こんにちは、GMOアドマーケティングのM.H.と申します!
文章のカテゴリ分類って難しいですよね。例えばメールの本文からそれがスパムか否かを判定する二値分類ならまだ良いですが、書かれた文章のテーマで分類するなどの話になってくると、その分カテゴリ数が増えて問題の難易度が上がります。
このような問題に対処するために機械学習を使うことはよくあることですが、大きく「教師あり学習」による予測モデルの学習と「教師なし学習」によるクラスタリングの2つのアプローチが使われることが多いように思います。
教師あり学習は素直な方法ですが、学習にあたり文章に対する正解カテゴリのアノテーションを付与する必要があり、入力データの作成にあたってかなり骨の折れる作業を強いられますし、時が経てば対応したいカテゴリが増減する可能性もあります。そこで今回は、教師なし学習であるクラスタリングの強力な手法のt-SNEとUMAPを使って、文章のクラスタリングを可視化するカテゴリ分けを実装して実際に動かしてみました。
教師なし学習によるクラスタリング
教師なし学習におけるクラスタリングは、k-means法や主成分分析(PCA)などの古典的な手法をはじめ様々なものがありますが、いずれの手法も各データが互いに「どのように関係しているのか」を理解し、同様のグループを発見するために用いられます。入力データ間の特徴から似通ったデータ群を探すための手法なので、正解のカテゴリをデータに付与する必要はありません。同じ教師なし学習では次元圧縮という手法も存在し、これは元の特徴量の情報をなるべく保持したままデータを低次元に落とし込むものです。
t-SNE
t-SNEは次元削減を行う教師なし学習の一つであり、高次元のデータを2次元や3次元に変換して可視化するための手法です。t分布の確率的近傍埋め込み法を用いて高次元のデータを次元圧縮し、PCAなどの手法よりも複雑で高次元のデータであっても有効なことが多いです。「ティースニー」と読みます。UMAP
こちらも次元削減を行う教師なし学習の一つであり、多様体学習によるデータの可視化ができます。2018年に提案されたかなり新しい手法です。t-SNEと比べて高速に動作し、計算時間が埋め込み次元数と比例せず一定時間で動作する特徴があります。3次元を超えた圧縮もできるそうです。実装
Google Colaboratoryでコードを書いて実装しました。簡単な流れは以下の通りです。- 文章の形態素解析ツールJuman++ V2と日本語学習済みBERTモデルのダウンロードとインストール
- 形態素解析結果のデータをBERTで次元圧縮するための関数を定義
- Juman++ V2を使って形態素解析を実行し、2で定義した関数を用いてベクトル化
- t-SNEとUMAPを使って文章ベクトルの次元圧縮をしグラフを描画
| content | category |
| 記事文章1 | カテゴリ名1 |
| 記事文章2 | カテゴリ名2 |
1. Juman++ V2とBERTのインストール
まずは次元圧縮をする対象となるベクトルを与えるために、文章データをベクトル化する必要があります。このベクトル化の方法もたくさんありますが、今回は日本語であらかじめ学習されたBERTモデルを用いて実現します。実装にあたっては京都大学の黒橋・褚・村脇研究室が公開しているJuman++ V2.0.0-rc3と学習済みBERTを使いました。Juman++ V2
Juman++はRNN言語モデルを用いており、文章の構文・格解析なども解析できるKNPに対応しているのが特徴です。V1のバージョンでは解析速度が遅いという問題がありましたが、V2からは実行速度がおよそ100倍程度高速になっています。現在公開されているバージョンはJuman++ V2.0.0-rc3となっています。以下のコードブロックを実行すればJuman++ V2のインストールが完了します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
!wget -O jumanpp-2.0.0-rc3.tar.xz https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc3/jumanpp-2.0.0-rc3.tar.xz !tar xf jumanpp-2.0.0-rc3.tar.xz %mkdir -p jumanpp-2.0.0-rc3/build %cd jumanpp-2.0.0-rc3/build !cmake .. -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/usr/local !make !make install %cd /content !pip install pyknp from pyknp import Juman, BList, KNP juman = Juman("jumanpp", multithreading=True) |
|
1 2 3 |
juman_result = juman.analysis("これはテスト文章ですよ。") for jr in juman_result: print(jr.spec()) |
|
1 2 3 4 5 6 7 |
これ これ これ 指示詞 7 名詞形態指示詞 1 * 0 * 0 NIL は は は 助詞 9 副助詞 2 * 0 * 0 NIL テスト てすと テスト 名詞 6 サ変名詞 2 * 0 * 0 "代表表記:テスト/てすと ドメイン:教育・学習 カテゴリ:抽象物" 文章 ぶんしょう 文章 名詞 6 普通名詞 1 * 0 * 0 "代表表記:文章/ぶんしょう カテゴリ:抽象物" です です だ 判定詞 4 * 0 判定詞 25 デス列基本形 27 NIL よ よ よ 助詞 9 終助詞 4 * 0 * 0 NIL 。 。 。 特殊 1 句点 1 * 0 * 0 NIL |
学習済みBERT
公開されている学習済みBERTモデルは色々ありますが、今回はPyTorch版のBERT_LARGEを使いました。現在ではTransformerベースで作成された機械学習モデルを利用できるtransformersというライブラリをインストールして読み込ませることで使用可能になっています。|
1 2 3 4 5 6 7 8 9 |
!wget -O "Japanese_L-24_H-1024_A-16_E-30_BPE_WWM_transformers.zip" "http://nlp.ist.i.kyoto-u.ac.jp/DLcounter/lime.cgi?down=http://lotus.kuee.kyoto-u.ac.jp/nl-resource/JapaneseBertPretrainedModel/Japanese_L-24_H-1024_A-16_E-30_BPE_WWM_transformers.zip&name=Japanese_L-24_H-1024_A-16_E-30_BPE_WWM_transformers.zip" !unzip "Japanese_L-24_H-1024_A-16_E-30_BPE_WWM_transformers.zip" !pip install transformers from transformers import BertTokenizer, BertConfig, BertModel config = BertConfig.from_json_file('/content/Japanese_L-24_H-1024_A-16_E-30_BPE_WWM_transformers/config.json') model = BertModel.from_pretrained('/content/Japanese_L-24_H-1024_A-16_E-30_BPE_WWM_transformers/pytorch_model.bin', config=config) bert_tokenizer = BertTokenizer('/content/Japanese_L-24_H-1024_A-16_E-30_BPE_WWM_transformers/vocab.txt', do_lower_case=False, do_basic_tokenize=False) |
2. BERTモデルで文章をベクトル化する関数を定義
形態素解析された文章を受け取って学習済みBERTで文章をベクトル化するための関数vectorizeを定義します。ここではBERTの出力層の結果を返すのではなく、最後の隠れ層が出力するベクトルを抽出して返すようにしています。|
1 2 3 4 5 6 7 8 9 10 11 12 |
import numpy as np import torch def vectorize(text): tokens = bert_tokenizer.convert_tokens_to_ids(text) tokens_tensor = torch.tensor(tokens).reshape(1, -1) model.eval() with torch.no_grad(): all_encoder_layers = model(tokens_tensor, return_dict=True, output_hidden_states=True)["hidden_states"] embedding = all_encoder_layers[-1].cpu().numpy()[0] return np.max(embedding, axis=0) |
3. Juman++ V2とBERTで文章をベクトル化
juman.analysisによって文章を形態素解析することができます。解析結果から品詞や活用型などの情報を抜き出すことができます。解析結果からどのような情報が得られるか詳しくはこちらをご覧ください。今回は記号などの特殊な単語情報と辞書に存在しない単語と数詞を抜いて単語の原形だけを残しています。BERTモデルに入力する文章の先頭と末尾にそれぞれ [CLS]と [SEP]のトークンをつける必要があります。さらに今回用いるBERTモデルは入力ベクトルの次元数が128でしたので、単純に形態素解析した後の単語リストのうち126番目までのリストを抽出してトークンを付与しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
bert_v=[] for index, sentence in sentences.iterrows(): words = [] parse_result = juman.analysis(sentences["content"]) for mrph in parse_result.mrph_list(): if mrph.hinsi != "特殊" and mrph.hinsi != "未定義語" and mrph.bunrui != "数詞": words += [mrph.genkei] input_list = ["[CLS]"] + words[:126] + ["[SEP]"] bert_v += [vectorize(input_list)] sentences=sentences.assign(bert_v=bert_v) |
4. t-SNEとUMAPを使って次元圧縮
t-SNEとUMAP、および結果をグラフ化するための準備をします。|
1 2 3 4 5 6 7 |
!pip install japanize-matplotlib import matplotlib.pyplot as plt import japanize_matplotlib !pip install umap-learn import umap from sklearn.manifold import TSNE |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# UMAP embedding = umap.UMAP().fit_transform(sentences["bert_v"].tolist()) sentences=sentences.assign(umap_x=embedding[:,0]) sentences=sentences.assign(umap_y=embedding[:,1]) for c in sentences['category'].unique(): plt.scatter(sentences[sentences.category == c]["umap_x"], sentences[sentences.category == c]["umap_y"], label=c) plt.legend() plt.title("UMAP") plt.savefig('umap.png') # t-SNE plt.clf() tsne_model = TSNE(n_components=2) tsne = tsne_model.fit_transform(sentences["bert_v"].tolist()) sentences=sentences.assign(tsne_x=tsne[:,0]) sentences=sentences.assign(tsne_y=tsne[:,1]) for c in sentences['category'].unique(): plt.scatter(sentences[sentences.category == c]["tsne_x"], sentences[sentences.category == c]["tsne_y"], label=c) plt.legend() plt.title("t-SNE") plt.savefig('tsne.png') |
記事文章を用いた実験
これまでの実装で文章データのベクトル化からt-SNEおよびUMAPを使って次元圧縮をして2次元に落とし込むことができます。実際にカテゴリ分類した記事のデータを使って実行していきます。今回は [ペット, 恋愛, 訃報, スポーツ, 野球]の5つのカテゴリに分類されるであろう記事を各200件ずつ入力データとしました。分類がされた記事のデータ例は以下の通りです。各カテゴリについて1記事ずつ抽出したものです。
 結果は以下のようになりました。
結果は以下のようになりました。
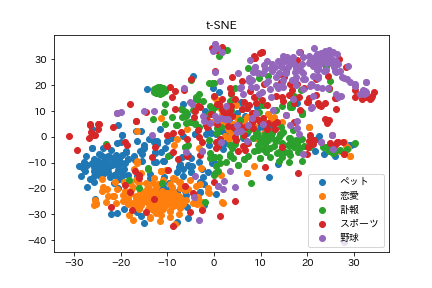
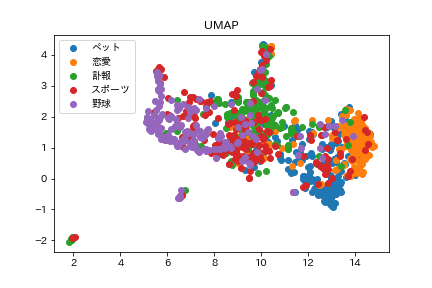
t-SNEの方はデータ点自体はまばらに広がっていて、UMAPはギュッと詰まっている感じになりました。UMAPの方に外れ値のような結果が少し多いです。今回付与した5つのカテゴリごとに点を着色してみると、スポーツ系の記事以外は思ったより分離できているようでした。ペット系と恋愛系の記事は近く、野球とは遠くなるというのも見てわかるかと思います。芸能人などの訃報系の記事はそれらとはまた違う空間に固まっているようです。
スポーツ系の記事がどちらの手法でもうまく分類できていなかった問題は、おそらく「スポーツ」という括りが大雑把になっていることや、実際にはスポーツ選手の恋愛報道の記事など別の要素が多く入っていたことが原因だと考えられます。
カテゴリがさらに増えた場合や、3次元空間に圧縮する場合ではまた結果が変わってくるかと思いますが、この方法で2次元空間への圧縮によって記事の傾向を掴むことができそうなことが分かります。今後カテゴリ不明な記事があっても、同じ方法で圧縮してその点から近いデータ点のカテゴリの割合などを見て、カテゴリ分類を予測したりできそうです。
また、新しい手法であるUMAPはt-SNEよりも実行時間が早いと言われているため、計算時間の計測も行いました。
| 手法 | 計算時間(秒) |
|---|---|
| t-SNE | 13.47 |
| UMAP | 7.23 |
おわりに
今回は教師なし学習のデータ次元圧縮としてよく用いられるt-SNEと、新しい手法であるUMAPの2つを使ってベクトル化された文章情報を2次元に落とし込み、BERTを使って文章をベクトル化する部分についても実装することができました。文章データとしていくつかの記事データをカテゴリを付与して実行し、2次元空間へ圧縮されたグラフから、大まかにカテゴリ分類などのクラスタリングが出来ることがわかりました。3次元空間への圧縮や文章のベクトル化の仕方、PCAとの組み合わせなどまだ改良できる余地はたくさんあるので色々試していきたいです。
また、本記事執筆において形態素解析ツールであるJuman++ V2および学習済みBERTモデルは以下より引用しました。
京都大学大学院情報学研究科知能情報学専攻黒橋・褚・村脇研究室 (https://nlp.ist.i.kyoto-u.ac.jp/ )
明日はyoshishinさんによる「個人ウェブサービス開発開始から3ヶ月で月間5万PVを達成した話」に関しての記事です。
引き続き、GMOアドマーケティング Advent Calendar 2021 をお楽しみください!
■エンジニア採用ページ ~福利厚生や各種制度のご案内はこちら~
https://note.gmo-ap.jp/n/n02cbeb6edb0d
■noteページ ~ブログや採用、イベント情報を公開中!~
https://note.gmo-ap.jp/


