
GMOアドマーケティングのT.Cです。
DataProcのCloudクライアントライブラリ、GCEやApp EngineのCron serviceなどを利用して定期的にDataProcでデータを加工・分析する場合、データサイズ・処理量・費用などの理由でバッチごとに適切なDataProcのスペック、バッチのオプションを指定しておく必要があります。
しかし、1日ごとにデータを加工・保存していたバッチが何かしらの理由で失敗して、3日ぐらい放置されたと仮定しましょう。1日分のデータを処理する目的で指定したDataProcのスペックでは3日分のデータの処理は難しいでしょう。
復旧のためには、指定しておいたDataProcのスペック、バッチのオプションを一時的に変更し、再実行するなどの手間が発生します。
そこで、今回はCurlを利用してDataProcのスペックやバッチのオプションを自由、楽に更新しながらjobを実行する方法をご紹介いたします。
構成
DataProcのCloudクライアントライブラリを利用し、DataProcで定期的にデータを処理する方法は多いと思われますが、今回の説明に使う構成は以下の通りです。
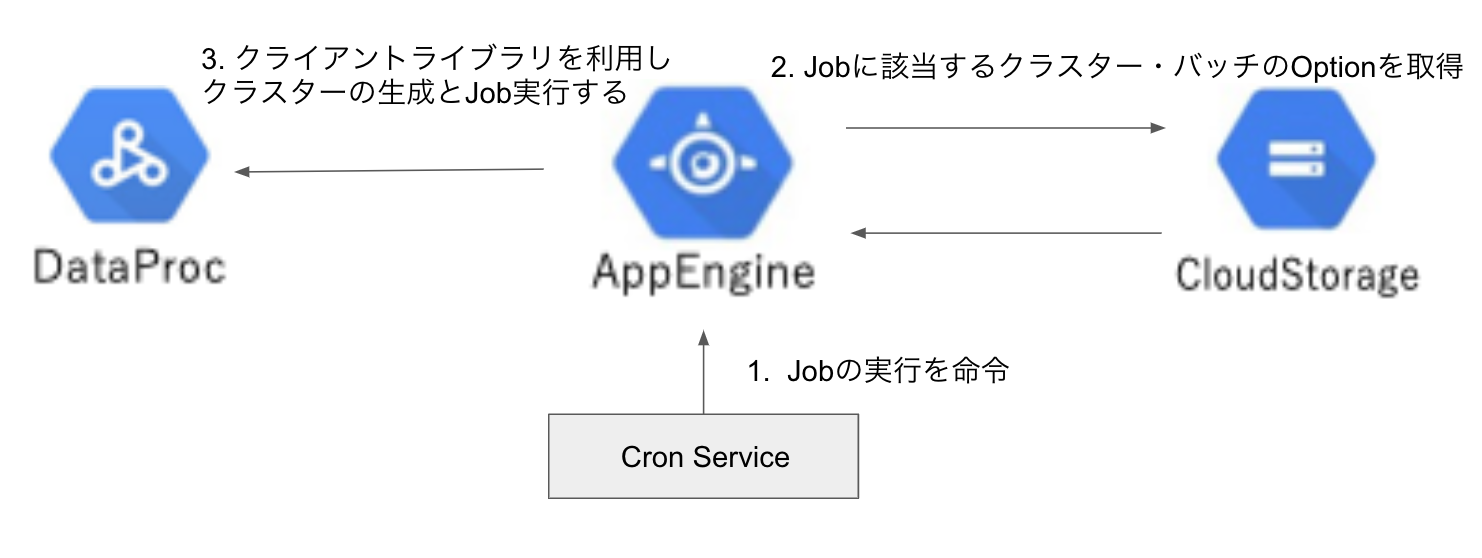
- AppEngineのCron SerivceでApp Engineの方に定期的にDataProcの処理を命令します。
- AppEngineは命令されたJobに該当するDataProcのスペック・バッチのオプションをGCSから取得します。(AppEngine内部にDataProcのスペックなどを定義する方法もあると思いますが、新しいバッチの追加やDataProcのスペックを更新する場合にGAEをデプロイし直す必要があるので、GCSを利用します)
- GCSから取得した情報を元にDataProc用のクライアントライブラリでクラスターの生成とJobの実行を行います。
↑の構成にCurlでDataProcのスペックを自由、楽に変更するための仕組みを加えてみましょう。

- Curlで実行するjobを選択、更新するクラスター・バッチのオプションの情報も一緒にGAEに転送します。
- AppEngineは命令されたJobに該当するDataProcのスペック・バッチのオプションをGCSから取得します。
- Curlで送ったデータをGCSから取得したデータに上書きします。
- 上書きした情報を元にDataProc用のクライアントライブラリでクラスターの生成とJobの実行を行います。
詳細
・GCS: gs://dataproc_setting_test/cluster.json(バッチごとにDataProcの生成に必要な情報を記入)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
{ "test_batch_one": { "cluster_name": "testcluster1", "region": "global", "zone": "asia-northeast1-a", "master_machine_type": "n1-standard-1", "master_num": 1, "worker_machine_type": "n1-standard-1", "worker_num": 2, "jobs": { "0": { # テスト用のjarファイルを生成し、GCSに保存 "jar": "gs://dataproc_setting_test/jar/option-test-batch-jar-with-dependencies.jar", # 実行するバッチ "main_class": "batch.OptionTestBatch", # バッチのオプション "args": ["-mode","test"] } } }, "test_batch_two": { "cluster_name": "testcluster2", "region": "global", "zone": "asia-northeast1-a", "master_machine_type": "n1-standard-2", "master_num": 1, "worker_machine_type": "n1-standard-4", ...省略 } |
GAE(framework: responder)
・main.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# processing_typeはcluster.jsonのtest_batch_oneやtest_batch_twoを指します # backgroud.taskを利用することで処理が終わることを待たずにすぐにresponseします @api.route("/{processing_type}") async def execute(req, resp, *, processing_type): # curlのdataprocやバッチのオプションを取得します custom_config = await get_params(req) process_by_cluster(processing_type, custom_config) resp.text = "{} is accepted".format(processing_type) # クラスター生成・job実行・クラスター削除をbackgroudで動かします @api.background.task def process_by_cluster(processing_type, custom_config): # GCSからcluster.jsonをロードし、custom_configあれば上書きします dataproc_setting = DataprocSetting(processing_type, custom_config) # クラスターの生成とjobの実行を行います Cluster(dataproc_setting).start() async def get_params(req): if req.params: return dict(req.params) params = await req.content if params: return json.loads(params.decode('utf-8')) |
・Config.py(GCPのproject_idやdataproc用のservice_account指定など)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
class Config(object): DEBUG = False class TestConfig(Config): # GCP INFO PROJECT_ID = 'tokyo-amphora-278605' # DataProcのスペック、バッチの情報が記入されているバケット名 CLUSTER_CONFIG_BUCKET_NAME = 'dataproc_setting_test' # DataProcのスペック、バッチの情報が記入されているファイル名 CLUSTER_CONFIG_FILE_NAME = 'cluster.json' # DataProcの生成、削除など操作権限をもつサービスアカウント SERVICE_ACCOUNT = 'tokyo-amphora-278605@appspot.gserviceaccount.com' SERVICE_ACCOUNT_SCOPE = 'https://www.googleapis.com/auth/sqlservice.admin' config_by_env = dict(test=TestConfig) config = config_by_env[os.getenv('RESPONDER_ENV', 'test')] |
・DataprocSetting.py(gs://dataproc_setting_test/cluster.jsonの情報をロード)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
class DataprocSetting: def __init__(self, processing_type, custom_config): cluster_config = self.load(processing_type) #curlのdataprocやバッチのオプションが存在すれば更新します if custom_config is not None: cluster_config.update(custom_config) self.cluster_name = cluster_config["cluster_name"] self.region = cluster_config["region"] self.zone = cluster_config["zone"] self.master_machine_type = cluster_config["master_machine_type"] self.master_num = cluster_config["master_num"] self.worker_machine_type = cluster_config["worker_machine_type"] self.worker_num = cluster_config["worker_num"] self.preemptible_worker_num = 0 if "preemptible_worker_num" not in cluster_config else cluster_config["preemptible_worker_num"] self.jobs = self.create_jobs(cluster_config["jobs"]) def load(self, processing_type): client = storage.Client(config.PROJECT_ID) bucket = client.get_bucket(config.CLUSTER_CONFIG_BUCKET_NAME) blob = storage.Blob(config.CLUSTER_CONFIG_FILE_NAME, bucket) cluster_config = json.loads(blob.download_as_string().decode("utf-8")) return cluster_config[processing_type] def create_jobs(self, jobs): return list(map(lambda job: self.create_job(job), jobs.values())) def create_job(self, job): args = [] if not job.get("args") else job["args"] return Job(job["main_class"], job["jar"], args) |
・cluster.py(cluster.jsonの情報を利用し、クラスターの生成・削除を行う)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
# cluster class Cluster: def __init__(self, cluster_config): self.logger = logging.getLogger("single_cluster") self.cluster_config = cluster_config def start(self): try: # クラスター生成 cluster = self.create_cluster() self.logger.info('add create cluster callback {}'.format(self.cluster_config.cluster_name)) # クラスターが生成されるとjobを実行 cluster.add_done_callback(self.execute_job) self.logger.info('Waiting for {} creation...'.format(self.cluster_config.cluster_name)) except: self.logger.info("{} submit error: {}".format(self.cluster_config.cluster_name, traceback.format_exc())) # jobを実行 def execute_job(self, operation_future): try: self.logger.info('Single Cluster {} created.'.format(self.cluster_config.cluster_name)) for job in self.cluster_config.jobs: self.logger.info("{} job submit".format(self.cluster_config.cluster_name)) job.submit(config.PROJECT_ID, self.cluster_config.region, self.cluster_config.cluster_name) # jobの実行が終わったらクラスターを削除 self.delete_cluster() except: self.logger.info("{} execute_job error: {}".format(self.cluster_config.cluster_name, traceback.format_exc())) # cluster.jsonの情報を利用しクラスターを生成します def create_cluster(self): client = dataproc_v1.ClusterControllerClient() zone_uri = 'https://www.googleapis.com/compute/v1/projects/{}/zones/{}'.format(config.PROJECT_ID, self.cluster_config.zone) cluster_data = { 'project_id': config.PROJECT_ID, 'cluster_name': self.cluster_config.cluster_name, 'config': { 'gce_cluster_config': { 'zone_uri': zone_uri, 'service_account': config.SERVICE_ACCOUNT, 'service_account_scopes': [ config.SERVICE_ACCOUNT_SCOPE ] }, 'master_config': { 'num_instances': self.cluster_config.master_num, 'machine_type_uri': self.cluster_config.master_machine_type, }, 'worker_config': { 'num_instances': self.cluster_config.worker_num, 'machine_type_uri': self.cluster_config.worker_machine_type, }, 'secondary_worker_config': { 'num_instances': self.cluster_config.preemptible_worker_num, } } } self.logger.info("Creating {}".format(self.cluster_config.cluster_name)) cluster = client.create_cluster(config.PROJECT_ID, self.cluster_config.region, cluster_data, timeout=90.0) return cluster # クラスター削除 def delete_cluster(self): client = dataproc_v1.ClusterControllerClient() self.logger.info("Deleting {}...".format(self.cluster_config.cluster_name)) cluster = client.delete_cluster(project_id=config.PROJECT_ID, region=self.cluster_config.region, cluster_name=self.cluster_config.cluster_name, timeout=90.0) self.logger.info("add delete cluster callback {}".format(self.cluster_config.cluster_name)) cluster.add_done_callback(self.cluster_delete_callback) self.logger.info("Waiting for {} deletion...".format(self.cluster_config.cluster_name)) def cluster_delete_callback(self, operation_future): self.logger.info('{} deleted.'.format(self.cluster_config.cluster_name)) |
・job.py(cluster.jsonにあるjobの情報を利用し、jobを実行)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
class Job: def __init__(self, main_class, jar, args): self.logger = logging.getLogger("job") self.jar = jar self.main_class = main_class self.args = args # cluster.jsonの情報を利用し、jobを実行 def submit(self, project_id, region, cluster_name): job_details = { 'placement': { 'cluster_name': cluster_name }, "spark_job": { "main_class": self.main_class, "main_jar_file_uri": self.jar, "args": self.args }, } client = dataproc_v1.JobControllerClient() result = client.submit_job(project_id=project_id, region=region, job=job_details, timeout=90.0) job_id = result.reference.job_id self.logger.info("Submitted job Cluster {}, ID {}. Waiting for job to finish...".format(cluster_name, job_id)) while True: job = client.get_job(project_id, region, job_id) # Handle exceptions if job.status.State.Name(job.status.state) == 'ERROR': self.logger.error("Job failed. Cluster {}, ID {}".format(cluster_name, job_id)) raise Exception(job.status.details) elif job.status.State.Name(job.status.state) == 'DONE': self.logger.info("Job finished. Cluster {}, ID {}".format(cluster_name, job_id)) break |
cron service
・cron.yaml
|
1 2 3 4 5 |
cron: - description: "test batch" url: /test_batch_one schedule: every 10 mins timezone: Asia/Tokyo |
ここまで、構築・実装を行うと普段は以下のようにCron serviceで定期的にGAEにバッチの実行を命令することになり、何か問題があればCurlを利用しDataProcのスペックやバッチのオプションを調整しながら実行させることが可能となります。
確認
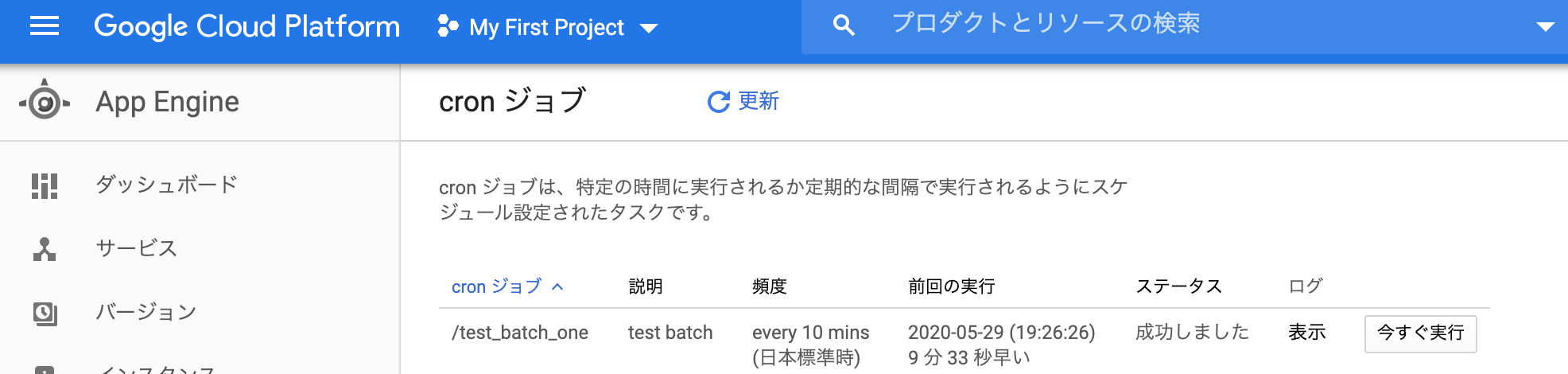
・Cron service
・実行されるDataProcのスペック確認(cluster.jsonのcluster_nameと一致)
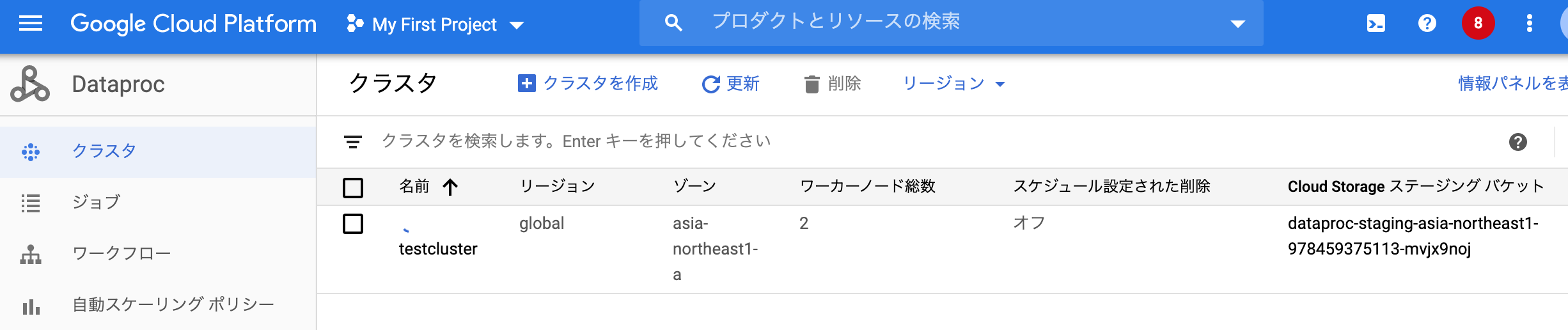
・クラスター構成(master: 1, slave:2)

・master情報(n1-standard-1でcluster.jsonと一致)
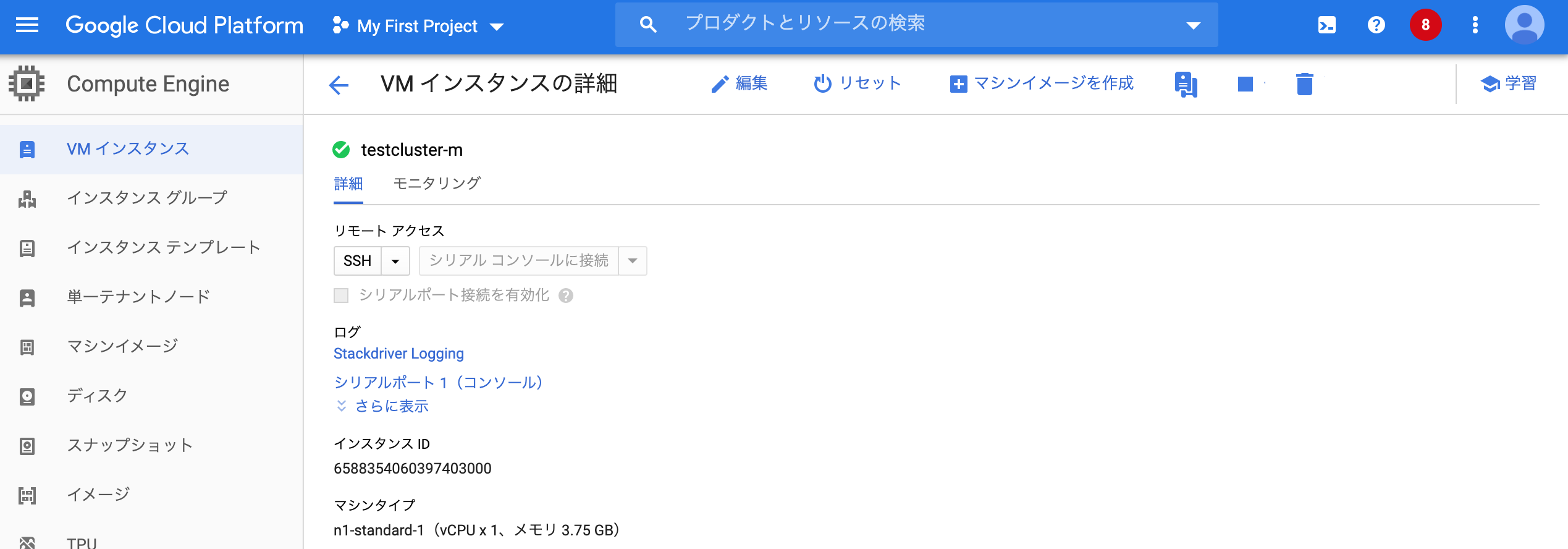
・slave情報(n1-standard-1でcluster.jsonと一致)
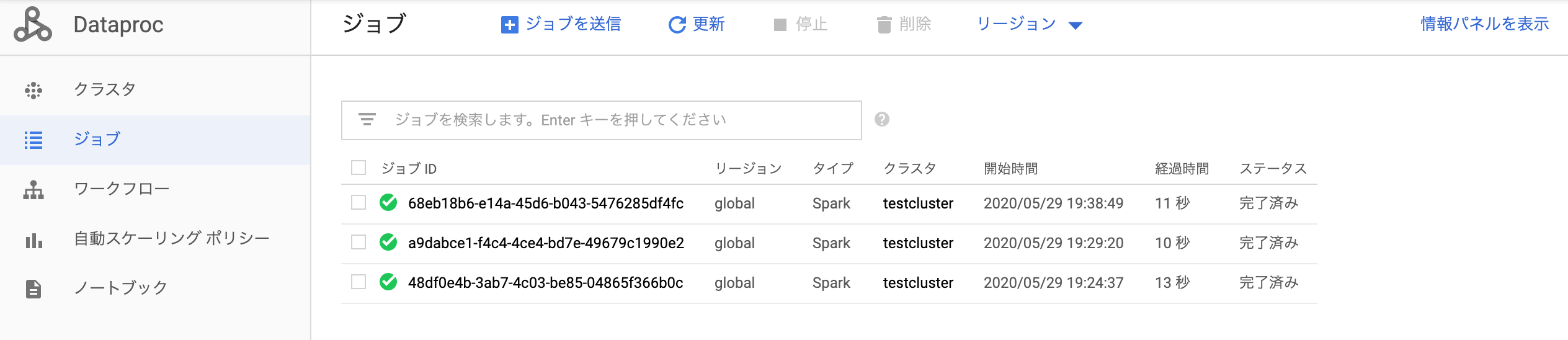
・Jobの実行履歴確認(cron serviceに登録されている通りに10分ごとに実行されている)
Curlで実行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
a-3-159:batch choi$ curl -H 'Content-Type:application/json' -d '{"cluster_name": "curlcluster","worker_machine_type": "n1-standard-1","worker_num": 3,"jobs": {"0": {"jar": "gs://dataproc_setting_test/jar/option-test-batch-jar-with-dependencies.jar","main_class": "batch.OptionTestBatch","args": ["-mode","curltest"]}}}' https://tokyo-amphora-278605.appspot.com/test_batch_one test_batch_one is accepted # -dの値 # 変更したものだけ記入(今回はworker数を増やしてみます) { "cluster_name": "curlcluster", "worker_num": 3, "jobs": { "0": { "jar": "gs://dataproc_setting_test/jar/option-test-batch-jar-with-dependencies.jar", "main_class": "batch.OptionTestBatch", "args": ["-mode","curltest"] } } } |
・クラスター確認(slaveノード数が3にちゃんとなっております)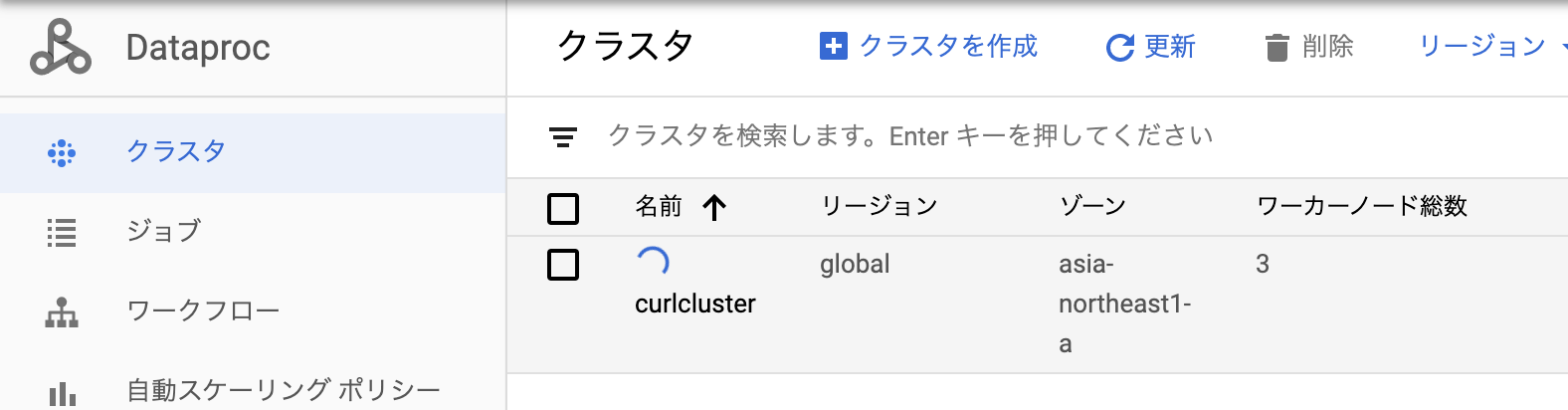
・バッチのオプションもcurltestに変えたのでjobのログを確認

これで通常は、cluster.jsonに指定したスペックで処理を行い、何か問題があった時はCurlでDataprocのスペックやバッチのオプションを自由、楽に変更しながら運営できるようになります。
終わりに
なるべく簡略して実装してCurlのことも例ではlocalで実行していますが、firewallを設定して特定環境のみ実行できるように制御した方がいいと思います。
時間があれば、試しに実装してみたり、応用してコマンド1つで複数のクラスターを立ち上げてみたりしてください!


