
はじめまして。GMOアドマーケティングのMHです。
機械学習が流行っていますが、何から手を付けたら良いのかわからないという方は多いのではないでしょうか
私も最近勉強を始めたのですが、数式を見ていても中々イメージが掴みづらいのですが、実際に動く環境があると理解の進みが早かったです。
なので、まずは機械学習を簡単に動かせる環境の構築をするのがおすすめです。
今回は機械学習の環境の構築と簡単な機械学習の実行をしてみたいと思います。
あまり馴染みが無いかもしれませんが、機械学習関係のライブラリが充実しているPythonをベースに環境を構築していきます。
Anacondaとは
![]()
Continuum Analytics社によって提供されている、Pythonのディストリビューションの一つです。
Python本体に加えて、機械学習/数値計算で利用する主要なライブラリをまとめてインストールすることが出来るため、データサイエンティストなどがよく利用するディストリビューションとなります。
Anacondaのインストール
それでは実際にAnacondaをインストールしてみましょう
Pythonのバージョンは2.x系と3.x系を選べますが、ライブラリ等の対応もされてきており、新規にインストールする場合は3.x系を選択することが多いため、今回は3.x系をインストールしています。
Windows環境の場合
公式ページからダウンロード後、インストーラに従ってインストールを行ってください。
Mac環境の場合
Windowsと同様に公式ページからダウンロードすることも可能ですが、pyenvを利用してのインストールがおすすめです。
pyenvのインストールにHomeBrewを利用しますので、もしインストールされていない方はHomeBrew公式ページを参照してインストールを行ってください。
では、pyenvを利用したインストールについて解説します。
1. pyenvのインストール
anacondaを直接インストールする前に、同一PC上で複数環境の切替を行うことの出来るpyenvをインストールします。
|
1 2 3 4 5 |
$ brew install pyenv $ echo 'export PYENV_ROOT="${HOME}/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="${PYENV_ROOT}/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profile |
※デフォルトシェルにbashを利用していない方は環境変数の設定先を適宜変更してください。
2. anacondaのインストール
pyenvを経由してanacondaをインストールします。
|
1 2 |
$ pyenv install anaconda3-4.2.0 $ pyenv global anaconda3-4.2.0 |
以上にてanacondのインストールは完了です
実際にインストールが成功しているかを確認してみましょう
|
1 2 |
$ python --version Python 3.5.2 :: Anaconda 4.2.0 (x86_64) |
上記のようにAnacondaと表示されればインストール成功です。
これにて機械学習環境の構築は完了です。お疲れ様でした。
機械学習を試してみよう
それでは実際に、簡単なサンプルを動かしてみましょう
機械学習のライブラリはscikit-learnをメインで利用します。
scikit-learnとは
![]()
scikit-learnはPythonで実装をされているオープンソースの機械学習ライブラリです。
サポートベクターマシン、ランダムフォレスト、Gradient Boosting、k近傍法などの分類や回帰、クラスタリングアルゴリズムが数多くの機能が実装されています。
このライブラリはAnacondaに含まれていますのでインストールなどは不要です。
データの分類をしてみよう
scikit-leanを利用してデータを分類してみましょう。
分類のアルゴリズムとしてはパーセプトロンを利用します。
パーセプトロンとは視覚と脳をモデル化したニューラルネットワークの一種です。
シンプルなネットワークながらも学習が行えるアルゴリズムのため、機械学習の基礎となる概念を学ぶことが出来ます。
パーセプトロンを動かしてみよう
それでは実際に動かしてみましょう
pythonを起動して対話モードにしましょう
|
1 2 |
$ python >>> |
ライブラリの読み込み
まずは、利用するライブラリを読み込みます。
数値計算用にnumpyをグラフ描画用にmatplotlibを読み込みます。
パーセプトロンを利用するため、scikit-leanのパーセプトロンモジュールを読み込みます
|
1 2 3 |
import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import perceptron |
サンプルデータの用意
サンプルのデータを用意します。
機械学習などでよく利用されるデータにアヤメの花びらとがくの長さがあります。
今回はがくの長さと幅のデータを利用してサンプルデータを作成しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# インプットとしてがくの長さ、幅を定義 inputs = np.array( [ [ 1.5, 0.4], [ 1.5, 0.1], [ 1.9, 0.2], [ 1.7, 0.4], [ 1.6, 0.2], [ 4.9, 1.5], [ 4.6, 1.5], [ 4.7, 1.6], [ 3.3, 1.0], [ 3.9, 1.4], ]) |
上記サンプルデータは前半と後半とで品種が違っており、前半の5個がsetosa、後半の5個がversicolorとなっています。
サンプルデータを分類するためにsetosaに対しては0をversicolorに対しては1を割り振ります。
|
1 2 |
# ラベルとして品種を設定 labels = np.array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1 ]) |
サンプルデータの可視化
サンプルデータが品種ごとに偏りが見て取れるかをグラフにして見てみましょう
matplotlibを利用してグラフを描画します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 品種ごとにプロット plt.scatter(inputs[:5,0], inputs[:5,1], marker="o", c="gray", label="setosa") plt.scatter(inputs[5:,0], inputs[5:,1], marker="x", c="green", label="versicolor") # グラフの縦横のラベルを設定 plt.xlabel('Petal length') plt.ylabel('Petal width') # グラフの上限と下限を設定 plt.xlim(0, 6) plt.ylim(0, 2) # 左上に凡例を表示 plt.legend(loc='upper left') # グラフ表示 plt.show() |
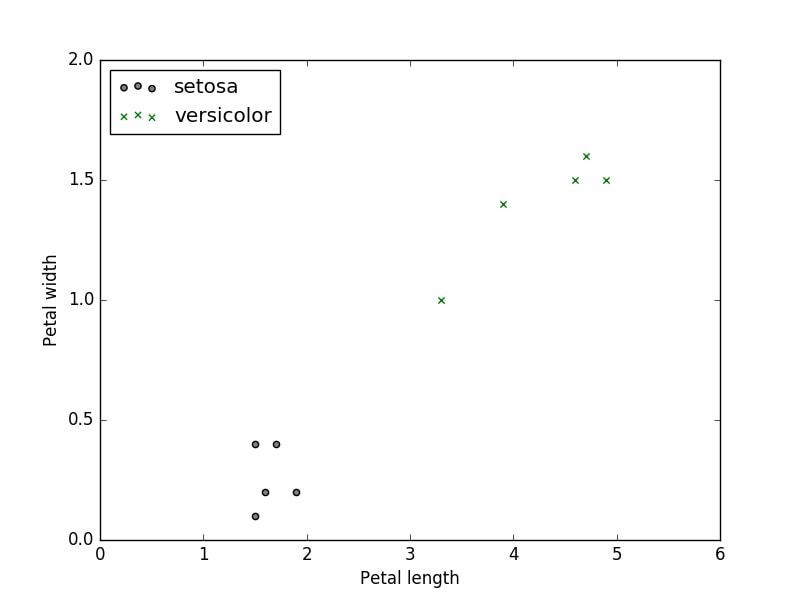
こちらを実行すると以下のグラフが表示されます。
サンプルデータが少ないですが何となく真ん中あたりで分類できそうな気がしますね。
学習をしてみましょう
それでは用意したサンプルデータを利用して分類をしてみましょう
学習自体はscikit-leanのパーセプトロンモジュールを呼び出すだけです。
|
1 2 3 4 |
# パーセプトロンのインスタンス生成 clf = perceptron.Perceptron(n_iter=100, eta0=0.002) # サンプルデータと対応する品種のラベルを渡して学習 clf.fit(inputs,labels) |
学習の結果を確認してみましょう
学習結果を元にサンプルデータ以外でもどのように分類されるかを確認してみましょう
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from matplotlib.colors import ListedColormap # 最大値と最小値の間の数値を0.01刻みで算出 SS, VV = np.meshgrid(np.arange(0.0, 6.0, 0.01), np.arange(0.0, 2.0, 0.01)) # 上記の数値を学習結果を元に判別 Z = clf.predict(np.array([SS.ravel(), VV.ravel()]).T) Z = Z.reshape(SS.shape) # 判別結果をグラフに設定 colormap = ListedColormap(('gray', 'green')) plt.contourf(SS, VV, Z, alpha=0.3, cmap=colormap) # サンプルデータをプロット plt.scatter(x=inputs[:5, 0], y=inputs[:5, 1], c=colormap(0), marker="o", label="setosa") plt.scatter(x=inputs[5:, 0], y=inputs[5:, 1], c=colormap(1), marker="x", label="versicolor") # グラフの縦横のラベルを設定 plt.xlabel('Petal length') plt.ylabel('Petal width') # グラフの上限と下限を設定 plt.xlim(0, 6) plt.ylim(0, 2) # 左上に凡例を表示 plt.legend(loc='upper left') # グラフ表示 plt.show() |
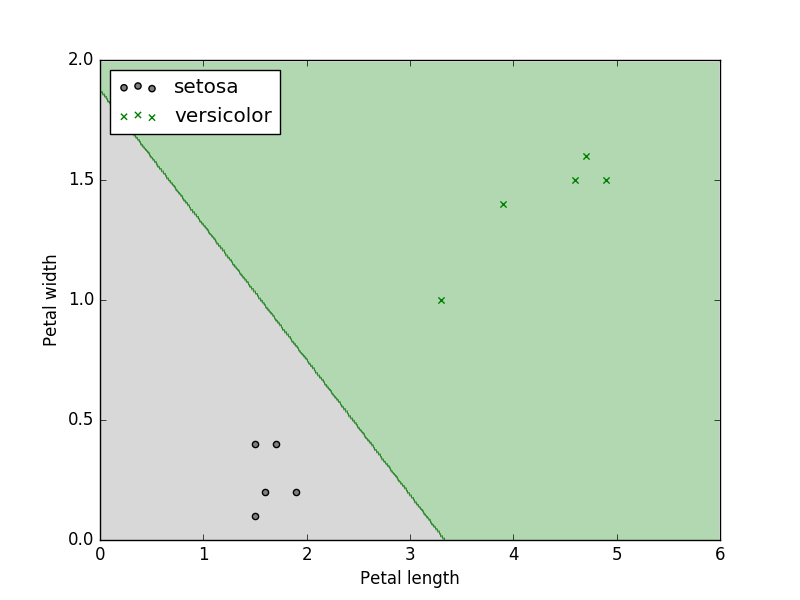
こちら実行した結果になります。
いい感じに2つに分類できていますね。
まとめ
今回は機械学習を勉強をする上でベースとなる環境の構築と実際に簡単なサンプルで学習を試してみました。
今回は紹介をしきれませんでしたがAnacondaにはPythonの実行環境jupyterも含まれています。
こちらを利用すると手軽に実行をすることが出来ますので機会があれば紹介をしたいと思います。


