement(), locs = parser.getElementsByTagName(xml, tag); return locs } |
|
1 2 3 4 5 6 |
# Logger [17-12-26 17:04:07:068 JST] https://techblog.gmo-ap.jp/ [17-12-26 17:04:07:069 JST] https://techblog.gmo-ap.jp/2017/12/21/web%e3%81%a7%e3%83%97%e3%83%83%e3%82%b7%e3%83%a5%e9%80%9a%e7%9f%a5%e3%82%92%e8%a9%a6%e3%81%97%e3%81%a6%e3%81%bf%e3%82%8b/ [17-12-26 17:04:07:070 JST] https://techblog.gmo-ap.jp/2017/12/19/itp%e3%81%ae%e5%8b%95%e3%81%8d%e3%81%a8%e3%81%9d%e3%81%ae%e5%bd%b1%e9%9f%bf%e3%81%ab%e3%81%a4%e3%81%84%e3%81%a6/ [17-12-26 17:04:07:071 JST] https://techblog.gmo-ap.jp/2017/12/15/%e7%94%bb%e5%83%8f%e8%a7%a3%e6%9e%90api%e3%82%92%e8%a9%a6%e3%81%97%e3%81%a6%e3%81%bf%e3%82%88%e3%81%86/ # 以下省略 |
もう少し綺麗に書けそうですが、大体こんな感じかなと思います。
あとは取得したURLを利用しタイトルとブックマーク数をシートに書いていけばデータの取得は終わりですが、
尺の関係上、そのあたりは後編に含める事にします。
前篇終了
これで無事、シートに書き込む全ての情報を取得する事が出来ました。
現状、終わった作業を消していくとこんな感じになりますね。
① 全記事のURLを取得する
② 記事から情報を取得する(全記事に対して実行)
・記事からブックマーク数を取得する
・記事からタイトルを取得する
③ 取得した情報をスプレッドシートに書き込む
④ スプレッドシートから情報を読み取る
⑤ Slackに投稿するメッセージを作成する
⑥ Slackに投稿する
まだまだ半分以上残っているように見えますが、スプレッドシートやSlackとの提携は簡単ですので、
後編でさっくりと進めていきましょう。
それでは、お疲れ様でした。後編も見て頂ければ幸いです。


