
今回はオフライン評価について調べてみました。
0.オフライン評価とは?
過去に集めたアクセスログなどの蓄積データを利用して、過去の施策とは別の施策を適用した場合、どのような結果となるかをオフラインで評価する方法です。施策を決めるための意思決定モデルを変更するのは手間とリスクがありますが、オフライン評価ならば既存システムに改修を加えずに新しい意思決定モデルを評価することが可能です。1.オフライン評価の手順
オフライン評価を行うには以下のような手順を実施します。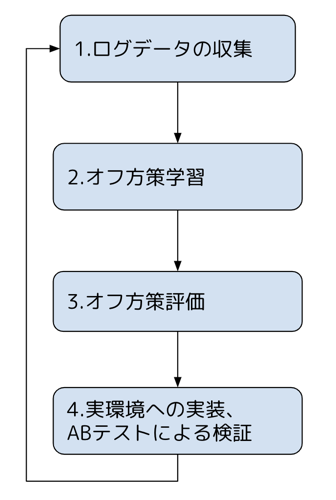
2.オフ方策学習で実施すること
蓄積データをもとに施策を決定するための新たな意思決定モデルの学習(Off-Policy Learning; OPL)を行ないます。ここでの目的は既存システムの意思決定モデルの性能を上回る新たな意思決定モデルを得ることです。意思決定モデルの例
バンディットアルゴリズム…Webサイトなどの改善を行う手法の総称。スロットマシンがその語源で、「スロットマシンが複数台あるとき、限られたコインをどの台にどれだけ使えば最大の成果が得られるか」を計算する手法。人間のような学習能力をコンピューターに持たせる機械学習の手法。A/Bテストの自動化を図る目的においても利用されます。
3.オフ方策評価で実施すること
新たな意思決定(policy)の性能をアクセスログなどの過去の蓄積データを用いて推定することをオフ方策評価(Off-Policy-Evaluation:OPE)と呼びます。意思決定モデルの行動選択が一致している場合、観測される目的変数を正解データとして利用して新たな意思決定の性能を評価することができます。なお蓄積データにある特徴(例: 性別、年代、時間帯など)による偏りがある場合、補正するためのデータを水増しするなどの操作を行うことがあります。これをバイアスの補正といいます。| ユーザID | 過去の蓄積データでの行動 | 観測される目的変数 (例:クリックの有無など) | 新しい意思決定モデルが選択した行動 | 意思決定モデルの行動選択が一致しているか |
| A | 3 | 0 | 2 | × |
| B | 1 | 0 | 1 | ◯ |
| C | 1 | 1 | 3 | × |
| D | 1 | 0 | 1 | ◯ |
| E | 2 | 1 | 1 | × |
| F | 1 | 0 | 2 | × |
| G | 3 | 1 | 3 | ◯ |
4.オフ方策評価でのバイアスの補正方法
バイアスを補正するための手法としては以下があります。| 手法 | 説明 |
| リプレイメソッド | 本番環境で一定量ランダム配信を行ってオフ方策評価用の蓄積データを収集します(ランダムなデータが得られるので補正の必要がありません) |
| 逆確率重み付け Inverse Probability Weighting(IPW) | 背景情報(性別、年齢など)から予測される施策を受ける確率のことを傾向スコアと呼びます。逆確率重み付けでは蓄積データを傾向スコアの逆数で重みづけしてデータを水増ししてバイアスを補正します。 |
| 二重頑健推定 Doubly Robust(DR) | 逆確率重み付けの欠点(傾向スコアを算出するモデルの精度が低く傾向スコアを用いた解析法では誤った結果を与える可能性があるなど)を改善した手法です。 |
5.まとめ
オフライン評価の概要についてご紹介しました。オフライン評価は有用な技術だと思いますので今後も継続して内容を把握し、実業務に利用したいと考えています。参考
執筆にあたり以下を参考にさせていただきました。「施策デザインのための機械学習入門」
斎藤雄太 + 安井翔太著 株式会社ホクソエム監修(技術評論社)


