
この記事は GMOアドマーケティング Advent Calendar 2019 17日目の記事です。
こんにちは、GMOアドマーケティングのS.Rです。
機械学習の開発に、学習データの欠損値の対応は、重要な処理の一つです。
今回は学習データの欠損値の対応法を皆さんへ紹介します。
1 欠損値とは
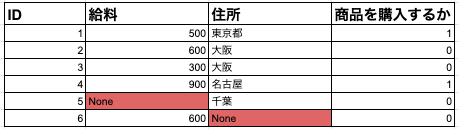
図1欠損値があるデータ
2 欠損値のタイプ
欠損値の発生には三つのタイプがあります。
1) MCAR(Missing Completely at Random ) :
完全にランダムな欠損です。
欠けていたデータは他のデータに依存していないパターンです。
2) MAR(Missing at random) :
データは他の特徴量に依存して欠損します。
例えば体重の情報を集計する時に、男性より女性の未回答率が上がります。この場合の欠損になっていた体重のデータはMARです。
3) MNAR(Missing not at random):
欠損となった値はある分布に従います。
MCARとMARには、使える手法があまりないので実務上は良く無視します。今回はMNARに使える手法を主に紹介します。
3 欠損値に対応する方法
3.1 欠損値を無視する
学習データの量が十分に確保できる場合であれば、データセットから欠測値を取り除いてもいいです。

3.2 欠損値を補完する
データ量が少ない場合は、単純に削除するとデータ量が減ってしまい、データが無駄になります。そこで、削除するのではなく何かしらデータを補完する必要があります。
-
-
中央値で補完する

図4: 中央値で補完する 中央値はデータを小さい順に並べたデータのちょうど中央にあるデータです。データのサンプル数が奇数個の場合は真ん中にある値が中央値となりますが、上のデータのようにデータが偶数個の場合は中央に最も近い2つの値の平均値を中央値とします。
- 平均値で補完する

図5: 平均値で補完する - 最頻値で補完する

図6: 最頻値で補完する
-
最頻値は学習データで最も頻度が高い値です。
4 Scikit-learnで欠損値を補完する
1 Libraryをimportする
|
1 2 3 4 5 |
from sklearn.impute import SimpleImputer import numpy as np import pandas as pd import logging logging.getLogger("sklearn").setLevel(logging.ERROR)1 |
2 中央値で補完する
|
1 2 3 4 5 6 7 |
imr = SimpleImputer(missing_values=np.nan, strategy='median') df2 = pd.DataFrame({"salary":[500,600,300,900, np.nan,600 ], "age":[50,30,30,20,20,np.nan] }) imputed_data = imr.fit_transform(df2) imputed_data |
3 平均値で補完する
|
1 2 3 4 5 6 7 8 |
imr = SimpleImputer(missing_values=np.nan, strategy='mean') df2 = pd.DataFrame({"salary":[500,600,300,900, np.nan,600 ], "age":[50,30,30,20,20,np.nan] }) imputed_data = imr.fit_transform(df2) imputed_data |
4 最頻値で補完する
|
1 2 3 4 5 6 7 |
imr = SimpleImputer(missing_values=np.nan, strategy='most_frequent') df2 = pd.DataFrame({"salary":[500,600,300,900, np.nan,600 ], "age":[50,30,30,20,20,np.nan] }) imputed_data = imr.fit_transform(df2) imputed_data |
5 まとめ
今回は、機械学習で学習データの欠損値に対応する方法を紹介しました。欠損値の対応は、良い機械学習のモデルを作る為に必要な、重要な処理の一つです。今回のブログが皆さんの機械学習に関する開発にお役に立てば幸いです。
明日は、satoshikiさんによる「ディレクターが頑張ってキーワード解析に取組んでみた」です。
引き続き、GMOアドマーケティング Advent Calendar 2019 をお楽しみください!
■エンジニア採用ページ ~福利厚生や各種制度のご案内はこちら~
https://www.gmo-ap.jp/engineer/
■Wantedlyページ ~ブログや求人を公開中!~
https://www.wantedly.com/projects/199431
■エンジニア学生インターン募集中! ~就業型インターンでアドテクの先端技術を体験しよう~
https://hrmos.co/pages/gmo-ap/jobs/0000027



