はじめに
こんにちは。GMO NIKKOのshunkiです。当記事は次の記事に触発されて書いています。よろしければ先にご覧ください。

この記事では、複数文字列の探索について、正規表現よりもトライ木を使った方が速いことを確かめます。最初に問題設定を共有します。次に忙しい人向けにベンチマークの結果を発表します。実装言語に関する注意を挟んで、力まかせな実装を提示します。続いて、正規表現について簡単に説明し、正規表現を使った実装を提示します。同様に、トライ木について簡単に説明し、トライ木を使った実装を提示します。最後に、ベンチマークで利用したデータとコマンドをお見せします。
問題設定:指定の単語を含む行を取り除きたい
入力ファイルから指定の単語を含む行を取り除き、別のファイルに出力することを、この記事での問題設定とします。ただし、指定の単語は複数個あります。1つでも単語を含んでいれば行を取り除きます。
例えば、入力ファイルが下記のように”aaa”, “aab”, … と行が並んでいるとします。また、指定された単語が”ab”, “bc”, “ca”であったとします。この時、出力ファイルは”aaa”, “aac”, “baa”, “bac”の行が並んだファイルになります。
| 入力 | 単語 | 出力 |
|---|---|---|
| aaa | ab | aaa |
| aab | bc | aac |
| aac | ca | baa |
| abc | bac | |
| aca | ||
| baa | ||
| bab | ||
| bac | ||
| bbc | ||
| bcc |
この問題設定だと適切なオプションを指定したgrepコマンドが最速な気もしますね。ただ、grepコマンドの調査はしていません。読者の中にシェル芸人がいらっしゃれば、圧倒的速度を見せつけていただけると嬉しいです。
結果発表:正規表現が速いです。でも、トライ木はもっと速いです
忙しい人向けに結果から示します。次の表は、入力ファイルと単語の4つの組み合わせについて、それぞれの実装(力まかせ、正規表現、トライ木)に対する手元の環境での実行時間を記載した表です。
最も大きな入力に対して、「正規表現」は「力まかせ」の約8倍も高速です。同様に、「トライ木」は「正規表現」の約20倍も高速です。つまり、「トライ木」は「力まかせ」の約160倍も高速になります。この結果だけ見ると、「力まかせ」はとにかく遅いことがわかります。「正規表現」も健闘していますが、「トライ木」の安定した速さには届いていません。
| 入力行数 | 単語数 | 力まかせ | 正規表現 | トライ木 |
|---|---|---|---|---|
| 4,046 | 3,412 | 3秒04 | 2秒85 | 0秒51 |
| 4,046 | 88,329 | 1分36秒 | 38秒71 | 1秒43 |
| 124,523 | 3,412 | 2分48秒 | 35秒80 | 24秒71 |
| 124,523 | 88,329 | 58分38秒 | 6分58秒 | 21秒46 |
実装言語に関する注意:マイナーな言語で実装したのでコメントだけ読めばOK
次節以降で処理の概要と具体的なコードを示していきます。実装言語はPowerShellです。読み書きできる人はそう多くないでしょう。コードの各処理を説明するコメントを書いたので、処理を追う場合はコメントを読んでください。
ちなみに個人的嗜好でPowerShellを選んでいます。何も準備せずに使い始められる道具が私は好きです。Windows OSさえあれば環境構築不要で.NET Frameworkの標準ライブラリが使えるPowerShellは何かと重宝しています。
力まかせ(brute-force)な実装:各行に対して、単語を1つづつ調べる
入力の各行に対して、各単語が含まれているか1つづつ調べていく単純明快な方法です。単語が含まれているかはString.Containsメソッドを使って調べています。Containsメソッドはある文字列が別の文字列内に存在するかを教えてくれるメソッドです。
問題設定の節に書いた例で言えば、1行目の”aaa”に対して、"aaa".Contains("ab")、"aaa".Contains("bc") 、"aaa".Contains("ca")と調べます。”aaa”の中に”ab”, “bc”, “ca”が存在しないことをContainsメソッドが教えてくれます。結果として、”aaa”はそのまま出力されます。 一方、”aab”の中に”ab”が存在する事をContainsメソッドが教えてくれるので、2行目の”aab”は出力されません。
力まかせなコードは次のとおりです。Test-Containsは各単語が含まれているか1つづつ調べていく関数です。Measure-Containsは実行時間を計測するベンチマーク用の関数になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 入力行$Stringに対して、 # 単語集$Wordsの単語が含まれているか1つづつ調べる filter Test-Contains([string]$String, [string[]] $Words) { # 単語$wが1つでも入力行$Stringに含まれていれば、 # 真($true)を返す foreach ($w in $Words) { if ($String.Contains($w)) { return $true } } # すべての単語が入力行に含まれていなかったので、 # 偽($false)を返す return $false } # 力まかせな実装のベンチマーク filter Measure-Contains([string] $InPath, [string] $WordsPath, [string] $OutPath) { # Measure-Commandで実行時間を取得する $timespan = Measure-Command { # 前処理:単語集をファイルから読み込む $words = @(Get-Content $WordsPath) # 主処理: # 入力ファイルの各行について、 # Test-Containsで単語が含まれていない行のみを抽出し、 # 出力先のファイルに書き込む Get-Content $InPath | Where-Object {-not (Test-Contains $_ $words)} | Out-File $OutPath -Encoding Default } # 実行時間を表示する Write-Host $timespan.ToString() } |
正規表現を使った実装
正規表現とは:文字列を処理するスゴ技
正規表現は強力かつ柔軟に文字列を処理できる応用力の高い技術です。正規表現は奥が深いため、詳細に触れると説明が長くなってしまいます。ここでは実装を追うのに必要な概念の紹介に留めておきます。
正規表現は、複数の文字列(文字列の集合)を簡潔に表す式です。例えば、文字列のab|bcをPowerShell(.NET)の正規表現として解釈すると、「文字列”ab”または文字列”bc”」の意味になります。
ここで、”a”, “b”, “c”の各文字はそのまま文字として解釈されており、正規表現として特別な意味は持ちません。そのまま文字として解釈される文字をリテラルと呼びます。一方で”|”は「または」という意味が与えられています。正規表現として特別な意味を持つ文字をメタ文字と呼びます。
メタ文字をそのまま文字として解釈させたい場合は、エスケープします。例えば文字列のab¥|bcをPowerShellの正規表現として解釈すると、「”ab|bc”という文字列」の意味になります。つまり、メタ文字”|”がエスケープされています。
正規表現の利用法は多岐にわたります。もちろん、文字列が別の文字列に含まれているかも判定できます。前節で取り上げたContainsメソッドもそのような判定ができました。しかし、Containsはある1つの文字列が含まれているか判定するメソッドです。一方で、文字列の集合を表す正規表現は、複数の文字列が含まれているか一括で判定できます。
ところで、式を正規表現として解釈し、様々な処理を実現するプログラムを正規表現エンジンと呼びます。正規表現エンジンが式を解釈(コンパイル)する際にわずかに時間がかかります。そのため、同じ式を何度も解釈させる無駄を省きたいことがあります。そのような場合、PowerShellではコンパイル結果を再利用するプログラムを明示的に書きます。PHPはコンパイル結果を暗黙にキャッシュ(一定数を記憶)してくれるため、自動的に再利用されます。
実装:各行について、いくつかの単語をまとめて調べる
いくつかの塊(チャンク)に単語を分けます。塊ごとに単語を「または」を表す|で繋げて1つの正規表現にまとめます。入力の各行に対して、正規表現ごとに単語が含まれているか調べる実装です。
問題設定の節に書いた例で言えば、正規表現ab|bc|caのいずれの文字列も1行目の”aaa”に含まれないため、”aaa”はそのまま出力されます。 一方、正規表現ab|bc|caの”ab”が2行目の”aab”に含まれているため、”aab”は出力されません。なお、塊の大きさを2とした場合、ab|bcとcaに分けて正規表現が作られます。
正規表現を使ったコードは次のとおりです。Join-RegexOrが指定数の塊にまとめて正規表現へ事前コンパイルする関数です。Test-RegexOrが正規表現ごとに一括で単語が含まれているか調べる関数です。Measure-RegexOrは実行時間を計測するベンチマーク用の関数になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
# パイプラインで入ってくる単語を、 # 規定数$Chunkでまとめて正規表現にコンパイルする function Join-RegexOr([int] $Chunk) { Begin { # 単語を累積しておく空のリストを作成 $list = [System.Collections.Generic.List[string]]::New() # 正規表現のコンパイルオプションを取得しておく $compiled = [System.Text.RegularExpressions.RegexOptions]::Compiled } Process { # パイプライン経由で入ってきた文字列を、 # エスケープしてリストに追加する $list.Add([regex]::Escape($_)) # リストの大きさが規定数以上になった場合 if($list.Count -ge $Chunk) { # '|'で結合し、正規表現へコンパイルして # 後続のパイプラインへ流す [regex]::New(($list -join '|'), $compiled) # 出力済みなので、 # 累積していたリストを空っぽにする $list.Clear() } } End { # 残りを'|'で結合し、正規表現へコンパイルして # 後続のパイプラインへ流す [regex]::New(($list -join '|'), $compiled) } } # 入力行$Stringに対して、 # 正規表現に一致する単語が含まれているか1つづつ調べる filter Test-RegexOr([string] $String, [regex[]] $Regexs) { # 正規表現$rにまとめられた単語が # 1つでも入力行$Stringに含まれていれば、 # 真($true)を返す foreach ($r in $Regexs) { if ($r.IsMatch($String)) { return $true } } # すべての単語が入力行に含まれていなかったので、 # 偽($false)を返す return $false } # 正規表現を使った実装のベンチマーク filter Measure-RegexOr([string] $InPath, [string] $WordsPath, [string] $OutPath, [int] $Chunk = 100) { # Measure-Commandで実行時間を取得する $timespan = Measure-Command { # 前処理:単語集をいくつかまとめて正規表現にコンパイルする $regexOr = @(Get-Content $WordsPath | Join-RegexOr $Chunk) # 主処理: # 入力ファイルの各行について、 # Test-RegexOrで単語が含まれていない行のみを抽出し、 # 出力先のファイルに書き込む Get-Content $InPath | Where-Object {-not (Test-RegexOr $_ $regexOr)} | Out-File $OutPath -Encoding Default } # 実行時間を表示する Write-Host $timespan.ToString() } |
トライ木を使った実装
トライ木とは:頭から共通する文字をまとめた木
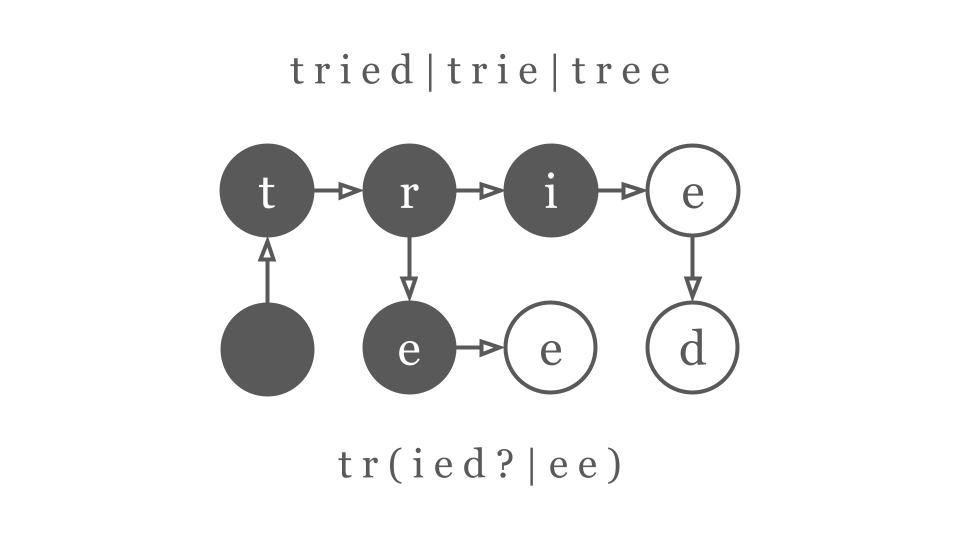
小中学校で習った分配法則を覚えているでしょうか。a×b+a×c=a×(b+c)といったように、数式を括弧にまとめたり展開したりする時に使える法則です。実は、正規表現でも分配法則が成り立ちます。例えば、ab|acとa(b|c)は同じ正規表現とみなせます。なぜなら、「文字列”ab”または文字列”ac”」と「”a”の後に(”b”または”c”)が続く文字列」は同じ意味だからです。細かいことを言えば、括弧はグループ化の意味を持っています。ただ、今回の問題設定でグループ化を気にする必要はありません。安心して分配法則を使ってください。
他にも交換法則や結合法則を習いましたね。a+b+c=c+b+aといったように、項の順番を調整する際に使える法則です。交換法則や結合法則も正規表現で成り立ちます。例えば、a|b|cとc|b|aは同じ正規表現とみなせます。なぜなら、「”a”または”b”または”c”」と「”c”または”b”または”a”」は同じ意味だからです。
正規表現hg|bde|bdg|bc|hgg|a|bdf|hにこれらの法則を適用すると、次のように変形できます。最初に交換法則と結合法則で辞書式順序で並べ替えて、共通する文字を頭から分配法則でくくっています。
hg|bde|bdg|bc|hgg|a|bdf|ha|bc|bde|bdf|bdg|h|hg|hgga|b(c|de|df|dg)|h(|g|gg)a|b(c|d(e|f|g))|h(|g(|g))
と言われても、わかりづらいので図にしましょう。
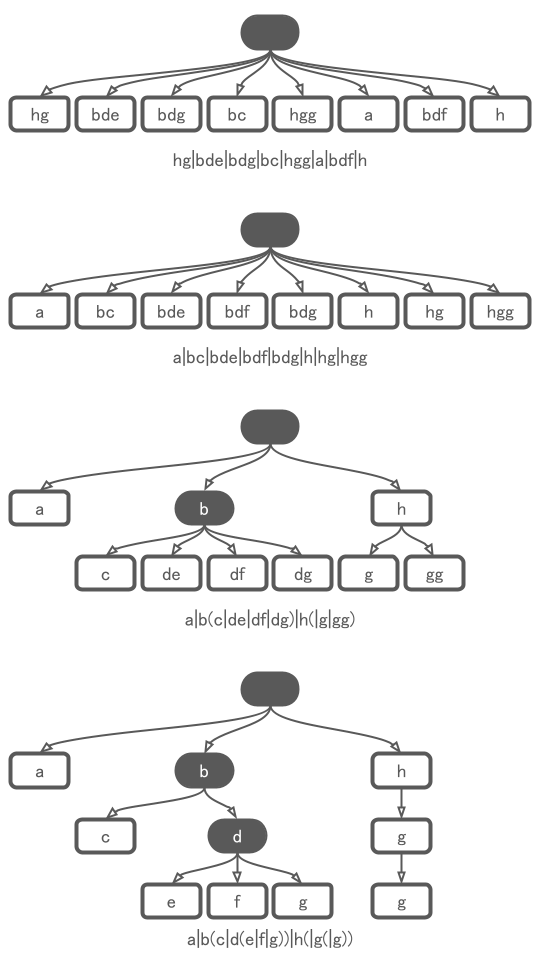
この変形された最後の木がトライ木です。つまり、トライ木は共通する文字を頭からまとめていった時にできる木構造(階層構造)です。正規表現による回りくどい説明をしたのは、トライ木と正規表現の関係性を示したかったからです。
さて、構築するだけで終わらせず、図のトライ木を使ってみましょう。”bdf”という単語が存在するか調べるには、矢印を”b”, “d”, “f”と3回たどるだけでわかります。辿った先が単語の終端(白い頂点)なので、”bdf”という単語は存在します。一方で、”hgf”という単語は存在しません。なぜなら、”h”, “g”までは矢印が辿れますが、最後の”f”が辿れないからです。また、”bd”という単語も存在しません。なぜなら、”b”, “d”と矢印を辿ることはできますが、単語の終端ではない黒い頂点に止まってしまうからです。
トライ木の概念と索引方法は以上の通りです。ただし、索引が高速化するかは実装に依存します。どの矢印を辿るかの選択が高速にできれば、単語の索引も高速にできます。そのような効率的なトライ木の実装方法としてダブル配列やLOUDSが知られています。この記事では、ダブル配列やLOUDSの実装はしません。ハッシュテーブルを利用して実装します。
ハッシュテーブルの詳細は割愛しますが、ハッシュテーブルでも辿るべき矢印は高速に選択できます。また、PowerShellはハッシュテーブルを簡単に使えるため、実装を簡略化できます。その代わり、ハッシュテーブルを使うとメモリ消費が増えます(空間計算量が悪化する)。
実装:各行について、すべての単語をまとめて調べる
単語を1つのトライ木にまとめます。入力の各行の各インデックスから始まる任意の部分文字列がトライ木に含まれているか調べる実装です。
トライ木を使ったコードは次のとおりです。ConvertTo-Trieがトライ木を構築する関数です。Test-Trieが入力行の各インデックスから始まる任意の部分文字列がトライ木に含まれているか調べる関数です。Measure-Trieは実行時間を計測するベンチマーク用の関数になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
# パイプラインで入ってくる単語を、 # 1つのトライ木に変換する function ConvertTo-Trie { Begin { # 木の根っこ # 子は持たず、単語の終端でもない。 $root = @{ IsEnd = $false } } Process { # 木の根から開始する $node = $root # 単語の先頭の文字から終端の文字まで繰り返す for($i = 0; $i -lt $_.Length; $i++) { # 今見ている文字が子として存在しなければ、 # 新規の子(矢印の先)を追加する $key = $_[$i] if(-not $node.ContainsKey($key)) { $node[$key] = @{ IsEnd = $false } } # 矢印の先の子へ移動 $node = $node[$key] } # 単語の終端なので、 # IsEndを真($True)にしておく $node.IsEnd = $true } End { # 根を返す $root } } # 入力行$Stringに対して、 # トライ木に一致する単語が含まれているか調べる filter Test-Trie([string] $String, [hashtable] $Trie) { # トライ木に空文字が登録されている場合、 # どの入力行に対しても真($true)を返す if($Trie.IsEnd) { return $true } # 入力行の各文字を先頭とした部分文字列を調べていく for($i = 0; $i -lt $String.Length; $i++) { $node = $Trie for($j = $i; $j -lt $String.Length; $j++) { # 現在の文字で辿れる矢印が存在しなければ、 # $iから始まる部分文字列でトライ木に含まれる単語は存在しないので、 # ループを抜ける $key = $String[$j] if(-not $node.ContainsKey($key)) { break; } # もし終端の頂点が見つかれば、 # $iから始まる部分文字列でトライ木に含まれる単語が存在するため、 # 真($true)を返す $node = $node[$key] if ($node.IsEnd) { return $true } } } # すべての単語が入力行に含まれていなかったので、 # 偽($false)を返す return $false } # トライ木を使った実装のベンチマーク filter Measure-Trie([string] $InPath, [string] $WordsPath, [string] $OutPath) { # Measure-Commandで実行時間を取得する $timespan = Measure-Command { # 前処理:単語集をまとめてトライ木に変換する $trie = Get-Content $WordsPath | ConvertTo-Trie # 主処理: # 入力ファイルの各行について、 # Test-Trieで単語が含まれていない行のみを抽出し、 # 出力先のファイルに書き込む Get-Content $InPath | Where-Object {-not (Test-Trie $_ $trie)} | Out-File $OutPath -Encoding Default } # 実行時間を表示する Write-Host $timespan.ToString() } |
ベンチマーク:入力データは郵便番号データ
ベンチマークに使ったコマンドは次の通りです。計測回数は1回だけです。
入力データは郵便番号データのCSVを利用しています。このCSVは郵便局が公式ホームページで公開しています。なお、郵便番号データはトライ木に有利な可能性があります。例えば、近い住所の市区町村名は共通の接頭部を持ちやすいです。
結果に納得がいかない場合は、公平なベンチマーク方法とデータを用意し、追試に挑戦してみてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 単語集作成:郵便番号データの3文字以上の市区町村名を単語として使う # 「.\in\13TOKYO.CSV」が東京都の郵便番号データ # 「.\in\KEN_ALL.CSV」が全国の郵便番号データ cat .\in\13TOKYO.CSV | % {($_ -split ',')[8].Trim('"')} | ? Length -ge 3 | out-file .\words\13T.CSV -enc Default cat .\in\KEN_ALL.CSV | % {($_ -split ',')[8].Trim('"')} | ? Length -ge 3 | out-file .\words\ALL.CSV -enc Default # 入力ファイル:東京、単語集:東京のベンチマーク Measure-Contains .\in\13TOKYO.CSV .\words\13T.CSV .\out\13T_13T_Contains.CSV Measure-RegexOr .\in\13TOKYO.CSV .\words\13T.CSV .\out\13T_13T_RegexOr.CSV Measure-Trie .\in\13TOKYO.CSV .\words\13T.CSV .\out\13T_13T_Trie.CSV # 入力ファイル:東京、単語集:全国のベンチマーク Measure-Contains .\in\13TOKYO.CSV .\words\ALL.CSV .\out\13T_ALL_Contains.CSV Measure-RegexOr .\in\13TOKYO.CSV .\words\ALL.CSV .\out\13T_ALL_RegexOr.CSV Measure-Trie .\in\13TOKYO.CSV .\words\ALL.CSV .\out\13T_ALL_Trie.CSV # 入力ファイル:全国、単語集:東京のベンチマーク Measure-Contains .\in\KEN_ALL.CSV .\words\13T.CSV .\out\ALL_13T_Contains.CSV Measure-RegexOr .\in\KEN_ALL.CSV .\words\13T.CSV .\out\ALL_13T_RegexOr.CSV Measure-Trie .\in\KEN_ALL.CSV .\words\13T.CSV .\out\ALL_13T_Trie.CSV # 入力ファイル:全国、単語集:全国のベンチマーク Measure-Contains .\in\KEN_ALL.CSV .\words\ALL.CSV .\out\ALL_ALL_Contains.CSV Measure-RegexOr .\in\KEN_ALL.CSV .\words\ALL.CSV .\out\ALL_ALL_RegexOr.CSV Measure-Trie .\in\KEN_ALL.CSV .\words\ALL.CSV .\out\ALL_ALL_Trie.CSV |
| 入力行数 | 単語数 | 力まかせ | 正規表現 | トライ木 |
|---|---|---|---|---|
| 4,046 | 3,412 | 3秒04 | 2秒85 | 0秒51 |
| 4,046 | 88,329 | 1分36秒09 | 38秒71 | 1秒43 |
| 124,523 | 3,412 | 2分48秒92 | 35秒80 | 24秒71 |
| 124,523 | 88,329 | 58分38秒39 | 6分58秒47 | 21秒46 |
まとめ
この記事では、力まかせな実装、正規表現を使った実装、トライ木を使った実装をしてみました。実装ごとに簡易的なベンチマークを取っています。入力によっては、正規表現は力まかせの約8倍も高速になります。同様に、トライ木は正規表現の約20倍も高速になります。つまり、トライ木は力まかせの約160倍も高速になります。
力まかせは単純明快です。「早すぎる最適化は諸悪の根源」という格言に従い、処理時間に問題が出るまでは最も妥当な実装方法でしょう。
正規表現は力まかせに比べると格段に速くなります。高速化の詳細は正規表現エンジンが行うため、実装はさほど複雑になりません。力まかせで処理時間に問題が出た場合は、真っ先に試したい実装方法です。
トライ木は正規表現よりも速くなります。ただ、「早すぎる最適化は諸悪の根源」という格言に従い、手を出すべきかは慎重に検討したいところです。また、手を出すにしても、数ある文字列探索の手法からどれを選ぶべきか検討する必要があります。例えば、トライ木の発展としてパトリシア木やエイホ‐コラシック法があります。正規表現でも処理時間が間に合わない場合に、保守がしやすい手法から試していくと良いかもしれません。
この記事が複数文字列の探索方法を検討する際の参考になれば幸いです。



