はじめまして。GMOアドマーケティングの t.k です。今回は機械学習の勉強にも使える kaggle についてのはじめの一歩になります。
kaggle とは企業や研究者がデータを投稿し、世界中のデータサイエンティストがその最適モデルを競い合うコミュニティです。日々さまざまなコンペティションが開催されており、中には企業が主催し成績優秀者に賞金を出すものもあれば、賞金は出ないがデータサイエンスの技術を学習するためにゲーム感覚で参加できるものもあります。
そして今回、学習用として用意されているコンペティションである、Titanic: Machine Learning from Disaster | Kaggle で予測をしてから回答を投稿するまでの実際の流れを試してみたいと思います。この記事では機械学習の手法などの細かい点には触れませんのでご了承ください。あくまで kaggle を試してみるという観点です。
ちなみにタイタニックはみなさんご存知かと思いますが、1912年に沈没した豪華客船タイタニック号のことであり、このコンペティションの目的は生存者を予測するといったものであります。また、機械学習といえばビッグデータを思い浮かべますが、今回の学習データは少ない件数なので普通のPCでも十分試すことが可能です。予測にはR言語を使用します。
データの取得
まず初めに予測に必要なデータを手に入れます。https://www.kaggle.com/c/titanic/data から train.csv と test.csv をダウンロードしてください。データ項目の説明もここにまとめられています。その他の gendermodel.csv や myfirstforest.py はサンプルになりますのでひとまず不要です。
ファイルをダウンロードしたら内容を確認してみましょう。train.csv とは学習用データのことであり、test.csv は予測対象データになります。変数は Survived が求めるべき目的変数、その他が説明変数(特徴量)です。そのため test.csv には目的変数の Survived(生存情報) がないことがわかります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
library(data.table) train = fread("../data/train.csv") head(train) ... PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 1: 1 0 3 Braund, Mr. Owen Harris male 22 1 0 A/5 21171 7.2500 S 2: 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0 PC 17599 71.2833 C85 C 3: 3 1 3 Heikkinen, Miss. Laina female 26 0 0 STON/O2. 3101282 7.9250 S test = fread("../data/test.csv") head(test) ... PassengerId Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Survived 1: 892 3 Kelly, Mr. James male 34.5 0 0 330911 7.8292 Q 0 2: 893 3 Wilkes, Mrs. James (Ellen Needs) female 47.0 1 0 363272 7.0000 S 0 3: 894 2 Myles, Mr. Thomas Francis male 62.0 0 0 240276 9.6875 Q 0 ... |
ジェンダーモデルによる推定
とりあえず提出フォーマットの確認も兼ねて、データのダウンロードページにもサンプルがあるジェンダーモデルで簡単に生存者を予測したいと思います。女性は生存(Survived=1)、男性は死亡(Survived=0)とするだけの単純なモデルです。なぜ性別を使うのかというと生存確率の差が大きいからですね。
提出フォーマットのヘッダー付き PassengerId + Survived でCSVファイルを作成します。
|
1 2 3 4 5 |
submission = data.frame(PassengerId = test$PassengerId) submission$Survived[test$Sex=="female"] = 1 submission$Survived[test$Sex=="male"] = 0 write.csv(submission, file = "../data/submission_1.csv", row.names=FALSE, quote=FALSE) |
ファイルが出来たら https://www.kaggle.com/c/titanic/submissions/attach から提出しましょう。
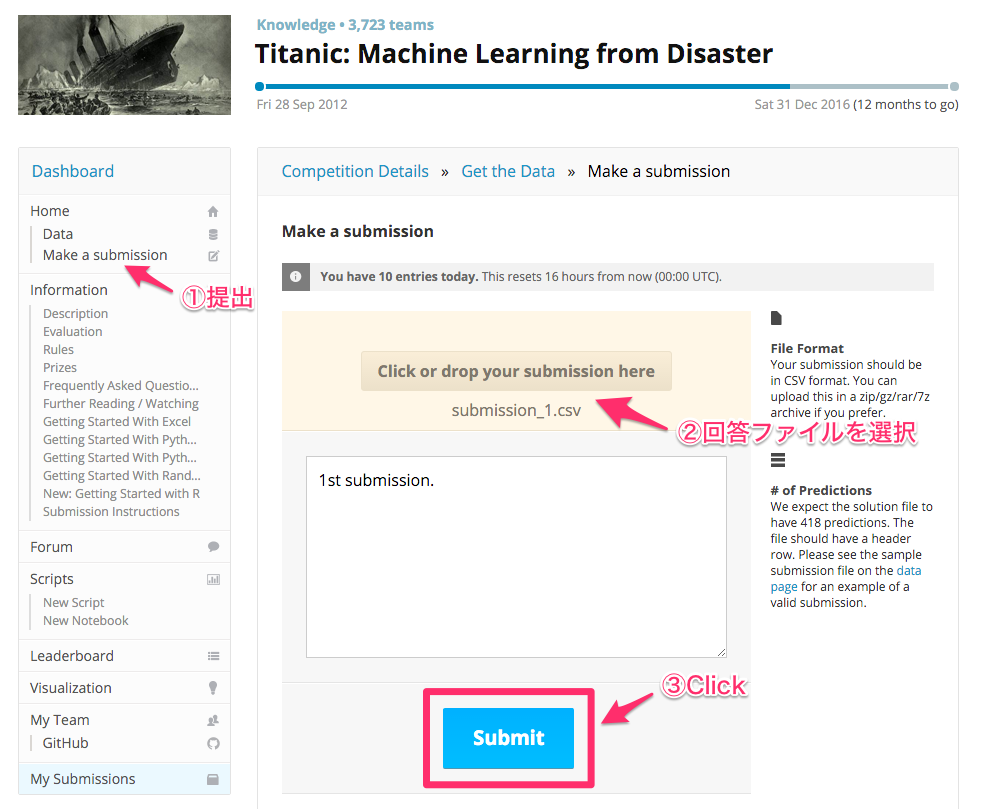
少し待つと結果が出ます。76.555%の正解率で3,724人中3,089位でした。Kaggleでは、コンペによって使われている指標が異なりますが、タイタニックでは正解率が指標となっています。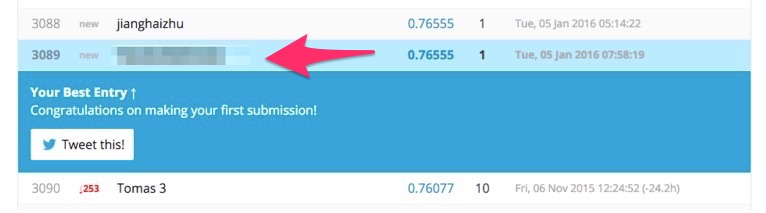
ランダムフォレストによる推定
続いてはランダムフォレストで予測をしたいと思います。ランダムフォレストとは識別・回帰・クラスタリングに用いることができる、決定木を弱学習器とする集団学習アルゴリズムです。シンプルなのに高速・高精度であるという特長を併せ持つと一般的に言われています。
まずは説明変数をランダムフォレストが処理可能な形に変換します。機械学習アルゴリズムは数値データを前提としているものが多いので、通常、カテゴリデータは数値データに変換する必要がありますが、ランダムフォレストに関してはカテゴリデータもそのまま扱えます。(カテゴリ数が多いとダメ)ただし、名前に関してはそのままだとカテゴリ数が多くて使用できないので、影響が大きそうな敬称のみ抽出して使用したいと思います。Cabin は欠損値が多いので今回は除外しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
featureExtract = function(data) { feature = data[, c("Pclass","Sex","Age","SibSp","Parch","Fare","Embarked"), with=FALSE] feature[, Sex:=factor(Sex)] feature$Age[is.na(feature$Age)] = -1 feature$Fare[is.na(feature$Fare)] = median(feature$Fare, na.rm=TRUE) feature$Embarked[feature$Embarked==""] = "S" feature[, Embarked:=factor(Embarked)] feature$Title = "Other" feature$Title[grep("Mr\\.", data$Name)] = "Mr" feature$Title[grep("Mrs\\.", data$Name)] = "Mrs" feature$Title[grep("Mme\\.", data$Name)] = "Mrs" feature$Title[grep("Miss\\.", data$Name)] = "Miss" feature$Title[grep("Mlle\\.", data$Name)] = "Miss" feature$Title[grep("Ms\\.", data$Name)] = "Miss" feature$Title[grep("Master\\.", data$Name)] = "Master" feature$Title[grep("Dr\\.", data$Name)] = "Dr" feature$Title[grep("Rev\\.", data$Name)] = "Rev" feature[, Title:=factor(Title)] return(feature) } |
それではモデルを作成して予測を実行しましょう。
|
1 2 3 4 5 6 |
library(randomForest) rf = randomForest(featureExtract(train), as.factor(train$Survived), ntree=100, importance=TRUE) submission = data.frame(PassengerId = test$PassengerId) submission$Survived = predict(rf, featureExtract(test)) write.csv(submission, file = "../data/submission_2.csv", row.names=FALSE, quote=FALSE) |
再度結果を提出すると、スコア79.426%の1,401位までランクアップしました。82%以上で100位以内に入れるようです。
まだランダムフォレストにデータを突っ込んだだけなので、実際はここからが腕の見せ所という感じでしょうか。説明変数なんかはまだまだチューニングの余地がありそうなので、変数の関係を考えながらやると面白いかもしれません。これであなたも kaggler です!
※ブログ掲載のプログラムのインストールは、自己責任で御願いします。インストール等の結果にかかるハードウェアの不稼働等は、 当ブログでは一切サポートしておりませんので、予め御了承下さい。


