
このエントリーは、GMOアドマーケティング Advent Calendar 2020 の 10日目の記事です。
こんにちは、GMOアドマーケティングのmizkichです。
DMP(Data Management Platform)の開発運用を担当しています。
このDMPで利用しているBigQueryは、一千億を超えるレコードでも数分で処理してくれる、非常に高い高速性が魅力です。
その反面、通常のリレーショナルデータベース(RDB)では起こらないエラーがたびたび発生してしまいます。
この記事では、BigQuery独自の様々なエラーを回避する方法を紹介します。
・はじめに
従来のRDBでは、最も効率的な実行計画を意識してSQLを書けば、PARSE(評価)もEXECUTE(実行)も正常に高速に処理されました。
BigQueryでは、実行計画を意識しただけでは複雑なSQLは実行出来ません。
BigQueryでもRDBと同じように、SQLをPARSEした後にEXECUTEを行います。
しかしPARSEとEXECUTEで評価方法が異なっており、尚且つPARSE側の評価方法は実行計画と大きく乖離しています。

EXECUTE側で最速で処理されるSQLを書いても、PARSE側で「効率が悪いから直せ」と改悪を要求されます。
これは、PARSE側の評価方法に、独自のコスト算出式が利用されているためです。
以後、BigQueryのエラーメッセージに対してどう修正すればエラーを回避出来るのかを紹介していきます。
・リソース超過エラー
Resources exceeded during query execution: Not enough resources for query planning – too many subqueries or query is too complex.
和訳「クエリの実行中にリソースが超過しました:クエリプランニングに十分なリソースがありません-サブクエリが多すぎるか、クエリが複雑すぎます。」
このエラーは、PARSE処理でSQLが複雑だと評価され、コストオーバーと認定されたために発生するエラーです。
RDBで同様のエラーが出た場合はテーブルの件数やデータ分布やテーブル同士の結合方法などを見直しますが、BigQueryでは全く手法が変わります。
第一の対処として、テーブルの結合方法を変えます。

BigQueryではUNIONが最もコストが高く、続いてEXIST, LEFT JOIN, INNER JOINの順でコストが低いと評価されます。
私の感覚ではありますが、これはRDBのほぼ逆の順序です。
BigQueryでコストオーバーになった場合には、「UNION ALLを分解し、LEFT JOINで結合する」「EXISTSでの存在確認をやめ、INNER JOINで結合する」などの対処が必要です。
(RDBの常識からすると異常な対処ですが、これがBigQueryなのだと割り切っています。)
第二の対処として、事前の絞り込みをやめます。

RDBでテーブル同士をJOINする場合には、コストの肥大化を防ぐために事前にWHERE句で絞り込み、データ件数を少なくしてから結合するかと思います。
BigQueryでコストオーバーになった場合には、関数の呼び出し回数が少なくなる様にSQLを書き換えます。
「JOINで結合した後にWHERE句で絞り込みを行う」など、WHERE句や集計関数の利用回数が最小となるように対処します。
そのほか、SELECT COUNT(*)用のサブクエリを辞めてSELECT COUNT(*) OVER()を利用する方法もあります。
OVERを活用するとJOIN自体を無くせるためリソース超過エラーが消えますが、EXECUTEが劇的に低速になる諸刃の剣です。
・メモリ超過エラー
Resources exceeded during query execution: The query could not be executed in the allotted memory.
和訳「クエリ実行中にリソースを超過しました:割り当てられたメモリでクエリを実行出来ませんでした。」
このエラーは、クエリで処理出来るデータ件数を超え、メモリオーバーと認定されたために発生するエラーです。
WITH句を利用すれば、WITH句それぞれ毎にメモリ使用量が評価されるため、WITH句を増やす程多くのデータを処理することが出来ます。
このエラーは、以下の手順で解消します。
- 年次処理などは、サブクエリを増やし、月次毎の小計を出してから集計する。
- サブクエリをWITH句に外出しする。
- メモリオーバーと認定されたサブクエリを、ID抽出処理とカラム取得処理に分割する。
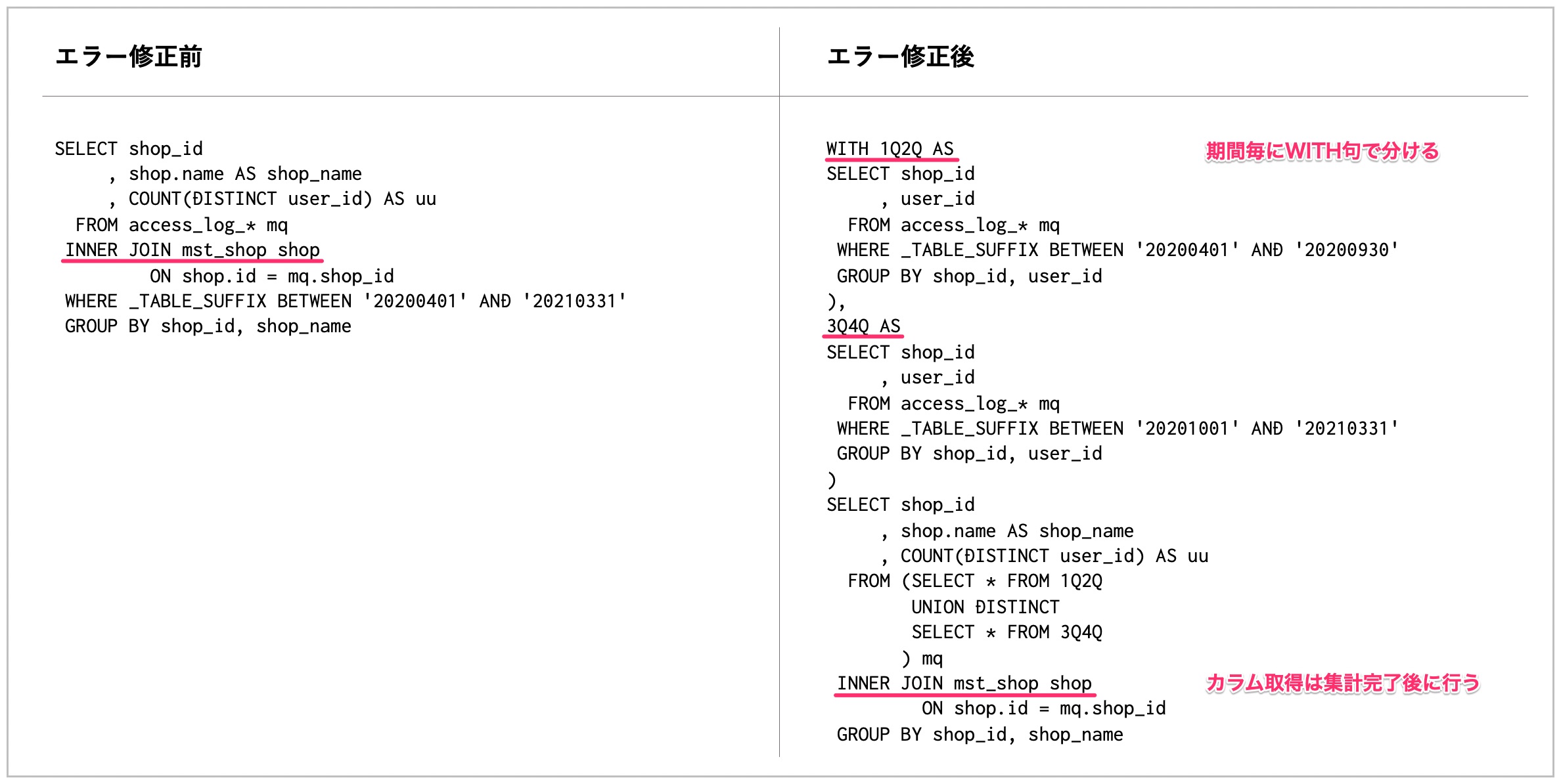
1番目と2番目は比較的納得しやすいかと思います。
3番目は、SELECT *など数十個のカラムを出力するサブクエリに有効な手段です。
|
1 2 3 4 5 6 7 8 9 |
SELECT sq.* FROM (SELECT shop_id , COUNT(DISTINCT user_id) AS uu FROM access_log GROUP BY shop_id HAVING uu >= 100 ) mq INNER JOIN access_log sq ON sq.shop_id = mq.shop_id |
カラム数もレコード数も多いテーブルに対して、キーを抽出する処理とカラムを取得する処理を分けることで、サブクエリあたりのメモリを減らすことが出来ます。
(「メモリが減る」とは、「PARSERがメモリ超過が解消されたと判断する」の意味であり、実際にEXECUTEでのメモリ使用量が少なくなるかは不明です。)
・複雑な相関サブクエリ
Correlated subqueries that reference other tables are not supported unless they can be de-correlated, such as by transforming them into an efficient JOIN.
和訳「他のテーブルを参照する相関サブクエリは、それらを効率的なJOINに変換するなどして相関を解除出来ない限り、サポートされません。」
このエラーは、INやEXISTSの中でUNION, INTERSECT, EXCEPTなどを利用すると発生します。
UNIONを使ったテーブルは、WITH句で外部化したとしてもINやEXISTSに利用した時点でこのエラーが出てしまいます。
このエラーは、UNIONを使ったテーブルをGROUP BYで囲うことで回避することが出来ます。
GROUP BYで囲うと「UNIONを使った」判定が消え、IN句やEXISTS句で利用出来るようになります。

・行サイズ超過エラー
Cannot query rows larger than 100MB limit.
和訳「100MBの制限を超える行をクエリすることは出来ません。」
このエラーは、 1レコードの容量が100Mを超えた場合に発生するエラーです。
最終的な抽出結果としての容量ではなく、サブクエリなど途中経過を含む全ての工程のどこかで100Mを超えるとエラーになります。
このエラーは主に、ARRAY_AGGやARRAY_CONCAT_AGGなどの配列関数を利用するときに多く発生します。
このエラーを解消するには、「ARRAY_AGG(DISTICT)」など配列化の後にDISTINCTを行うのではなく、DISTINCTを事前に行ってからARRAY_AGGを行う必要が有ります。

・まとめ
BigQuery PARSERが出すこれらのエラーは、正しいSQLを書けるエンジニアからすると、邪魔以外のなにものでもないです。
対処すると多少SQLが遅くなりますので、BigQueryからエラーがでない限りは通常の実行計画を意識したSQLを書くのが良いかと思います。
この対処を行ったSQLは、目的に対して遠回りなSQLになり、レビューが難解になります。
レビューを依頼する側と受ける側、どちらにもマニュアルにない知識が必要となりますので、この記事がお役に立てると幸いです。
明日は、mnaka1115さんによる「TAXELの単一障害点を解消する」です。
引き続き、GMOアドマーケティング Advent Calendar 2020 をお楽しみください!
■エンジニア採用ページ ~福利厚生や各種制度のご案内はこちら~
https://www.gmo-ap.jp/engineer/
Full Stack Engineer @ GMO AD Marketing, Inc.
DMP(Data Management Platform)の開発運用担当してます。
(Java x Ruby x Kubernetes x BigQuery x Hazelcast x etc)
マイブームは犬と車と登山とスノボ。


