
業務上使用できるかなと思い、Pythonのseleniumというライブラリを使用して広告レポートのダウンロードを自動化してみたので紹介いたします。
作業環境はWindowsで、ブラウザはGoogleChromeを使用しているので、その流れに沿って記載していきます。
※Pythonは事前にインストールされている前提で進めていきます。
seleniumとは
Selenium は Web ブラウザの操作を自動化するためのフレームワークで、WebアプリのテストやWebサイトのクローリングで使用されています。事前準備
seleniumのインストール
|
1 |
pip install selenium |
ChromeDriverのインストール
https://chromedriver.chromium.org/downloads上記URLから、インストールしているChromeのバージョンと同じChromeDriverのzipファイルをダウンロードする。 zipファイル解凍後、ファイル内のchromedriver.exeを任意のフォルダに配置する。
この時バージョンが異なったファイルをダウンロードしてしまうと、実行時にエラーになるので注意が必要です。
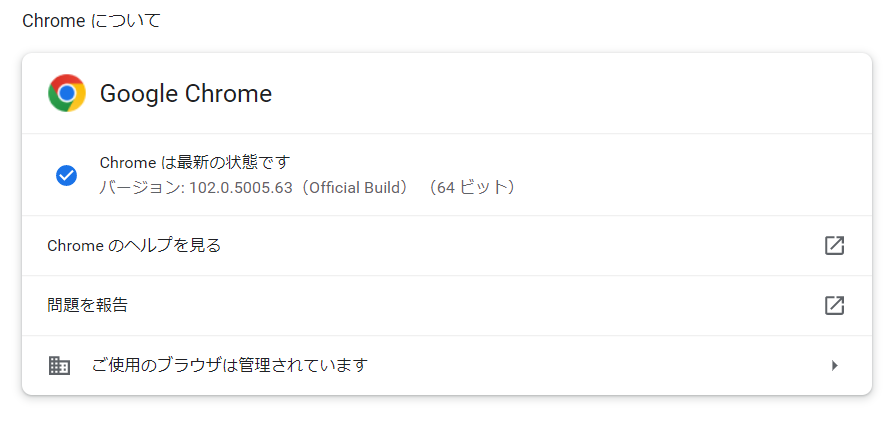
※ChromeのバージョンはChrome画面「設定」→「ヘルプ」→「Google Chromeについて」の順で確認可能です。

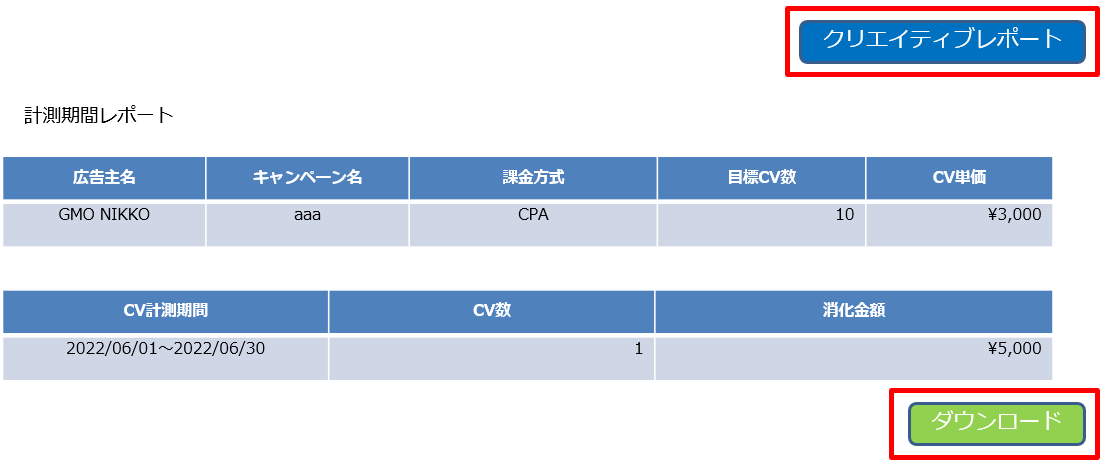
広告レポートのダウンロード
今回は某広告媒体のクリエイティブレポートを対象にレポートを取得しようと思います。※この事例はサービス提供元が自動化されたアクセスを許可している場合に限りご利用ください
下記の流れで処理を実行します。
①Chromeを開き、ログイン画面に遷移
②ログイン画面にアカウント情報を入力
③キャンペーン名を指定し、対象キャンペーンページに遷移
④「クリエイティブレポート」ボタンを選択
⑤「ダウンロード」ボタンを選択し、ダウンロード
※画像はイメージです
コード化したものがこちら
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
###対象キャンペーンのcsvファイルをダウンロードする from selenium import webdriver from selenium.webdriver.common.keys import Keys import time MAIL = 'xxxxx@xxxxx' PASS = 'xxxxx' CHROMEDRIVER = "C:/Users/xxxxx/xxxxx/chromedriver_win32/chromedriver.exe" #ドライバー指定でChromeブラウザを開く browser = webdriver.Chrome(CHROMEDRIVER) #遷移したい指定のURLへアクセス browser.get('https://xxxxx/xxxxx/xxxxx') #ログイン画面にメアド・passを入力 elem = browser.find_element_by_id('input-14') elem.send_keys(MAIL) elem = browser.find_element_by_id('input-18') elem.send_keys(PASS) elem.send_keys(Keys.RETURN) #キャンペーンを指定して対象画面へ遷移 browser.get('https://xxxxx/xxxxx/xxxxx') time.sleep(3) #「クリエイティブレポート」ボタンを押下 elem = browser.find_elements_by_tag_name('button')[3] elem.click() # #CSVファイルをダウンロードしてブラウザを閉じる time.sleep(3) elem = browser.find_elements_by_tag_name('button')[5] elem.click() time.sleep(3) browser.quit() |
※機密情報に係る部分は(xxxxx)で伏せてあります
解説
7,8行目では変数にアカウント情報を設定しています。15行目でChromeを開き、19行目で某広告媒体のログインURLを指定し、画面遷移しています。
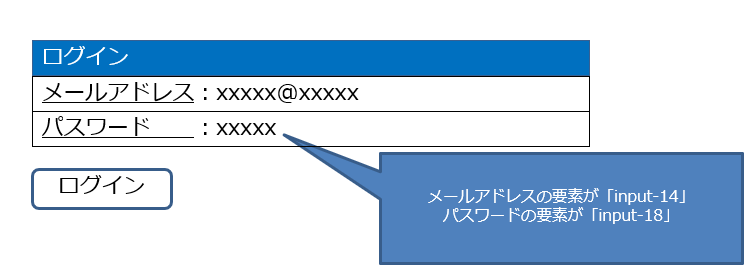
23,27行目に記載しているidは各アカウント情報を入力する際の要素を指定しています。
要素はデベロッパーツール(ブラウザでF12ボタン押下)から調べることが可能です。
※画像はイメージです
頻出しているtimeの部分に関してですが、URL遷移後3秒待機するという処理を行っています。
実装当初はなくてもいいかと思い、処理から削っていたのですが、この処理がないとURLの描画速度よりその後に実行する処理の方が早く、うまく処理を実行することができませんでした。
また、今回は処理が目に見える形で実装しているのでこのような内容になっていますが、処理を見えないようにするためにはheadlessオプションを使用することで画面裏で処理を実行してくれます。
まとめ
いかがでしたでしょうか。とても簡単にレポートの自動取得ができたのではないかと思います。
seleniumを使用した自動化は他にも様々な場面で活用できるのではないでしょうか。
しかし今回の件のみでいうと、実務としてダウンロードしたファイルを使用するには列の追加等ファイル内の加工が必要です。
次回はPandasを使用し、広告レポートファイル内のデータを加工してみようと思います。
ちなみに今回は解説用にコードを自作しましたが、Chromeの拡張機能で操作を録画して自動でコード作成もできますので非エンジニアの方でもより簡単に同じ作業が可能です。
(参考:https://kirinote.com/python-browser-record/)←参考URLは第三者のブログ記事ですので予めご了承下さい。
閲覧頂きありがとうございました。


