
こんにちは、GMOアドマーケティングのS.Rです。
Googleが開発しているTPUをご存知ですか?TPUはディープラーニングを高速化するため、Googleが開発したプロセッサです。TPUでディープラーニングのモデルのトレーニング時間は20倍以上の改良が可能です。2018年9月26日にColabというGoogleが提供されている、 機械学習のオンラインノートサービスでTPUインスタンスの無料提供を始めました。今回はColabでTPUを利用する方法を投稿させていただきます。本記事中の図説は、筆者が自らの環境で作成したものを含みます。
1 Colabのインスタンスを作る
Colabの利用を始める最初のStepは、Colabのファイルを作ります。Google Driveの管理画面へ遷移し、新しいColabのファイルを作ります(図1)。
2 TPUを設定する
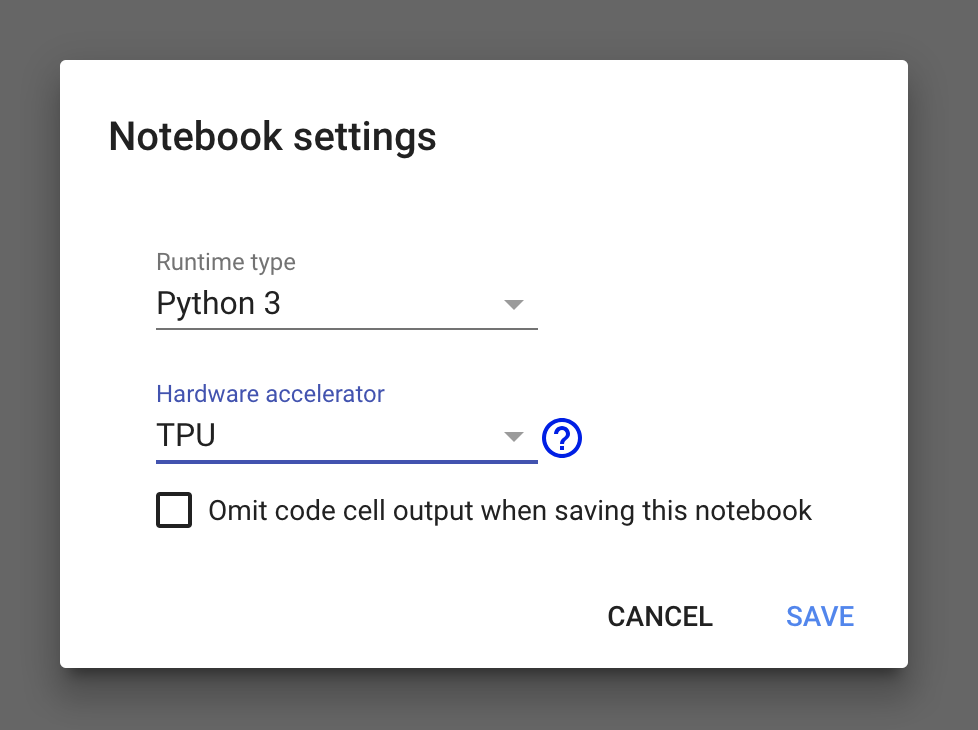
作成されたファイルのメニューのRuntimeをクリックし、ポップアップメニューからchange runtime typeをクリックします。Notebook settings画面でHardware acceleratorでTPUを選択します。
3 TPUとCPU,GPUの計算力の比較
3.1 スペックの比較
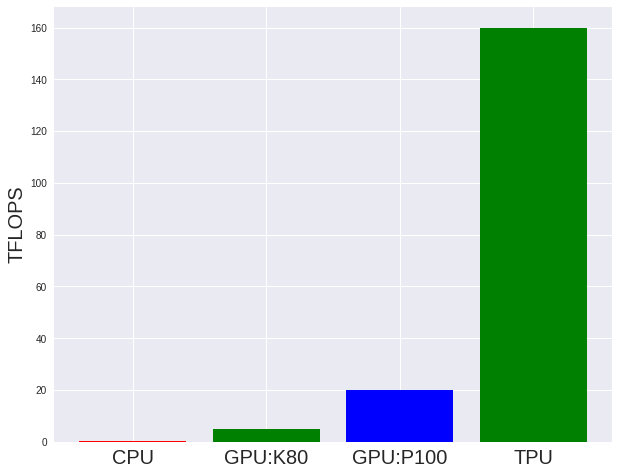
現在のサーバーによく使われるCPUとGPUのスッペグ情報とTPUの公式サイトよりTPUとCPU,GPUの計算力の比較図を作ってみました。計測単位はTFLOPS(浮動小数点演算を1秒間に1兆回行うことを表す単位)です。
3.2 実戦でBenchmark
図3から見るとTPUの計算力はGPUの計算力10倍以上ですが実際の運用する時は本当にそんなに早くなるのでしょうか?早速例を使って実際のPerformanceをbenchmarkしてみます。
3.2.1 Library
今回は下記のディープラーニングのツールまたはライブラリを利用してました。
- Tensorflow
ディープラーニングに対応しており、Googleの各種サービスなどでも広く活用されている。 2017年2月15日に TensorFlow 1.0 がリリースされた。 対応プログラミング言語はC言語、C++、Python、Java、Go。 対応OSは64ビットのLinux(ただしバイナリ配布はUbuntu用)、macOS、Windows。ハードウェアは CPU、NVIDIA GPU、Google TPU、Snapdragon Hexagon DSP などに対応していて、Android Neural Networks API 経由で Android 端末のハードウェアアクセラレータも使用できる。 (TensorFlow、 2018年6月22日、ウィキペディア日本語版、https://ja.wikipedia.org/wiki/TensorFlow#%E6%A6%82%E8%A6%81)
- Keras
Kerasの公式より下記の紹介があります。
Kerasは,Pythonで書かれた,TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリです。 Kerasは,迅速な実験を可能にすることに重点を置いて開発されました。 アイデアから結果に到達するまでのリードタイムをできるだけ小さくすることが、良い研究をするための鍵になります。(Keras: Pythonの深層学習ライブラリ、https://keras.io/ja/)
3.2.2 ソースコード:
MNISTのデータ使ってマルチTPUを利用する例を作ってみました。MNISTは手書き数字画像(図4)70000枚を集めた画像データセットになります, 60000枚は学習データ、10000枚がテストデータになっています。

Step1 : 使ってるLibarayをImportします:
|
1 2 3 4 5 6 |
import time import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout,Conv2D from keras.optimizers import RMSprop |
Step2:MINISTのデータをダウンロードします:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# the data, split between train and test sets batch_size = 128 num_classes = 10 epochs = 5 x_train = x_train.reshape(60000, 784) x_test = x_test.reshape(10000, 784) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') # convert class vectors to binary class matrices y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) |
Step3:Kerasのモデルをbuildする:
|
1 2 3 4 5 6 7 8 |
num_classes = 10 inputs = Input(shape=(784,), dtype=tf.float32) output = Dense(4096, activation='relu')(inputs) output = Dropout(0.2)(output) output = Dense(4096, activation='relu')(output) output = Dropout(0.2)(output) output = Dense(num_classes, activation='softmax')(output) model = Model(inputs=[inputs], outputs=[output]) |
Step4:TPUを初期化する:
|
1 2 3 |
TPU_WORKER = "grpc://" + os.environ["COLAB_TPU_ADDR"] strategy = tf.contrib.tpu.TPUDistributionStrategy( tf.contrib.cluster_resolver.TPUClusterResolver(TPU_WORKER)) |
Step5:TPUのモデルを作る:
|
1 |
model = tf.contrib.tpu.keras_to_tpu_model(model,strategy=strategy) |
Step6:モデルをfitする:
|
1 2 3 4 5 6 7 8 9 10 |
start_time = time.time() history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) # Keras ModelをTPU形式へ変換 tpu_time = time.time() - start_time print("TPU: --- %s seconds ---" % tpu_time) print (" %.2f %% improved" % (100 - tpu_time * 100 / cpu_time) ) |
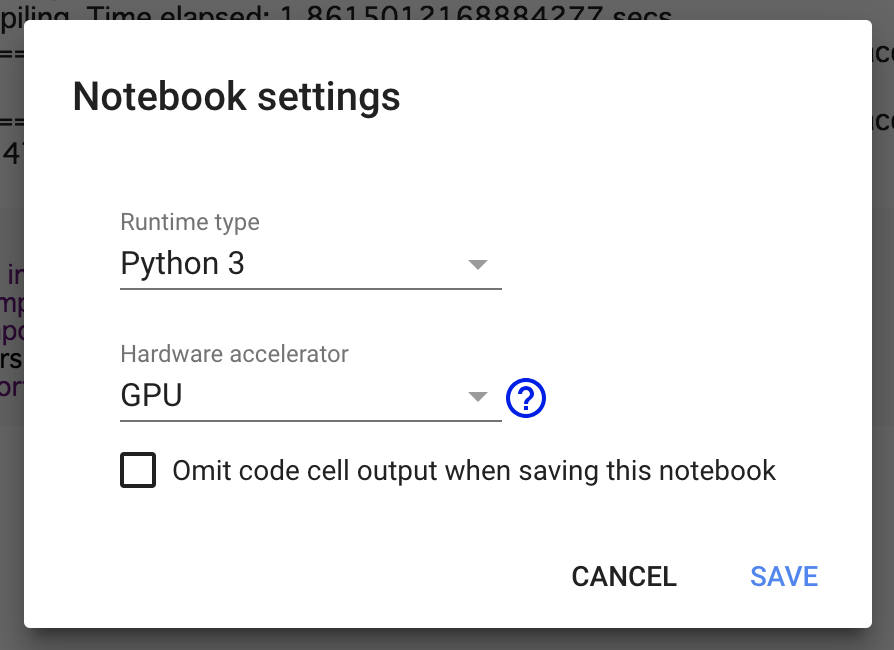
Step7:インスタンスをGPUに変更する:
Step8:GPUモデルをfitする:
step3のコードでモデルを作ってモデルをFitする。
|
1 2 3 4 5 6 7 8 9 |
start_time = time.time() history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) Gpu_time = time.time() - start_time print("TPU: --- %s seconds ---" % gpu_time) #print (" %.2f %% improved" % (100 - gpu_time * 100 / cpu_time) ) |
実行時間:
下記の表はGPUとTPUでモデルをフィッティング時間です。この表から見るとTPUで同じモデルをフィッティングする時間が56%を軽減できます。
| Device | 実行時間 |
| TPU | 195s |
| GPU | 443s |
4まとめ
今回はTPUでモデルをトレーニングするの一例を紹介しました。いかがでしたでしょうか。
基本的に高い計算力を使うと、モデルの精度、作成速度が改善できます。もし今回のブログが皆さんのディープラーニング モデルの実装にお役に立てば幸いです。



