
今回は単語をベクトルにする方法の一つ、Word2Vecを皆さんへご紹介します。
Word2Vecとは
Word2Vecは機械学習のアルゴリズムに使われる文章を数字化したベクトル にする手法の一つです。
ベクトルで文書を表示するコンセプト
単語をベクトルする方法
では、どのようにしてベクトルを使用し単語を表示するのでしょうか。下記の例で説明します。ここに動物に関する単語が4つあります。(私の個人的な考えから)手動で下記のような次元数2のベクトルを作成してみました。
|
単語 |
可愛さ | 体重 |
| 犬 | 99.0 | 30kg |
| 猫 | 98.0 | 3kg |
| 金魚 | 60.0 | 0.01kg |
| 鳥 | 50.0 | 0.03kg |
先程作成したベクトル結果を2D座標に反映しましょう。

転換した結果、動物の距離を計算できます。例えば、犬と猫の距離は犬と鳥の距離より近いことがわかります。
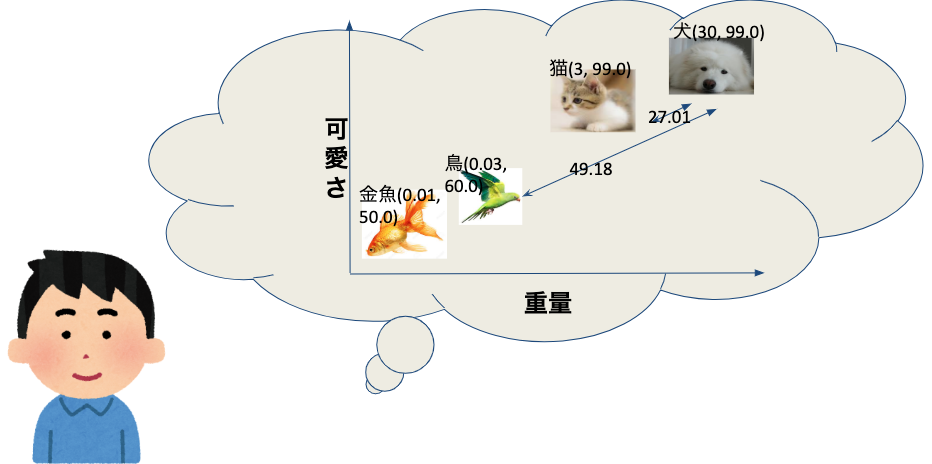
単語のベクトルを使って文書はベクトル空間の位置も計算できます。文書に含まれている単語のベクトルを平均値計算して結果を取れます。
文章をベクトルする方法
単語のベクトル結果を使って、文章もベクトルに転換できます。文書に含まれている単語のベクトルの平均値は、文章のベクトルになります。例えば“猫は金魚を食べました”を、前の動物の単語をベクトルした結果でベクトルします。計算の流れは下記の図になります。
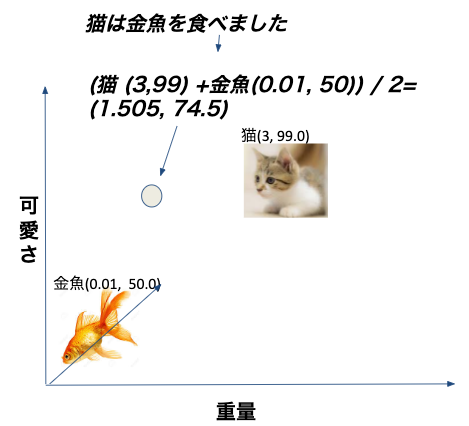
実際の業務に使用できる文書のベクトル計算は二種類あります。
1 文書に含まれている単語のベクトルを平均値計算します(単語がN個ある場合は下記の計算式になります)。
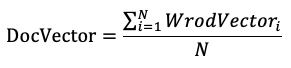
2 文書に含まれている単語のベクトルを平均値計算して各単語のTFIDF値を掛けます(TFIDFについてはこちらのWikiを参考してください)。
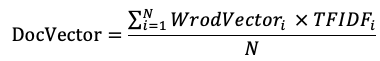
ベクトルを生成する方法
先の例で、手動で二次元のベクトルを考えましたが、各次元の意味があります。実業務ではベクトルを手動で生成することはなく、統計学のモデルを使って生成します。
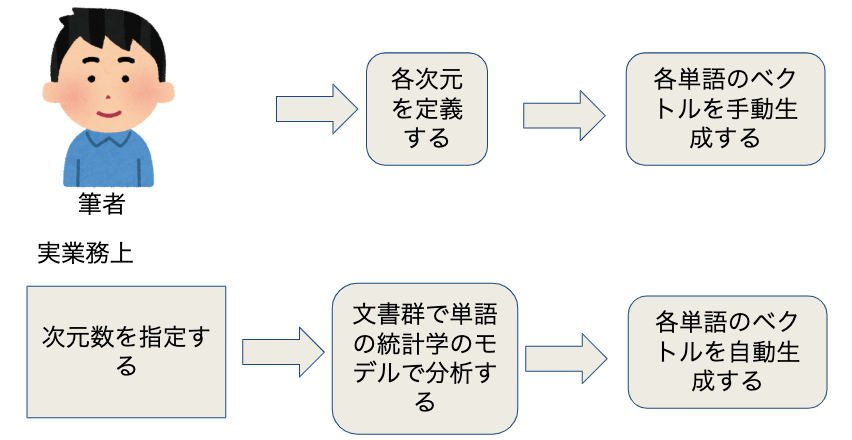
Skip-Gram Model
今回はword2vecによく使われる一つのモデルである、Skip-Gram Modelをご紹介します。Skip-Gram Modelは、分析の対象になっていた文章群で、前後の単語の出現確率を同時に学習データにして、ニューラル ネットワークとして学習する手法です。
猫は金魚を食べました。猫は犬と喧嘩していた。犬は鳥と一緒に遊んでいる。
1 各単語と一緒に出る確率を集計します。
分析の単語群(猫, 金魚, 犬, 鳥)です。各単語と一緒に出る確率は下記の通りです。
| 前の単語 | 後ろの単語 | 確率 |
| 猫 | 犬 | 0.5 |
| 猫 | 金魚 | 0.5 |
| 犬 | 鳥 | 1.0 |
2 各単語をOnehotEncodeで計算します。OnehotEncodeが詳しくないの方はこちらのWikiを参考してください。
| 前の単語 | OneHotEncode |
| 猫 | 1000 |
| 金魚 | 0100 |
| 犬 | 0010 |
| 鳥 | 0001 |
3 学習データをつくります
| 前の単語 | 前の単語のOneHotEncode | 後ろの単語 | 確率 |
| 猫 | 1000 | 犬 | 0.5 |
| 猫 | 1000 | 金魚 | 0.5 |
| 犬 | 0010 | 鳥 | 1.0 |
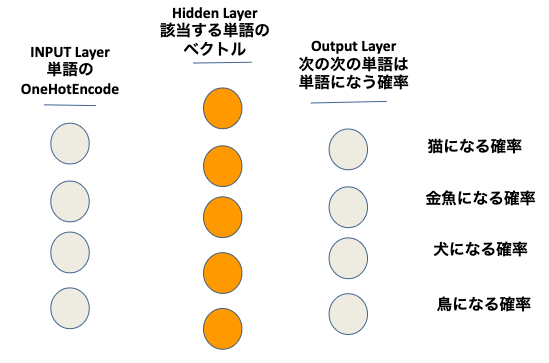 4 多層パーセプトロン(MLP)のモデルを作ります。多層パーセプトロン(MLP)が詳しくないの方はこちらのWikiを参考してください。
4 多層パーセプトロン(MLP)のモデルを作ります。多層パーセプトロン(MLP)が詳しくないの方はこちらのWikiを参考してください。
5 多層パーセプトロン(MLP)のモデルを作ります。
訓練したモデルで各単語をinputするときに真中のHiddenLayerの各セールの値はこの単語をベクトルする結果になります。
例えば、訓練したモデルでinputは猫になるとき、モデルの計算結果は下記になります。
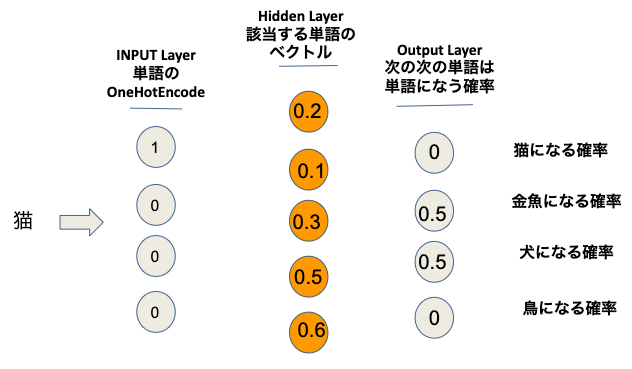
学習したモデルで単語猫の計算結果は[0.2,0.1,0.3,0.5,0.6]になります。
まとめ
今回は、自然言語処理の開発に、単語をベクトルにする方法をご紹介しました。この対応は、良い機械学習のモデルを作る為に必要な、重要な処理の一つです。今回のブログが、皆さんの自然言語処理の開発にお役に立てば幸いです。
明日は、mizkichさんによる「BigQueryで全テーブルのメタ情報を一括で取得する方法」です。
ご精読をありがとうございました!
引き続き、GMOアドマーケティング Advent Calendar 2019 をお楽しみください!
■エンジニア採用ページ ~福利厚生や各種制度のご案内はこちら~
https://www.gmo-ap.jp/engineer/
■Wantedlyページ ~ブログや求人を公開中!~
https://www.wantedly.com/projects/199431
■エンジニア学生インターン募集中! ~就業型インターンでアドテクの先端技術を体験しよう~
https://hrmos.co/pages/gmo-ap/jobs/0000027



