日に日に溜まっていく膨大なデータを解析したり、機械学習モデルに投げるデータの前処理をしたりするための大規模データの分散処理フレームワークは幾つかありますが、その技術を活用するためにクラウド上のリソースを使ってビッグデータを処理したいケースがあるかと思います。
今回はGoogle Cloud Platformの各種サービスを複合的に活用し、特にCloud WorkflowsとCloud Functionsを組み合わせることで、Dataprocのクラスタを動的に作成・削除しながらジョブを実行する方法について書いていきます。
やりたいこと
Dataprocは、Apache SparkやApach Hadoopなどの分散処理のフレームワークをGoogle Cloud Platform(以下 GCP)マネージドで動かすためのサービスです。簡単な流れとしては、GCPでインスタンスを起動し、そこに実行用のクラスタを作成した上でジョブを投げて任意の処理を実行します。 各種処理はブラウザ上からGCPのコンソール画面上からでも、gcloudコマンドを用いてターミナル上からでも実行可能ですし、幾つかの言語にクライアントライブラリが存在しているためプログラムから実行できます。今回のユースケースでは、処理の内容を条件分岐で変更したり、Dataprocによる処理の前後に簡単な別処理を入れ込んだりするワークフローを考慮しつつ、GCPのStorageやBigQueryで管理している大規模なデータを処理させたい場合を考えます。さらに、この一連の処理を定期的なバッチによって実施したいと仮定します。
使用するGCPサービス
今回使うGCPのサービスは以下の通りです。- Dataproc
- 大規模データの分散処理用のサービス
- 「クラスタ作成」と「ジョブ実行」によってデータが処理される
- Cloud Storage (以下Storage)
- Dataprocのクラスタ作成時の初期化ファイルおよびジョブ実行のプログラムファイルを格納する
- Cloud Workflows (以下Workflows)
- サーバレスでGCPの各種サービスを組み合わせてワークフローを定義する
- ワークフローには組み込みメソッドも使える
- Cloud Functions (以下Functions)
- サーバレスに実行できる関数を定義する
- Workflowsから実行できる
- 本記事では第1世代の使用を想定しています
- Cloud Scheduler (以下Scheduler)
- cronと同様の形式で実行日時や頻度を設定できるジョブスケジューラー
- 定期バッチ実行のトリガー用として使える
実装
Workflows
本記事の肝です。GCPのブラウザコンソールを開いて「workflows」で検索し、適宜APIを有効にして新規のワークフローを作成します。今回は「test_workflow」という名前でワークフローを作成しました。説明文やリージョン、サービスアカウントの設定は各環境に合わせて適宜設定してください。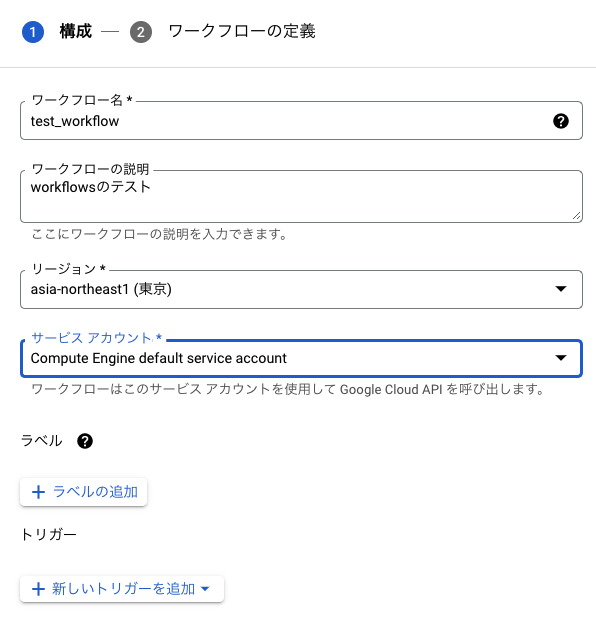 「新しいトリガーを追加」をクリックし、「Cloud Scheduler」を選択して定期実行用のトリガーを作成します。Schedulerの作成画面が出てくるので、名前やリージョン、頻度などお好みの設定で作成してください。
「新しいトリガーを追加」をクリックし、「Cloud Scheduler」を選択して定期実行用のトリガーを作成します。Schedulerの作成画面が出てくるので、名前やリージョン、頻度などお好みの設定で作成してください。  続いてワークフローを定義します。Workflowsではyamlかjsonを記述することでワークフローを定義できます。ワークフロー中の1つ1つの実行処理単位は
steps として定義でき、その中で
call などのメソッドによってstepの中身で実行する処理を決めることができます。ちなみにstepの名前は日本語にも対応しています。
続いてワークフローを定義します。Workflowsではyamlかjsonを記述することでワークフローを定義できます。ワークフロー中の1つ1つの実行処理単位は
steps として定義でき、その中で
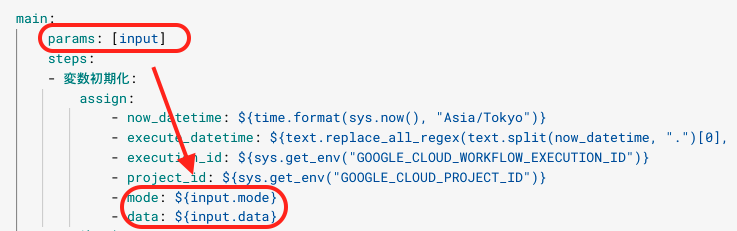
call などのメソッドによってstepの中身で実行する処理を決めることができます。ちなみにstepの名前は日本語にも対応しています。今回は以下のようにコーディングしてみました。Schedulerから送られてきたメッセージを params: [input] として受け取り、Dataprocのジョブに投げるデータ引数を data 、条件分岐のためのパラメータを mode としています。また、Workflowsには組み込み関数も多数用意されており、以下の例ではtime、sysライブラリのメソッドを使用しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
main: params: [input] steps: - 変数初期化: assign: - now_datetime: ${time.format(sys.now(), "Asia/Tokyo")} - execute_datetime: ${text.replace_all_regex(text.split(now_datetime, ".")[0], "[-T:]", "")} - execution_id: ${sys.get_env("GOOGLE_CLOUD_WORKFLOW_EXECUTION_ID")} - project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")} - mode: ${input.mode} - data: ${input.data} - ロギング: call: sys.log args: text: ${now_datetime+":"+execution_id+" , "+project_id} severity: DEBUG - Dataprocクラスタ作成: call: http.post args: url: ${"https://asia-northeast1-" + project_id + ".cloudfunctions.net/create_cluster_test"} body: project_id: ${project_id} data: ${data} execute_datetime: ${execute_datetime} auth: type: OIDC result: response - 条件分岐: switch: - condition: ${mode == "normal"} next: 通常ジョブ実行 - condition: ${mode == "ex"} next: EXジョブ実行 next: 結果出力 - 通常ジョブ実行: call: http.post args: url: ${"https://asia-northeast1-" + project_id + ".cloudfunctions.net/submit_job_test"} body: project_id: ${project_id} data: ${data} execute_datetime: ${execute_datetime} auth: type: OIDC result: response next: 結果出力 - EXジョブ実行: call: http.post args: url: ${"https://asia-northeast1-" + project_id + ".cloudfunctions.net/submit_job_test_ex"} body: project_id: ${project_id} data: ${data} execute_datetime: ${execute_datetime} auth: type: OIDC result: response next: 結果出力 - 結果出力: return: ${response} |
Workflowsでは定義ファイルを記述するとリアルタイムで隣にワークフローを可視化したグラフを表示してくれます。処理の流れを確認しながらソースコードを書けるため非常に便利です。
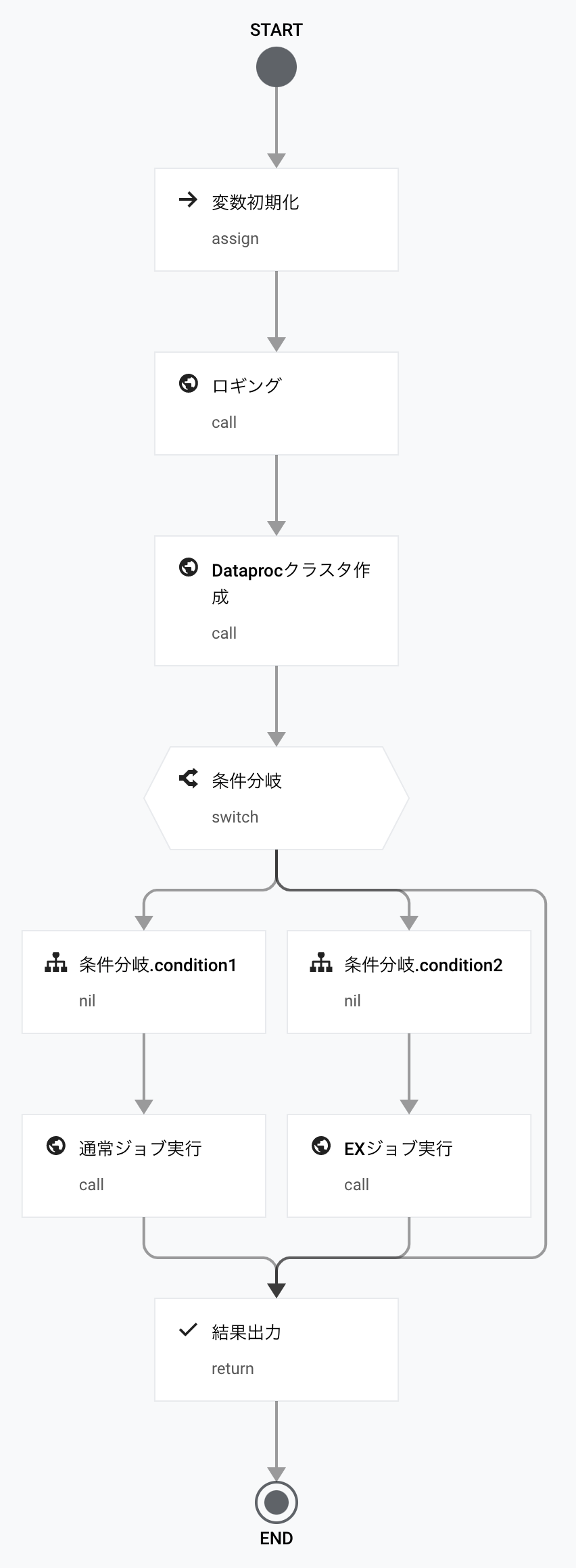
Functions
次にWorkflowsから実行する関数を定義します。今回の例では- create_cluster_test – Dataprocのクラスタを作成するための関数
- submit_job_test – 作成したクラスタに投げる通常ジョブの関数
- submit_job_test_ex – 作成したクラスタに投げる別のジョブの関数
GCPのブラウザコンソールを開いて「functions」で検索し、適宜APIを有効にして新規の関数をそれぞれ作成します。以下は create_cluster_test 関数を作成する例です。ここでトリガーはHTTPにしてください。WorkflowsからFunctionへはHTTPエンドポイントの呼び出しのみ対応しているためです。
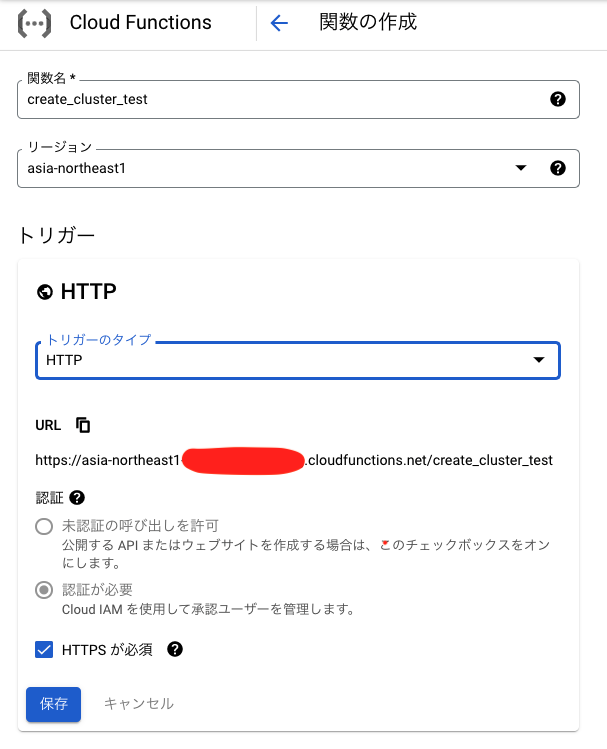
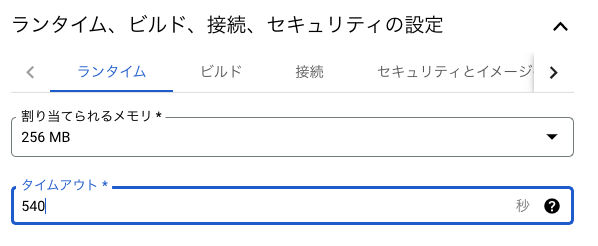
また、 create_cluster_test 関数ではランタイム内のタイムアウト設定値を大きい値にしておきます。デフォルト値は60秒ですが、Dataprocのクラスタ作成にはおおよそ1分半程度かかるため、通常設定のままだとタイムアウトしてWorkflowsがエラー終了してしまうのを防ぐためです。最大値で540秒(9分)まで設定できるため、今回はこの値で設定しています。また、ジョブ実行関数に関してはクラスタにジョブを正常に投げられた時点で関数が終了するため、基本的にタイムアウト時間を別途設定する必要はありません。
create_cluster_test および submit_job_test 関数のソースコードの例は以下の通りです。今回はPython3.9を選択して関数を作成しています。
submit_job_test_ex 関数ではジョブ設定中の main_python_file_uri のPythonファイル名を execute_ex.py に変えてデプロイしています。エントリポイント名もそれぞれ定義した関数名に変更します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
import json from google.cloud import dataproc_v1 as dataproc from google.protobuf import duration_pb2 def create_cluster(request): request_json = request.get_json() if request_json and 'project_id' in request_json: project_id = request_json["project_id"] else: return if request_json and 'execute_datetime' in request_json: execute_datetime = request_json["execute_datetime"] else: return if request_json and 'data' in request_json: data = request_json["data"] else: return print(project_id+":"+json.dumps(data)) cluster_client = dataproc.ClusterControllerClient( client_options={"api_endpoint": f"{data['region']}-dataproc.googleapis.com:443"} ) duration_message = duration_pb2.Duration() cluster = { "project_id": project_id, "cluster_name": data["cluster_name"]+"-"+execute_datetime, "config": { "master_config": { "num_instances": 1, "machine_type_uri": data["dataproc_type"], "disk_config": { "boot_disk_size_gb": 200 }, }, "worker_config": { "num_instances": int(data["worker_num"]), "machine_type_uri": data["dataproc_type"], "disk_config": { "boot_disk_size_gb": 200 }, }, "initialization_actions": [{ "executable_file": f"gs://{data['bucket_name']}/initialize.sh" }], "lifecycle_config": {"idle_delete_ttl": duration_pb2.Duration(seconds=int(data["ttl"]))}, }, } operation = cluster_client.create_cluster( request={"project_id": project_id, "region": data["region"], "cluster": cluster} ) result = operation.result() print(f"Cluster created successfully: {result.cluster_name}") return f"Cluster created successfully: {result.cluster_name}" |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
import json from google.cloud import dataproc_v1 as dataproc def submit_job(request): request_json = request.get_json() if request_json and 'project_id' in request_json: project_id = request_json["project_id"] else: return if request_json and 'execute_datetime' in request_json: execute_datetime = request_json["execute_datetime"] else: return if request_json and 'data' in request_json: data = request_json["data"] else: return print(project_id+":"+json.dumps(data)) job_client = dataproc.JobControllerClient( client_options={"api_endpoint": f"{data['region']}-dataproc.googleapis.com:443"} ) job = { "placement": {"cluster_name": data["cluster_name"]+"-"+execute_datetime}, "pyspark_job": { "main_python_file_uri": f"gs://{data['bucket_name']}/execute.py", "args": [ "--tip_criterion", data["tip_criterion"], ], "python_file_uris": [], "file_uris": [], }, } job_client.submit_job_as_operation( project_id=project_id, region=data["region"], job=job ) return "Job finished successfully" |
|
1 2 |
google-cloud-dataproc protobuf |
Scheduler
先ほどWorkflowsを作成する時に併せて作成したSchedulerについて、設定を追加します。GCPのブラウザコンソールを開いて「scheduler」で検索し、先ほど作成したジョブスケジューラーの編集画面に進んでください。その中に「本文」を設定する欄があると思います。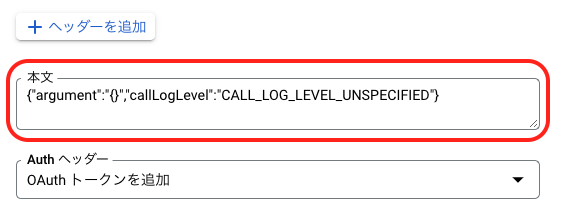 この本文中の
argument の中身を以下のように書き換えます。keyとvalueの値共にダブルクォーテーションで囲う必要があるため、その中に記述する変数は全てエスケープする必要があることに注意してください。
この本文中の
argument の中身を以下のように書き換えます。keyとvalueの値共にダブルクォーテーションで囲う必要があるため、その中に記述する変数は全てエスケープする必要があることに注意してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{"argument": "{\"mode\":\"normal\", \"data\":{ \"tip_criterion\":\"2\", \"bucket_name\":\"dataproc_test\", \"cluster_name\":\"dataproc-test\", \"dataproc_type\":\"n1-standard-4\", \"region\":\"asia-southeast1\", \"zone\":\"asia-southeast1-b\", \"worker_num\":\"2\", \"ttl\":\"300\"} }" } |
Workflowsのyamlファイル中の params で受け取り、Functionsを呼び出す際に body で引き渡して、Functions内では request 引数で受け取っています。複雑ですが、このようにユーザーが設定したパラメータをWorkflowsやFunctionsで引き回すことも可能です。(実際は外部からパラメータを読み込んで使ったほうが良いとは思います)


Storage
Dataproc内で実行するプログラムファイルなどはStorageに保存しておき、実行時に呼び出します。Functionsで設定したGCPのブラウザコンソールを開いて「storage」で検索し、適宜APIを有効にしておきます。必要となるのはバケットとその中に入れるファイル群です。バケット名は先述のSchedulerの設定内で bucket_name: dataproc-test としているため、この名前で作成します。一意の名前で作成してくださいと言われる場合は他の名前を適宜設定しましょう。
次に、作成したバケット内に保存しておくプログラムを作成します。今回はDataprocの中でPysparkを用いてソースコードを作成し実行します。Dataprocのクラスタを作成する時に実行する initialize.sh は以下の通りです。
|
1 2 3 |
#!/usr/bin/env bash pip install pyspark |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import argparse import pandas as pd import seaborn as sns from datetime import datetime, timezone, timedelta from pyspark.sql import SparkSession from pyspark.sql import functions as F def parse_parameter(): parser = argparse.ArgumentParser() parser.add_argument("--tip_criterion", type=int) return parser if __name__ == '__main__': print('NORMAL start datetime:' + str(datetime.now(tz=timezone(timedelta(hours=9))))) args = parse_parameter().parse_args() tip_criterion = args.tip_criterion spark = SparkSession.builder \ .appName('Basics') \ .getOrCreate() sdf = spark.createDataFrame(sns.load_dataset('tips')) sdf = sdf.filter(F.col('tip') > tip_criterion).orderBy('tip') sdf.show(20) print('NORMAL end datetime:' + str(datetime.now(tz=timezone(timedelta(hours=9))))) |
実行
ここまで実装できたら早速実行してみましょう。Schedulerでは定期実行のスケジュールが組まれていると思いますが、即時実行も可能です。ブラウザからGCPコンソールを開き、Schedulerの一覧画面から「今すぐ実行」ボタンを押してジョブを実行します。SchedulerからWorkflowsが発火し、まずDataprocのクラスタがプロビジョニング状態に入ると思います。クラスタ名は create_cluster_test 関数で定義した通り、 data["cluster_name"]+"-"+execute_datetime となっているのがわかると思います。クラスタ作成が終わって少し経つとジョブが実行されます。Dataprocのクラスタ詳細をブラウザ上で確認すると下のような状態になっているはずです。
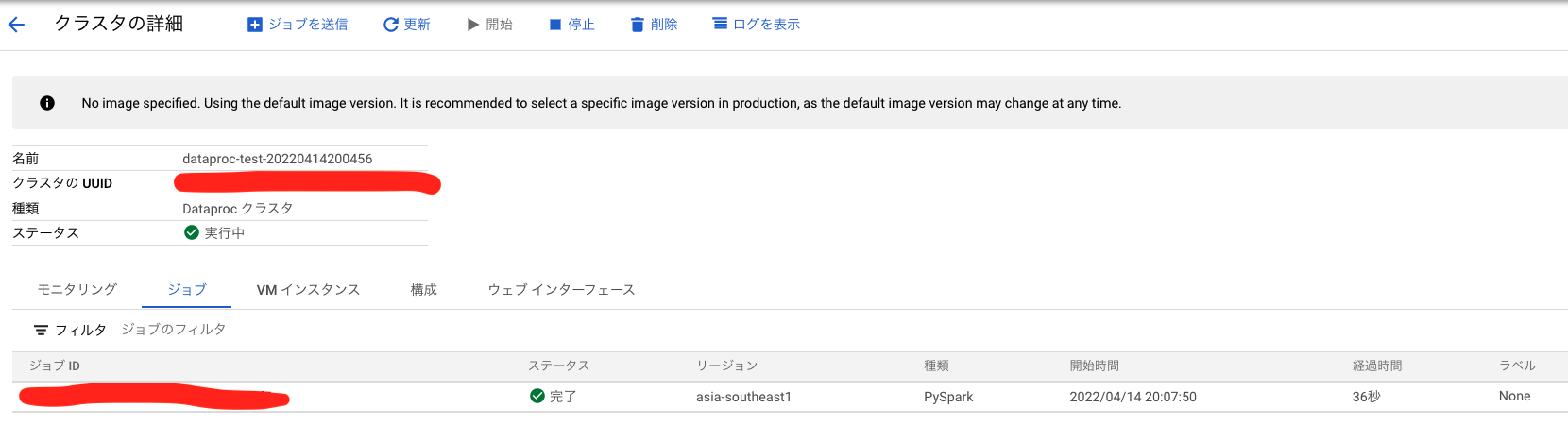
クラスタの詳細からジョブ一覧を確認して、今回実行されたジョブの詳細を見てみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
NORMAL start datetime:2022-04-14 20:08:03.187070+09:00 (省略) +----------+----+------+------+----+------+----+ |total_bill| tip| sex|smoker| day| time|size| +----------+----+------+------+----+------+----+ | 20.23|2.01| Male| No| Sat|Dinner| 2| | 12.74|2.01|Female| Yes|Thur| Lunch| 2| | 15.48|2.02| Male| Yes|Thur| Lunch| 2| | 15.98|2.03| Male| No|Thur| Lunch| 2| | 24.27|2.03| Male| Yes| Sat|Dinner| 2| | 28.55|2.05| Male| No| Sun|Dinner| 3| | 15.01|2.09| Male| Yes| Sat|Dinner| 2| | 22.82|2.18| Male| No|Thur| Lunch| 3| | 12.16| 2.2| Male| Yes| Fri| Lunch| 2| | 14.73| 2.2|Female| No| Sat|Dinner| 2| +----------+----+------+------+----+------+----+ only showing top 10 rows NORMAL end datetime:2022-04-14 20:08:23.671445+09:00 |
さらに、Schedulerで設定した本文の内容を以下のように変更してもう一度実行してみましょう。 mode をexに変更し、 tip_criterion を3に増やしてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{"argument": "{\"mode\":\"normal\", → \"mode\":\"ex\", \"data\":{ \"tip_criterion\":\"2\", → \"tip_criterion\":\"3\", \"bucket_name\":\"dataproc_test\", \"cluster_name\":\"dataproc-test\", \"dataproc_type\":\"n1-standard-4\", \"region\":\"asia-southeast1\", \"zone\":\"asia-southeast1-b\", \"worker_num\":\"2\", \"ttl\":\"300\"} }" } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
EX start datetime:2022-04-14 20:37:06.885348+09:00 (省略) +----------+----+------+------+----+------+----+ |total_bill| tip| sex|smoker| day| time|size| +----------+----+------+------+----+------+----+ | 14.83|3.02|Female| No| Sun|Dinner| 2| | 13.94|3.06| Male| No| Sun|Dinner| 2| | 16.93|3.07|Female| No| Sat|Dinner| 3| | 17.92|3.08| Male| Yes| Sat|Dinner| 2| | 30.14|3.09|Female| Yes| Sat|Dinner| 4| | 32.9|3.11| Male| Yes| Sun|Dinner| 2| | 26.88|3.12| Male| No| Sun|Dinner| 4| | 26.86|3.14|Female| Yes| Sat|Dinner| 2| | 20.08|3.15| Male| No| Sat|Dinner| 3| | 15.81|3.16| Male| Yes| Sat|Dinner| 2| +----------+----+------+------+----+------+----+ only showing top 10 rows EX end datetime:2022-04-14 20:37:27.157861+09:00 |
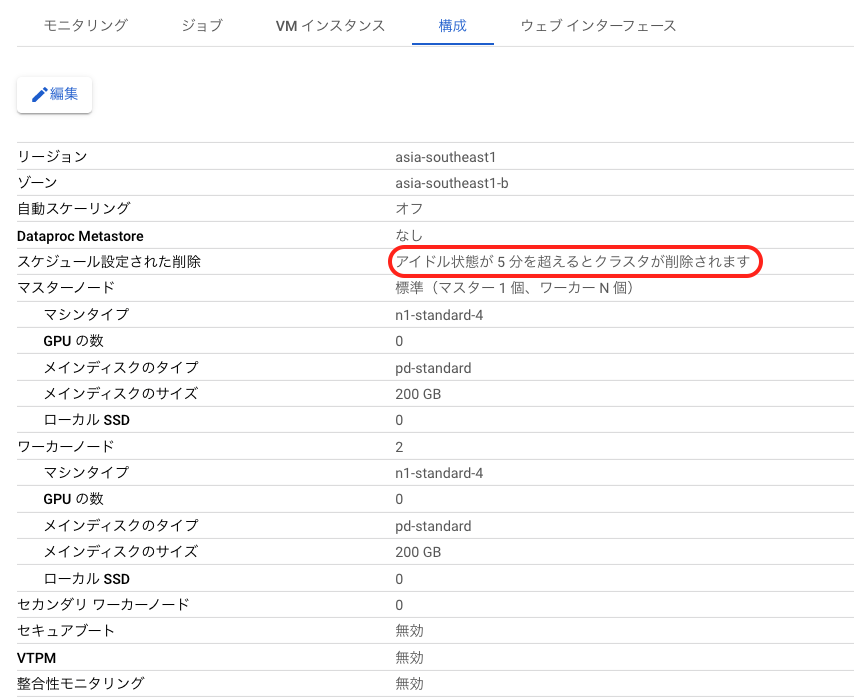
なお、今回はSchedulerからWorkflowsを実行して一連のワークフローを実行していますが、WorkflowsのトリガーURLとargumentを設定してあげれば実行できます。与える値も必要に応じて変更できるため、Workflowsの定義と併せて柔軟にワークフローを設定・実行できます。
まとめ
今回は、GCPのサービスであるCloud FunctionsとCloud Workflowsを中心に、Cloud SchedulerをトリガーとしてDataprocで大規模データの分散処理をするための柔軟なワークフローを作成する方法について説明しました。Workflowsは比較的最近ローンチされたサービスで、組み込み関数の対応もどんどん増えているため、使い方によってはかなり強力なツールとなるのではないかと思います。実装例では最終的に出力は普通にprintしているだけでしたが、もちろんBigQueryからデータを読み、複雑な処理を施した後に出力用のBigQueryのテーブルに書き出すということもできます。
他にもワークフローを構築して大規模データの処理をさせる方法は幾つかあるかと思いますが、今回使用したGCPのサービスはどれもコストがかなり安価であり、Dataprocのクラスタも必要な時にのみ稼働する設定になっているため、柔軟なワークフローを構築しつつ全体的に安価に済ませられる一つのケースとして紹介してみました。


