
こんにちは。GMO NIKKO エンジニアのN.I.です。
今回はCloud Storage(GCS)から自動でBigQueryにCSVデータを取り込む仕組みを作成したので紹介します。
BigQueryにCSVデータを取り込む場合は、Cloud Storageにデータをアップしてbq loadコマンドを実行してロードするのが一般的だと思います。
また、CloudFunctionsにはCloud StorageにCSVデータをアップするとアップされたことを検知する機能があります。
この2つの機能をうまく組み合わせれば、自動でデータを取り込めるのではないかというのが今回の内容です。
簡単な図にすると以下の様になります。
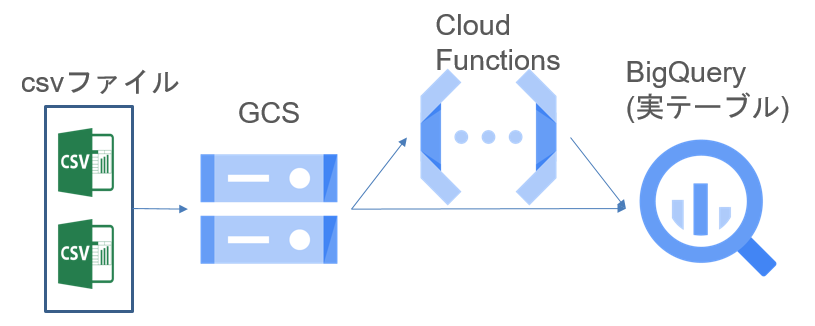
事前準備
- GCSにバケットを作成し、作成したバケットにフォルダを作成する。
- bigquery.confを作成する。
- bigquery.jsonを作成する。
- 作成したbigquery.conf、bigquery.jsonをバケットのフォルダにアップする。
- Cloud Functionsを作成する。
処理手順
- CSVファイルをGCSにアップする。
- Cloud FunctionsがCSVファイルをアップされたことを検知する。
- Cloud FunctionsがGCSにアップされたconfファイル(bigquery.conf)、jsonファイル(bigquery.json)を読み込む
- Cloud FunctionsがBigQueryを確認し、confに記載された表が無い場合はBigQueryに表を作成する。
- Cloud Functionsでbq loadコマンドを実行しGCSにアップしたcsvファイルをBigQueryにロードする。
- 完了したcsvファイルをGCSのold/フォルダに移動する。
では実際に事前準備をしてcsvの自動取り込みの手順について説明します。
今回は下記の様なcsvファイルをGCSにアップしてBigqueryのテーブルにloadする例で記載します。
|
1 2 3 4 |
ID,メールアドレス,氏名 1,aaa@gmonikko.jp,日光一郎 2,bbb@gmonikko.jp,日光次郎 3,ccc@gmonikko.jp,日光三郎 |
事前準備を実施します。
1.バケットの作成、フォルダの作成
バケットの作成で「データの保存場所の選択」時にBigQueryのDataSetのリージョンと同じリージョンに作成してください。バケット名は何でも大丈夫です。
※bq loadコマンドはGCSのバケットとBigqueryのデータセット同一リージョンでないと動作しないようです。別リージョンだと失敗してハマリます。
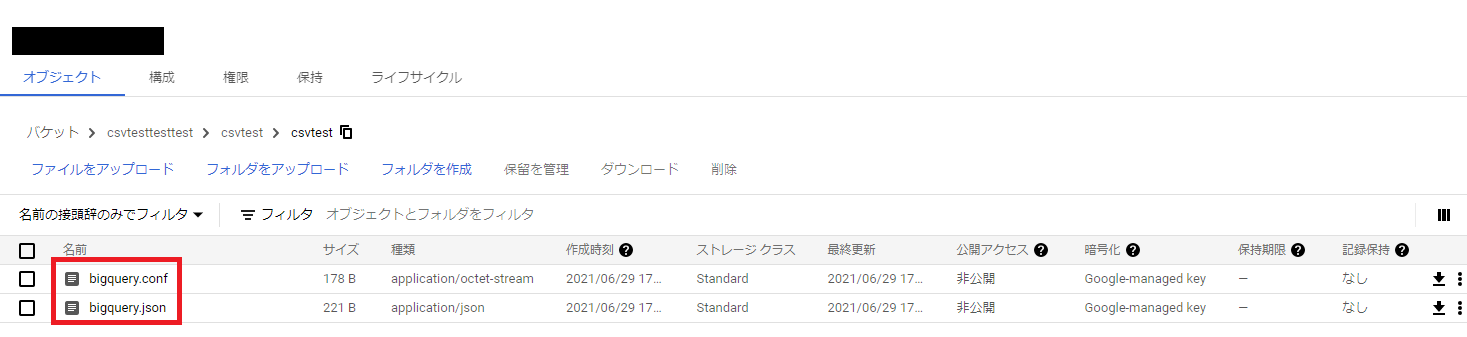
バケットを作成したら、バケットにフォルダを作成して、bigquery.conf、bigquery.jsonをフォルダに配置します。
bigquery.conf、bigquery.jsonはbq loadコマンドを実行する時に必要な情報を記載します。
ファイルの中身は下記説明を参考に作成してください。
2.bigquery.confの作成
下記の内容を記載します。
SkipReadingRows : CSVのヘッダーを読み飛ばす行数の設定します。BigQueryに1行目をloadしない場合は1、1~3行目をloadしないなら3を記載します。
ProjectId : GCPのプロジェクトIDを記載してください。BigQueryの表を特定するために使用します。
DatasetName : BigQueryのDataSet名を記載してください。BigQueryの表を特定するために使用します。
TableName : BigQueryの表名を記載してください。BigQueryの表を特定するために使用します。
bigquery.conf 記載例 (記載情報はダミーです。実際の弊社で使用している環境の情報とは違います。)
|
1 2 3 4 |
SkipReadingRows = 1 ProjectId = nktest DatasetName = csvtest TableName = testtable |
3.bigquery.jsonの作成
jsonファイルの内容はcsvに準拠したBigQueryのテーブルのスキーマ情報になります。
このjson情報がテーブルの構造の情報になります。このファイルの作成方法が分からない場合はGCPの公式ドキュメントをご確認ください。
下記ページ「テーブルスキーマの操作」-「スキーマの指定」-「JSON スキーマ ファイルの作成」の項目参照
https://cloud.google.com/bigquery/docs/schemas?hl=ja#specifying_a_json_schema_file
今回のcsvに合わせてjsonファイルを作成すると下記の様な内容になります。
bigquery.json 記載例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[ { "name": "id", "type": "INT64", "mode": "NULLABLE" }, { "name": "mail", "type": "STRING", "mode": "NULLABLE" }, { "name": "name", "type": "STRING", "mode": "NULLABLE" } ] |
4.bigquery.conf、bigquery.jsonのアップ
ファイルを作成したらGCSのフォルダにアップします。
5.Cloud Functionsの作成
次にCloud Functionsの設定をします。
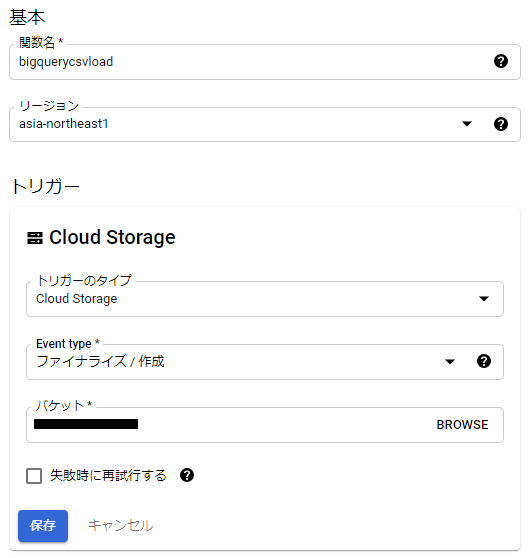
CloudFunctionで関数作成をクリックして下記情報を設定します。
関数名 : 任意
リージョン : BigqueryのDataSetのリージョンと合わせる
トリガータイプ : Cloud Storage
Event type : ファイナライズ/作成
バケット : 作成したバケットを選択
設定例
設定が完了したら[保存]をクリックし[次へ]をクリックします。
ランタイムでPython3.9を選択します。
requirements.txtを記載します。
cloud storageAPIと、bigqueryAPIのパッケージを追加します。
|
1 2 3 4 |
# Function dependencies, for example: # package>=version google-cloud-storage == 1.39.0 google-cloud-bigquery == 2.20.0 |
main.pyにプログラムを記載します。
設定はbigquey.comfの方に記載済みなのでそのまま貼り付ければ動くはずです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 |
from google.cloud import bigquery from google.cloud import storage from collections import OrderedDict import json def hello_gcs(event, context): file = event bucket_name = event['bucket'] file_name = event['name'] print(f"Processing file: {file['name']}.") print('Bucket: {}'.format(event['bucket'])) print('File: {}'.format(event['name'])) cs_client = storage.Client() bq_client = bigquery.Client() #oldフォルダ以外のcsvファイルのみ処理開始 if event['name'].startswith('old/') == False and event['name'].endswith('csv') == True: csvfile_name = '' confile_name = '' jsonfile_name = '' #bucket直下に置いた場合とバケットにフォルダを作成して置いた場合の分岐 if '/' in file_name: #フォルダ名の取得 folder_name = file_name.rsplit('/',1)[0] #CSVファイル名取得 csvfile_name = file_name confile_name = folder_name + '/bigquery.conf' jsonfile_name = folder_name + '/bigquery.json' else: csvfile_name = file_name confile_name = 'bigquery.conf' jsonfile_name = 'bigquery.json' #confファイル読込 conf_file_text = download_text(cs_client, bucket_name, confile_name) lines = conf_file_text.splitlines() skipleading_rows = '' project_id = '' dataset_name = '' table_id = '' for line in lines: if ('SkipReadingRows' in line): skipleading_rows = line.rsplit('=',1)[1].strip() if ('ProjectId' in line): project_id = line.rsplit('=',1)[1].strip() if ('DatasetName' in line): dataset_name = line.rsplit('=',1)[1].strip() if ('TableName' in line): table_name = line.rsplit('=',1)[1].strip() #table_idの作成 table_id = project_id + '.' + dataset_name + '.' + table_name #jsonファイル読込 json_file_text = download_text(cs_client, bucket_name, jsonfile_name) json_load = json.loads(json_file_text, object_pairs_hook=OrderedDict) job_config = csvloadjobjsonconfig(json_load,skipleading_rows) #table_nameで指定したテーブルが無かった場合テーブル作成 if table_exists(bq_client, project_id + '.' + dataset_name, table_name) == False: table = table_create(bq_client, table_id , job_config.schema) #Bigqueryにデータロード uri = 'gs://' + bucket_name + '/' + csvfile_name load_job = bq_client.load_table_from_uri(uri, table_id, job_config=job_config) load_job.result() #処理が完了でcsvファイルをoldフォルダに移動する mv_files(cs_client, bucket_name , csvfile_name , 'old/' + csvfile_name ) def download_text(cs_client, bucket, filepath): bucket = cs_client.get_bucket(bucket) blob = storage.Blob(filepath, bucket) bcontent = blob.download_as_string() try: return bcontent.decode("utf8") except UnicodeError as e: print('catch UnicodeError:', e) return "" # ファイル移動 # bucket バケット名 def mv_files(cs_client, bucket,blob_name, new_name): bucket = cs_client.bucket(bucket) blob = bucket.blob(blob_name) new_blob = bucket.rename_blob(blob, new_name) return new_blob #Bigqueryテーブル存在判定 def table_exists(bq_client, dataset_id, table_name): tables = bq_client.list_tables(dataset_id) for table in tables: if table_name == table.table_id: return True return False #Bigqueryテーブル作成 def table_create(bq_client, table_id, schema): table = bigquery.Table(table_id, schema=schema) ret = bq_client.create_table(table) return ret #csvロード用configの作成(jsonファイル専用) def csvloadjobjsonconfig(jsonload, skipleadingrows): schema = [] for schematmp in jsonload: schema.append(bigquery.SchemaField(schematmp['name'], schematmp['type'],mode=schematmp.get('mode',""),description=schematmp.get('description',""))) job_config = bigquery.LoadJobConfig() job_config.source_format = bigquery.SourceFormat.CSV job_config.skip_leading_rows = skipleadingrows job_config.schema = schema return job_config |
完了したら、[デプロイ]をクリックします。
これで準備完了です。
実際に処理手順を実行する為にフォルダにcsvファイルをアップしてみましょう。
csvファイルをアップしてから3分以内には読み込みが始まります。
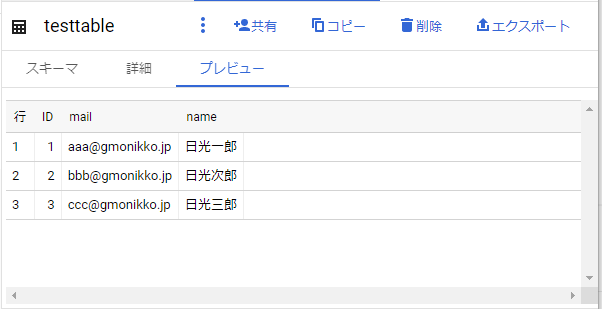
csvファイルがフォルダから消えたら作業完了です。BigQueryを確認しましょう。

BigQUeryを確認すると新規テーブルが作成され、csvデータが登録されたことを確認出来ます。
以上で今回のご紹介はこれで完了です。
今回のご紹介からはソースが複雑になってしまう為削除させて頂きましたが、実稼働させる場合は弊社の場合下記のような調整が必要となりましたので、参考の為に一応記載いたします。
- 日付データをアップする場合はYYYY-MM-DD形式ではないとbq loadが動かないので、csvの日付データをYYYY-MM-DD形式に加工する機能。
- csvの文字コードがutf-8じゃないとBigqueryに取り込めない為csvをutf-8に変換する機能。
- 日付データが重複するデータを取り込む場合にcsvの日付のMAX値と、MIN値を把握してBigQuery上からwhere句でdeleteする機能。
- BigQueryに主キーは無いけど主キーに相当する列でcsvデータと重複するデータをBigQuery上からwhere句でdeleteする機能。
あまりGCPでの構築例を紹介している記事が少ないので参考になれば幸いです。


