
この記事は GMOアドマーケティングAdvent Calendar 2020 23日目の記事です。
みなさんこんにちは、GMOアドマーケティングのM.H.と申します。
突然ですがみなさんは機械学習する時にどのような環境で実行していますか?Google Colaboratoryでは、制限はありますが無料でTPUを使用し、高いパフォーマンスで学習を進めることができます。
今回はこのTPUを使って、モデル内のハイパーパラメータを自動で探索してくれるKeras Tunerを使っていく方法と注意点についてお話しします。
そもそも、TPUとは
TPU(Tensor Processing Unit)とは、Googleが開発した機械学習特化型のプロセッサのことで、基本的にGPUよりも高速で学習を進めることができます。計算量が多く、バッチサイズが大きい場合に特にその効果を発揮します。
私たちがこのパワーを使いたい場合、Cloud TPUというサービスで利用することができますが、これは有料でありお試しで使ってみたい方には少し壁を感じてしまうかもしれません。
しかし、Google Colaboratoryではなんと無料でこのTPUが利用できます。ColabはPythonを記述し、実行できる環境が整えられているため、まさに機械学習でTPUを動かしてみる環境にうってつけです。
※ ただし利用リソースに制限はあります。
Keras Tunerについて
Kerasで作られた学習モデル内で使うハイパーパラメータ(例えば、Adamの学習率など)を、自動で探索してくれるライブラリです。sklearnで作られた学習モデルに対しても探索はできますが、今回は触れません。
事前準備
Google Colaboratoryを開き、「ランタイム」>「ランタイムのタイプを変更」>「ノートブックの設定」から、「ハードウェア アクセラレータ」の項目を「TPU」に変更してください。

コード
早速コードを書いて実装してみます。
学習用のデータ整備
あらかじめKeras Tunerをインストールします。今回は、定番であるmnistのデータを用いていきます。訓練データと評価データとテストデータの3つに分けています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
!pip install -U keras-tuner import tensorflow as tf import numpy as np from tensorflow.keras.datasets import mnist from tensorflow.keras.utils import to_categorical from sklearn.model_selection import train_test_split # mnistのデータをダウンロードする (x_train, y_train), (x_test, y_test) = mnist.load_data() # 255で割り、kerasへの入力用にreshapeする x_train = (x_train.astype('float32') / 255.).reshape(-1,28,28,1) x_test = (x_test.astype('float32') / 255.).reshape(-1,28,28,1) # 正解ラベルをone-hotに変換 y_train = to_categorical(y_train) y_test = to_categorical(y_test) # 訓練データをから学習時の評価用データを分割する x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2) |
CNNモデルの構築
次に、Kerasを使ってCNNモデルを構築していきます。この時は自作のメソッドを定義し、引数には hp を指定してください。
探索したいハイパーパラメータは hp.xxx の形で指定します。ここでは例としてInt, Float, Choiceを使っています。メソッドの詳しい内容については公式ドキュメントがありますのでこちらを参考にしてください。
nameを同じに設定すれば同じ探索値が使われることに注意してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D from tensorflow.keras.optimizers import Adam from tensorflow.keras.utils import plot_model def my_model_parameter_search(hp): model = Sequential() model.add(Conv2D( hp.Int(max_value=128, min_value=16, step=8, name='Conv_1'), kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1), name='conv_1')) model.add(MaxPooling2D(pool_size=(2, 2), name='pooling_1')) model.add(Dropout( hp.Float(max_value=0.7, min_value=0.3, step=0.1, name='Dropout'), name='dropout_1')) model.add(Conv2D( hp.Int(max_value=64, min_value=8, step=8, name='Conv_2'), kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1), name='conv_2')) model.add(MaxPooling2D(pool_size=(2, 2), name='pooling_2')) model.add(Dropout( hp.Float(max_value=0.7, min_value=0.3, step=0.1, name='Dropout'), name='dropout_2')) model.add(Flatten(name='flatten')) model.add(Dense(128, activation='relu', name='dense')) model.add(Dropout(0.5, name='output_dropout')) model.add(Dense(10, activation='softmax', name='output')) model.compile( optimizer=Adam(hp.Choice('learning_rate', [1e-2, 1e-3, 1e-4])), loss='categorical_crossentropy', metrics=['accuracy']) return model |
TPUを使うための設定
Google ColaboratoryでTPUランタイムを使用するための各種設定をしておきます。3行目にある COLAB_TPU_ADDR は、ランタイムでTPUに設定していないと取得できません。7行目で使用できるTPUについての情報が表示され、 INFO:tensorflow:*** Available Device: _DeviceAttributes ... がたくさん出てくるはずです。
|
1 2 3 4 5 6 7 8 |
import os tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver("grpc://%s" % os.environ["COLAB_TPU_ADDR"]) tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) print("All devices: ", tf.config.list_logical_devices('TPU')) strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) |
GCSへのアクセス権限
後述しますが、Tunerクラスを定義する際にはGCSへのパスを指定する必要があります。そのため、GCSにアクセスするためGoogleアカウントで認証しなければなりません。
authenticate_user でアカウントに紐づいたコードを取得しコンソールに入力します。
|
1 2 3 |
# TPUを使ってKeras Tunerを動かすためにはGCSが必要なので、Googleの認証システムでコードを取得する from google.colab import auth auth.authenticate_user() |
Tunerクラスの定義
TunerクラスとしてRandomSearchクラスを定義していきます。他にはHyperbandやBayesianOptimizationクラスもあります。
このクラスには先ほど作成した自作の学習モデルメソッドを渡します。
注意点として
- directoryにはGCSのパスを指定する
- distribution_strategyには先ほど作成したstrategyを指定する
があります。TPUランタイムを使用する場合学習モデルの重み情報などはローカルに保存できないため、GCSに保存する必要があります。Keras Tunerでは各探索で重みを保存するためこのような設定をします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# RandomSearchでハイパーパラメータ探索をするためのモデルを作成する import kerastuner.tuners as ktt model = ktt.RandomSearch( my_model_parameter_search, objective='val_accuracy', max_trials=5, executions_per_trial=3, directory='gs://[任意のバケット名]', distribution_strategy=strategy,) # 作成したTuner modelの情報を表示する model.search_space_summary() |
ハイパーパラメータ探索
search メソッドを呼び出して実際にハイパーパラメータの探索を開始します。今回はコールバック関数としてEarlyStoppingと、出力クリアのための自作コールバックを指定していますが、設定はお好みです。
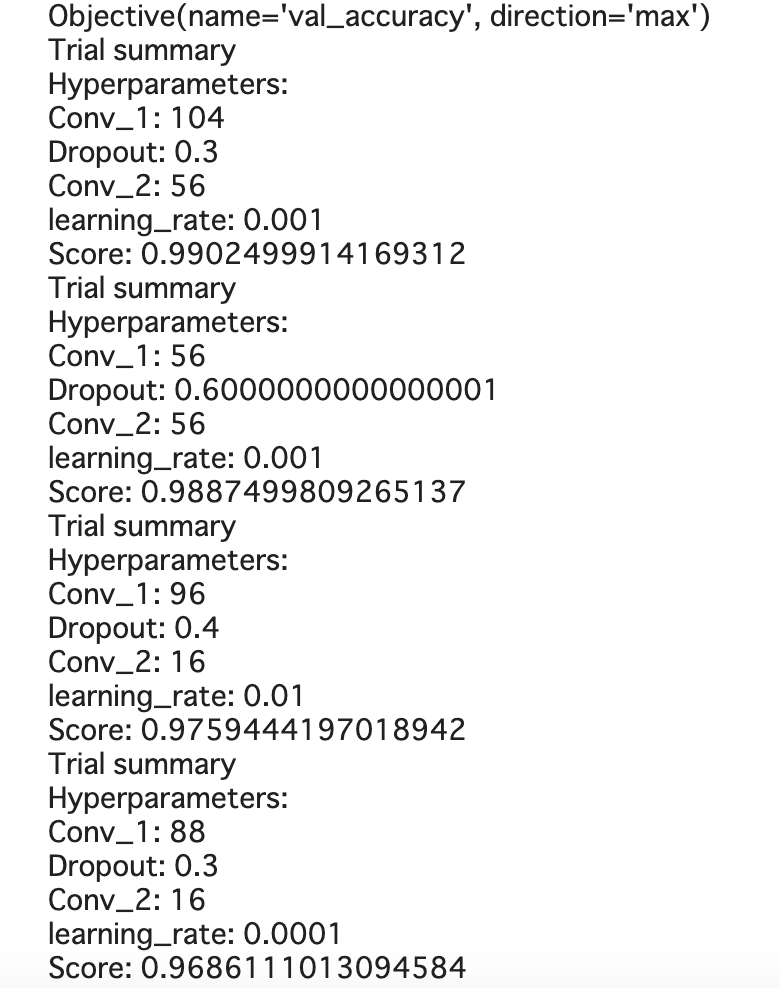
results_summary() で探索の結果を表示します。RandomSearchクラスを作成する際に指定したobjectiveの値が高い上位のパラメタ群が表示されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from tensorflow.keras.callbacks import EarlyStopping import IPython # 各訓練後に出力をクリアするためのコールバックを定義 class ClearTrainingOutput(tf.keras.callbacks.Callback): def on_train_end(*args, **kwargs): IPython.display.clear_output(wait = True) # 探索開始 model.search( x_train, y_train, batch_size=128, epochs=10, callbacks=[EarlyStopping(patience=1), ClearTrainingOutput()], validation_data=(x_val, y_val)) model.results_summary() |
以下のような出力がされ、探索の結果を簡単に確認することができます。
まとめ
今回は、簡単なCNNモデルをKerasで構築し、ハイパーパラメータの探索をGoogle ColaboratoryのTPUランタイムを使用しKeras Tunerで実行してみました。いかがだったでしょうか。
実際にはCNNよりもTPUが効果を発揮しやすいモデルなどありますが、今回は使ってみるということで簡単に触ってみました。更に使いこなしていきたいですね!
https://www.gmo-ap.jp/engineer/
■noteページ ~ブログや採用、イベント情報を公開中!~
https://note.gmo-ap.jp/


