
こんにちは、CTO室のA.Zです。最近、AkaNeの配信最適化の解析プロジェクトに参加しています。
今回、一部の最適化方法、ユーザーペルソナ(性別・年齢)予測について話したいと思います。
背景
AkaNeで、もっと広告配信効率化するため、ユーザーの特徴(性別・年齢)を分析し、
効果が高いユーザーに広告配信できることが今回のプロジェクトの目的です。
ユーザーペルソナ(性別・年齢)予測について
ユーザーペルソナ(年齢・性別)の予測というのは様々なユーザー行動履歴から、ユーザーの年齢・性別を予測することです。
利用する行動履歴データは以下のデータです。
- ページアクセス履歴
どんなサイトにアクセスするか、いつアクセスするか、ブラウザー情報何なのかなど - その他のアクションデータ
予測するユーザーペルソナの内容は以下の表のとおりです。
| ユーザーペルソナ類 | カテゴリ |
| 性別 | 男性
女性 |
| 年齢 | 25歳以下
25歳-35歳 35歳-45歳 45歳以上 |
上記のデータから、ユーザーのペルソナを予測するために、今回ランダム フォレストという機械学習アルゴリズムを使っています。
ランダム フォレストは複数の決定木から構成され(フォレスト)、各決定木で利用されるデータはランダムでデータセットからサンプリングされます。
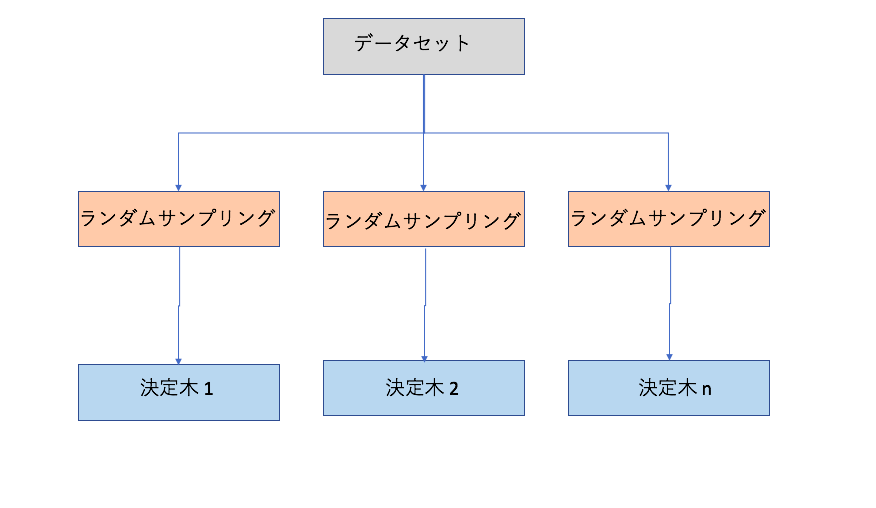
ランダム フォレスト手法の詳細については下記の論文が元にになっています。
L. Breiman. Random forests. Machine learning, 45(1):5–32,2001.
ランダム フォレストを選定した理由は以下です。
- 今回の予測、完全に0,1の予測(Hard Classification)ではなく、確率のような予測(Fuzzy Classification)が要件です。
ランダム フォレストは、複数決定木からの「vote数/決定木数」値を利用することで、この要件はクリアーすることができます。 - ランダム フォレストはデータノイズに対して、強いです。
こちらはノイズ 除去のコストを削減することができます。 - ランダム フォレストは様々なデータの種類(数値、カテゴリなど)が対応することができます。
今回使っているデータはカテゴリデータが多いため、ランダム フォレストだと、そのまま利用することができます。
今回のプロジェクトでは、データ量が大きいため、分散処理のフレームワーク Apache Sparkを利用しています。
ランダム フォレスト手法もSpark MLlibが提供しているアルゴリズムを利用しています。
続いて、今回見つかった一つの問題はアクションデータの価値が高いですが、利用できるデータが少ない(全ユーザーの約10%)です。
アクセス履歴とアクションデータが一緒に学習すると、サンプリングする時にアクションデータがあまり抽出されませんでした。
その結果、アクションデータに対して、学習は不十分でした。
こちらの問題を解決するために、学習プロセスと予測プロセスは二つに分けます。
アクセス履歴のみのモデル
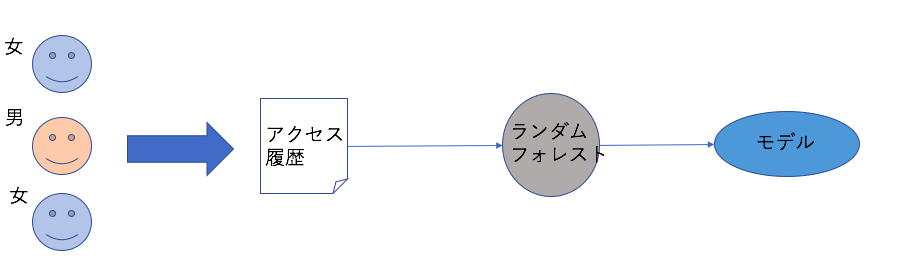
こちらのモデルはアクセス履歴のみ持っているユーザーに適用します。だいたい90%ユーザーの予測はこちらモデルを利用しています。
学習プロセスは以下の図のとおりです。
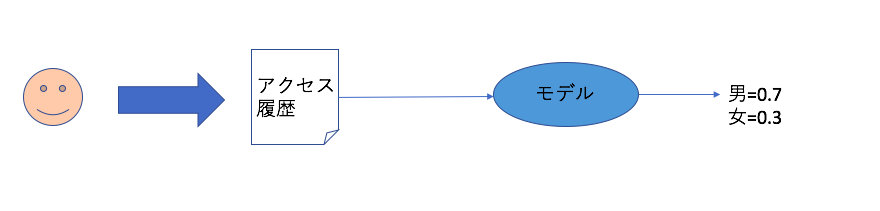
予測プロセスは以下の図のとおりです。
アクセス履歴+アクションデータのモデル
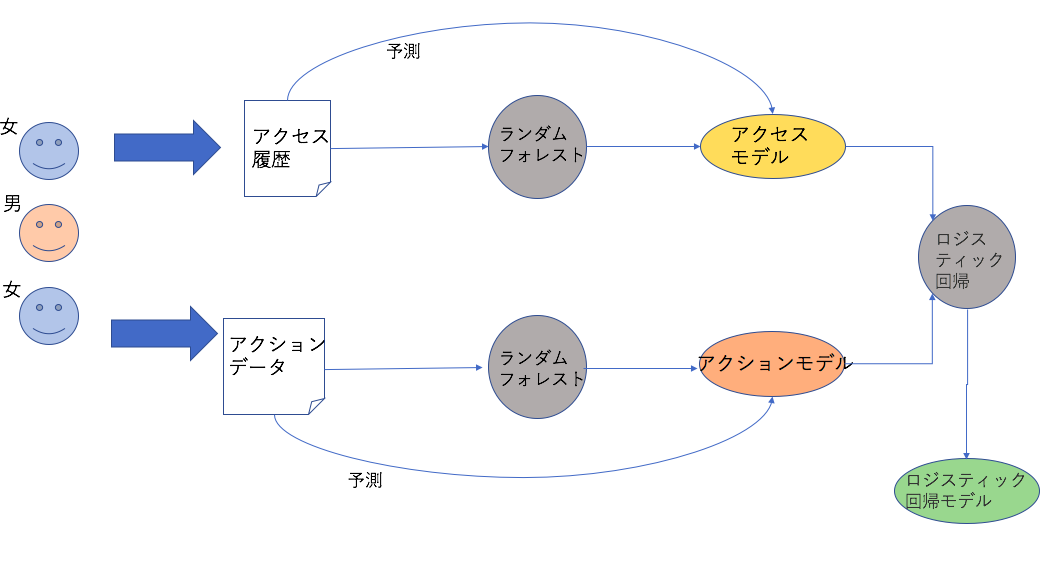
こちらのモデルはアクションデータを持つユーザーに適用します。アクセス履歴のデータはユーザーのベース情報になっていますので、全ユーザーはアクセス履歴のデータが必ず持っています。
具体的なプロセスはそれぞれアクセス履歴のモデルとアクションデータのモデルを作成し、そして、作成したモデルを利用し、正解データを予測します。予測した正解データの結果をさらにロジスティック回帰のモデルに流して、各モデル(アクセスモデル、アクションモデル)の重みを計算します。
具体的な学習プロセスは以下の図のとおりです。
具体的な予測プロセスは以下の図のとおりです

結果と考察
上記のアプローチで、予測した性別情報を利用することで、中立サイト(ユーザーペルソナの偏りがほとんとないサイト)のeCPM(広告1000回表示またはアクセス1000ページビューあたりの収益額)は12.6%改善することができました。性別と年齢の情報を組み合わせると、もっと改善できるのではないかと思います。
また、今回のアプローチではコンテンツ解析の手法を使っていません。コンテンツ解析手法を使うと、もっと改善できるのではないかと思います。
今後、コンテンツ解析やもっと高度な機械学習の手法を利用して、精度や効果を改善していきたいと思います。
日本に住んでいるインドネシア人です。現在、主にビッグデータとデータ解析関連業務をやっています。


