
こんにちは、GMOアドマーケティングのS.Rです。
良いモデルを作るには、大きなサイズの学習データが必要です。そして、高速にモデルをトレーニングすることができれば、イテレーションの短縮になります。今回は高速にモデルをトレーニングするために、複数のGPUでディープラーニングのモデルをトレーニングする方法を投稿します。本記事中の図説は、筆者が自らの環境で作成したものを含みます。
1. LibraryとTool:
今回は下記のディープラーニングのツールまたはライブラリを利用していました。
- Tensorflow
ディープラーニングに対応しており、Googleの各種サービスなどでも広く活用されている。 2017年2月15日に TensorFlow 1.0 がリリースされた。
対応プログラミング言語はC言語、C++、Python、Java、Go。 対応OSは64ビットのLinux(ただしバイナリ配布はUbuntu用)、macOS、Windows。ハードウェアは CPU、NVIDIA GPU、Google TPU、Snapdragon Hexagon DSP などに対応していて、Android Neural Networks API 経由で Android 端末のハードウェアアクセラレータも使用できる。(TensorFlow、 2018年6月22日、ウィキペディア日本語版、https://ja.wikipedia.org/wiki/TensorFlow)。
- Keras
Kerasの公式より下記の紹介があります。
Kerasは,Pythonで書かれた,TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリです。 Kerasは,迅速な実験を可能にすることに重点を置いて開発されました。 アイデアから結果に到達するまでのリードタイムをできるだけ小さくすることが、良い研究をするための鍵になります。(Keras: Pythonの深層学習ライブラリ、https://keras.io/ja/)
- Google Cloud ML(Machine Learning) Engine
Google Cloud Machine LearningEngine はGoogleさんが提供している機械学習用クラウドサービスです。このサービス使うと下記の利点があります:
- 開発の負担を軽減:環境構築せずにTensorflow/Kerasのプログラムを実行できます。
- Hardwareを購入しなくて良い:ML EngineでSingle CPUから最新のTPUまで様々なDeviceを選べます。実際の利用時間から課金されています。
- メンテナンスの手数がかからない:クラウドサービスですので、Googleさんがメンテナンスを行い、運用の手間がかかりません。
2. マルチGPUのAPI:
KerasはマルチGPUのAPI を提供しています。APIの詳細情報は下記です。
APIの関数名
|
1 |
keras.utils.multi_gpu_model(model, gpus) |
入力引数
- model: Kerasのモデルインスタンスです。OOMエラーを避けるためにこのインスタンスのモデルはCPU上でビルドされるべきです。
- gpus: 使ってるGPUの数です。gpus の範囲が2以上の整数です。
返り値
初めに用いられたmodelに似たKerasのModelインスタンスですが,複数のGPUにワークロードが分散されたものです。
関数の流れ
マルチGPUでモデルをトレーニングする流れは(図1)三つステップがあります。
- モデルの入力のバッチサイズをGPU数と同じ分のサブバッチに分割します。例えば入力のバッチサイズが32、GPU数4の場合にサブバッチは32/4 = 8です。
- サブバッチのごとにモデルのコピーをして各GPUへ配布します。
- 各GPUでモデルをトレーニングした結果よりCPUにビルドされたモデルを更新します。

図1:GPUでモデルをトレーニングする流れ
4. ML Engineの利用方法:
4.1 コマンドのフォーマット
ML Engineを利用するためにGoogle Cloud Accountの申請が必要です。申請の方法がGoogle Cloudの公式サイトに参考してください。
ML EngineでJobをSubmitするコマンドを説明します。
|
1 |
gcloud ml-engine jobs submit training {<em><strong>job_id</strong></em>} --stream-logs --job-dir {<strong><em>job_dir</em></strong>} --runtime-version 1.10 --module-name trainer.task --package-path {<strong>code_dir</strong>} --region asia-east1 --scale-tier CUSTOM --config={<strong><em>configure</em></strong>} |
コマンドのFlagの説明が下記です。
- job_id: submitするジョブの名前です。この名前はユニークである必要があります
- –job-dir: Google Storgeでtemp directoryのURLです。
- –package-path: submitしたいジョブのソースコードの格納先です。
- –config: ML engineのInstanceの設定ファイルです。
4.2 設定ファイルのフォーマット
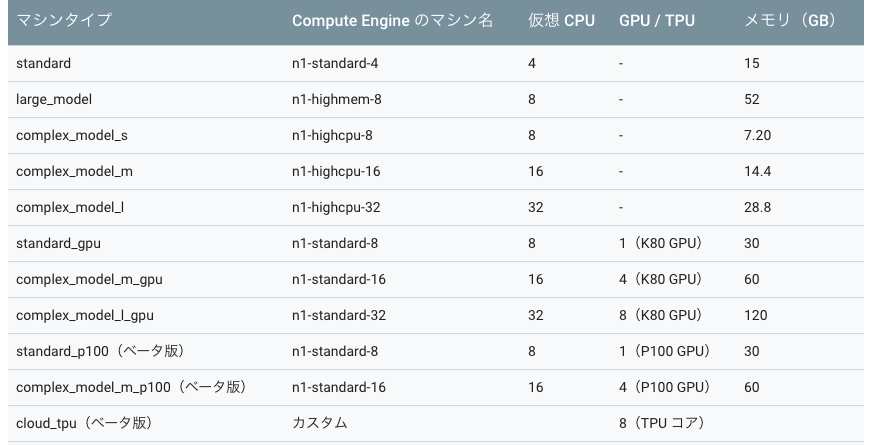
設定ファイルのフォーマットは下記です。scaleTierスケール階層(図2)です、今回の例でBASICを設定しました。インスタンスの種類 (図3)です。今回の例でcomplex_model_m_gpuを設定しました。
|
1 2 3 4 |
trainingInput: scaleTier: BASIC master_type: complex_model_m_gpu worker_count: 0 |

5.利用例:
今回はMNISTのデータを使って、マルチGPUで利用する例を作ってみました。MNISTは手書き数字画像(図3)70000枚を集めた画像データセットになります, その中に60000枚は学習データ、10000枚がテストデータに設定されています。

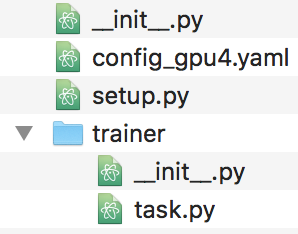
5.1ソースコードのファイル構造:
- –config_gpu4.yaml: ML engineのインステンスの設定ファイルです。
- –task.py: 実行するソースコードの本体です。
- –setup.py : ソースコードが依存するLibrayの初期化のScriptです。
5.2初期化のScript:
Kerasのモデルを保存するためにライブラリ h5pyが必要ですので初期化のScriptへh5pyを追加します。
|
1 2 3 4 5 6 7 8 9 10 11 |
from setuptools import find_packages from setuptools import setup REQUIRED_PACKAGES = ['h5py==2.7.0'] setup( name='mgpu', version='0.2', install_requires=REQUIRED_PACKAGES, packages=find_packages() ) |
5.3ソースコード:
Step1:使ってるLibarayをImportします。
|
1 2 3 4 5 6 7 8 |
import time import tensorflow as tf from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.utils import multi_gpu_model from tensorflow.keras.models import Model from tensorflow.keras.layers import Dense, Dropout, Activation, Input, MaxPooling1D,Conv2D, Reshape, Flatten, Dropout, Concatenate, Embedding, MaxPool2D from tensorflow.keras import Input |
Step2:MINISTのデータをダウンロードします。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
(x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(60000, 784) x_test = x_test.reshape(10000, 784) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1) # convert class vectors to binary class matrices y_train = tf.keras.utils.to_categorical(y_train, 10) y_test = tf.keras.utils.to_categorical(y_test, 10) |
Step3:インスタンスのGPU数を、環境情報から取得します。
|
1 2 3 4 |
def get_available_gpus(): from tensorflow.python.client import device_lib local_device_protos = device_lib.list_local_devices() return len([x.name for x in local_device_protos if x.device_type == 'GPU']) |
Step4:Kerasのモデルをbuildする。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def create_cnn(): inputs = Input(shape= (28, 28,1), dtype=tf.float32) output = Conv2D(128, kernel_size=(3, 3), activation='relu', input_shape= (28, 28,1))(inputs) output = Conv2D(128, (3, 3), activation='relu')(output) output =MaxPool2D(pool_size=(2, 2))(output) output = Conv2D(128, (3, 3), activation='relu')(output) output = Conv2D(128, (3, 3), activation='relu')(output) output = Conv2D(128, (3, 3), activation='relu')(output) output =Flatten()(output) output = Dense(128, activation='relu')(output) output = Dense(10, activation='softmax')(output) model = Model(inputs=[inputs], outputs=[output]) model.summary() return model with tf.device('/cpu:0'): model = create_model() parallel_model = multi_gpu_model(model, gpus=get_available_gpus()) parallel_model.compile(loss='categorical_crossentropy', optimizer='rmsprop') |
ソースコードで使ったモデルのレイアウトは下記です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_22 (Dense) (None, 28, 28, 512) 1024 _________________________________________________________________ conv2d_22 (Conv2D) (None, 26, 26, 128) 589952 _________________________________________________________________ max_pooling2d_14 (MaxPooling (None, 13, 13, 128) 0 _________________________________________________________________ conv2d_23 (Conv2D) (None, 11, 11, 128) 147584 _________________________________________________________________ max_pooling2d_15 (MaxPooling (None, 5, 5, 128) 0 _________________________________________________________________ dense_23 (Dense) (None, 5, 5, 512) 66048 _________________________________________________________________ dropout_10 (Dropout) (None, 5, 5, 512) 0 _________________________________________________________________ dense_24 (Dense) (None, 5, 5, 10) 5130 ================================================================= Total params: 809,738 Trainable params: 809,738 Non-trainable params: 0 _________________________________________________________________ |
Step5:Kerasのモデルをfitする。
|
1 2 3 4 |
start_time = time.time() history = parallel_model.fit(x_train, y_train, batch_size=batch_size, epochs=2, verbose=1, validation_data=(x_test, y_test)) cpu_time = time.time() - start_time print("Multiply GPU: --- %s seconds ---" % cpu_time) |
Step6:fitしたモデルを保存します:
マルチGPUのモデルを保存するには,multi_gpu_modelの返り値のモデルではなく,テンプレートになった(multi_gpu_modelの引数として渡した)モデルで.save(fname)か.save_weights(fname)を使ってください.
|
1 |
model.save("fited_model.h5") |
Step7:実行時間を比較するために同じモデルをSingle GPUで実行する部分も追加します:
|
1 2 3 4 5 6 7 8 9 10 11 |
start_time = time.time() model = create_model() model.compile(loss='categorical_crossentropy', optimizer='rmsprop') history = model.fit(x_train, y_train, batch_size=batch_size, epochs=2, verbose=1, validation_data=(x_test, y_test)) cpu_time = time.time() - start_time print("Single GPU: --- %s seconds ---" % cpu_time) |
6. 利用する流れ:
1 Google CloudのAccountを作る:
Google Cloudの公式サイトにGoogle CloudのAccountを作成します。
2 Google Storgeにジョブを実行するBuketを作る:
例で「gs://mgpu/ml_job_temp/」を作ります。
2 ML engineへジョブをsubmitする:
submitするコマンドは下記です。
|
1 |
gcloud ml-engine jobs submit training mgpu_32 --stream-logs --job-dir gs://segment-expansion-dev/ml_job_temp/mgpu_5/ --runtime-version 1.10 --module-name trainer.task --package-path ./trainer/ --region asia-east1 --scale-tier CUSTOM --config=./config_gpu4.yaml |
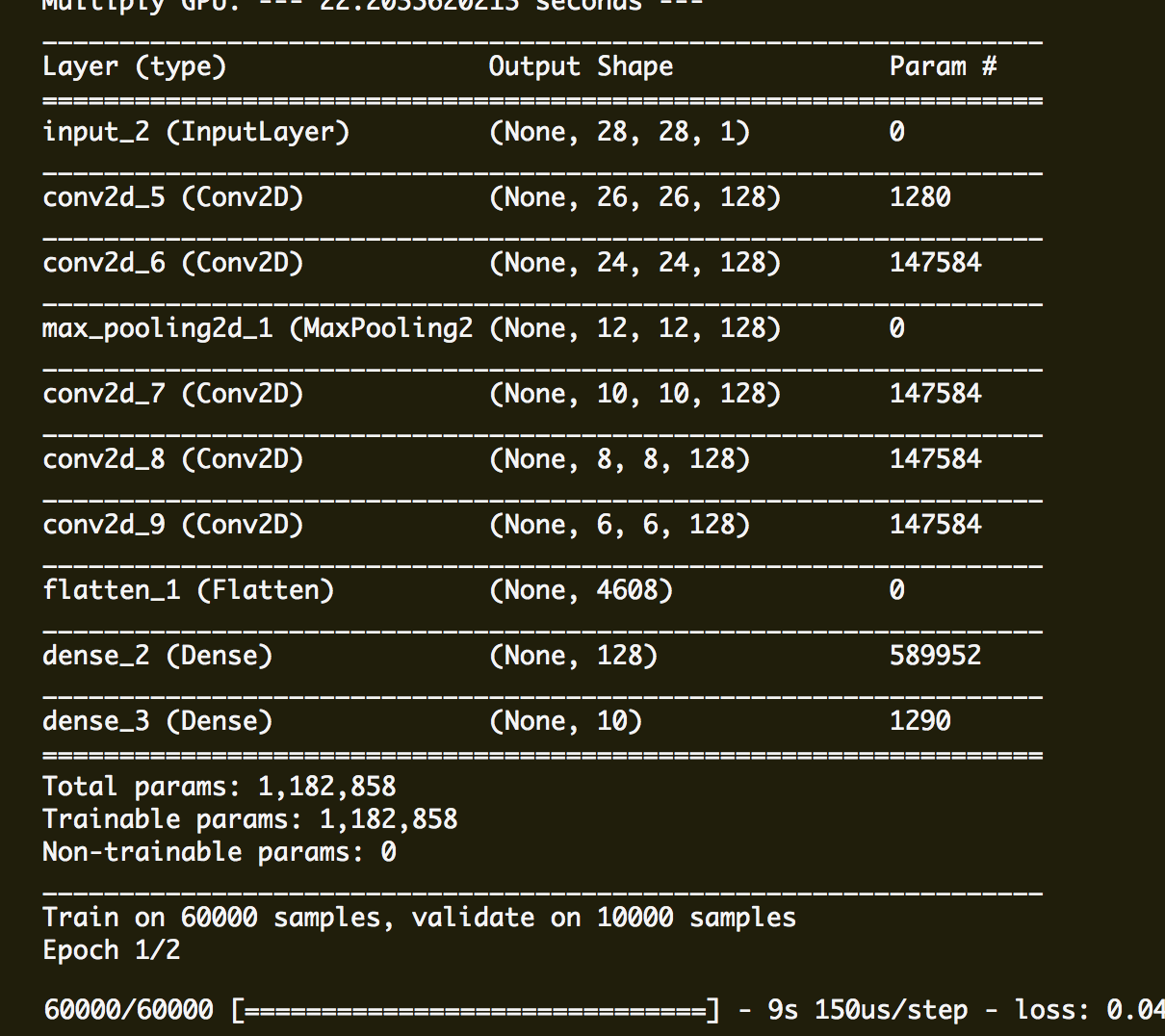
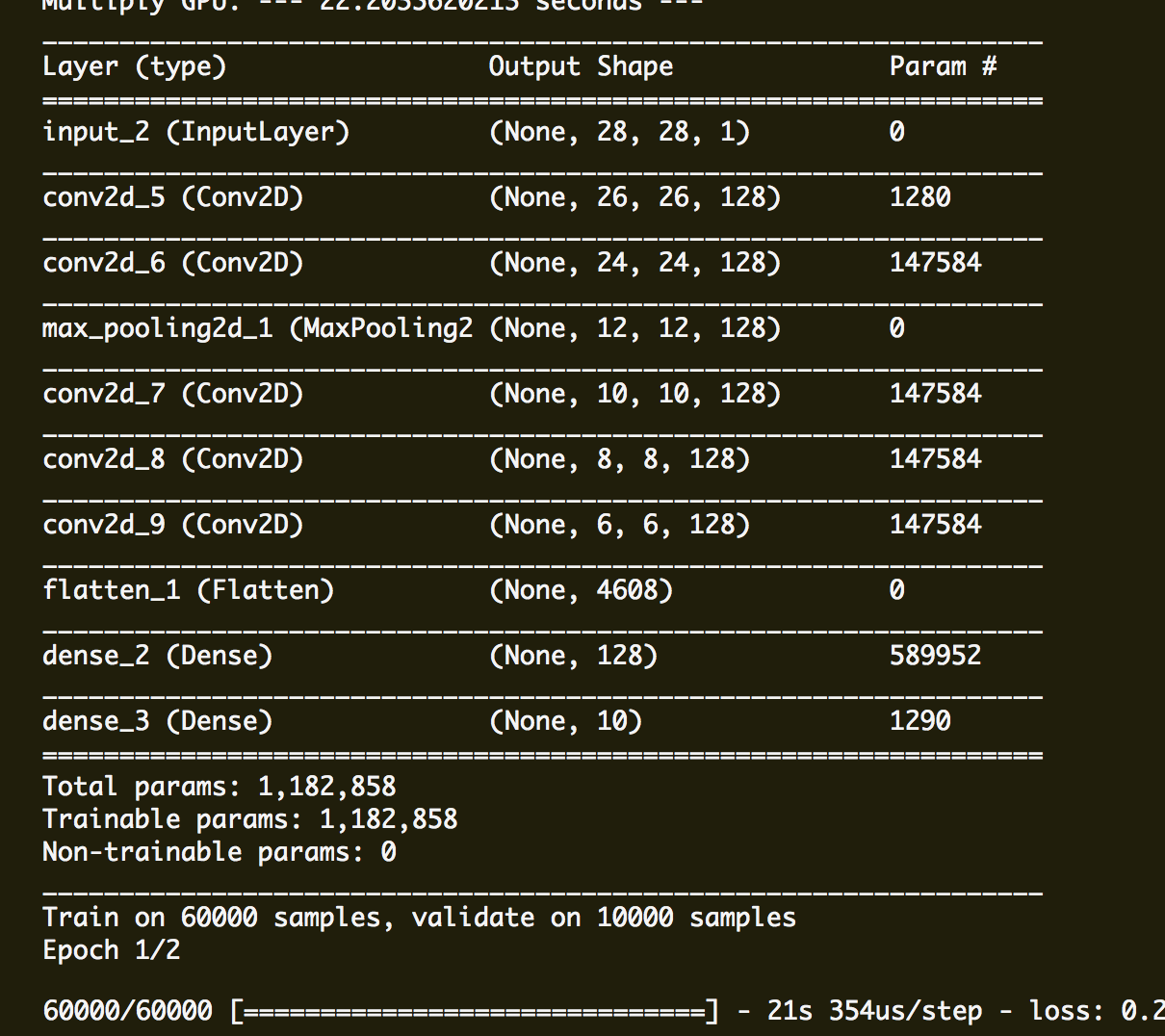
3.実行した結果:
実行した結果のログよりシングルGPUの実行する時間はマルチGPUの実行する時間より55%(21s ->9s)を改良できました。
7. まとめ
今回はKerasでマルチGPUをとってモデルのトレーニングを高速化する方法を紹介しました。いかがだったでしょうか。もし今回のブログが皆さんのディープラーニングの運用のお役に立てれば幸いです。



