
みなさんこんにちは、GMOアドマーケティングのM.Hです。
今回はXAIの一つである「SHAP」というライブラリについて、自然言語処理向けの機械学習モデルの観点から書いていこうと思います。
はじめに
昨今ではもはや聞き馴染みとなった「機械学習」や「AI」ですが、そのモデルはコンピューティングシステムの計算能力の向上と共に加速度的な速さで複雑化してきています。もちろんそのようなモデルを使ってビジネスに貢献ができれば嬉しいのですが、モデルの中身に関してはブラックボックス化されていることがほとんどで、「何が要因となってこの結果がもたらされたのか?」という部分はなおざりになりがちです。機械学習のビジネス利用が当たり前に行われるようになった今日では、こういった原因や要因に関して人間がわかる形で示そうとする理論も議論されており、それらを総称してexplainable AI(説明可能なAI・XAI)として発展してきています。
今回取り上げるSHAPという技術はそんなXAIの1つとして提唱されました。arxivで公開されている元論文はこちらです。今では代表的な技術としてライブラリも整備され、Githubで公開されていて簡易的に使うことができます。回帰モデルや決定木モデルなど代表的な機械学習モデルに関しては専用の関数も用意されており非常に使いやすいです。そのような関数の使い方は既に多数のサイトやブログなどで紹介がありますが、本記事では自然言語処理を担う機械学習モデルであるBERTを用いて日本語文章のネガポジ判定をした時のSHAPの使い方とその結果について簡単に説明していきます。
本記事で書くこと
- XAIライブラリであるSHAPの大まかな解説
- 事前学習済みモデルをインポートし、文章をネガポジ判定した時のSHAPライブラリの使い方
- SHAPライブラリの結果確認
本記事で書かないこと
- SHAPの詳細なアルゴリズムや数学的議論
- 他のXAIアルゴリズムの紹介
SHAPについて
機械学習モデルの説明ができることを「説明可能性」あるいは「解釈可能性」と言います。説明や解釈などと一言でいっても、実際にはその方法にはいくつかありますが主に以下2つがあります。- 機械学習モデルの近似
- モデルの予測値と特徴量の関係を解釈
元々は古典的な協力ゲーム理論で用いられていたShapley値が元です。これはゲームに参加するプレイヤー各々の貢献度を考慮して利得を公正に分配することを目的とした計算方法ですが、プレイヤーを特徴量、ゲームをモデルの予測によってえられる予測とすれば、各特徴量のモデルの予測における貢献度を分配するアプローチをとることができます。これにより「モデルの予測値と特徴量の関係を解釈」することが可能です。
しかし、このままの計算だと特徴量が増えればその分特徴量同士の組み合わせの数も膨大に増えていくため計算が終わらない問題が発生します。そこで条件付き期待関数への近似によって計算量を減らす工夫を取り入れたものがSHAPになります。
実践
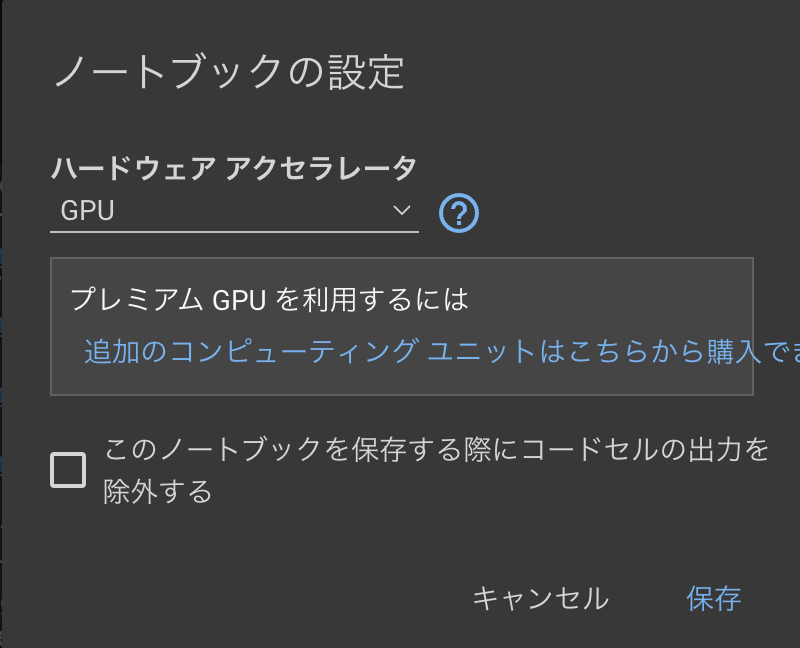
SHAPライブラリはpipを使って手早くマシンにインストールして利用することができます。今回はGoogle ColaboratoryのGPUランタイムを駆使して実装していきます。Google Colaboratoryを開いたらまずはメニューの「ランタイム」→「ランタイムをタイプの変更」を選択して「ハードウェア アクセラレータ」をGPUに設定して保存します。
 まずは必要なライブラリをインストールしていきます。
まずは必要なライブラリをインストールしていきます。
|
1 2 3 4 5 6 7 |
!pip install shap !pip install transformers !pip install sentencepiece !pip install fugashi !pip install ipadic !pip install pytorch-lightning !pip install japanize-matplotlib |
トークナイザとして東北大学の cl-tohoku/bert-base-japanese-whole-word-masking を利用し、文章のネガティブ/ポジティブ分類として daigo/bert-base-japanese-sentiment を使用します。
pipelineは”sentiment-analysis”を指定します。
|
1 2 3 4 5 6 7 8 9 10 |
from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer import torch # モデルの読み込み model = AutoModelForSequenceClassification.from_pretrained('daigo/bert-base-japanese-sentiment') tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking') # パイプラインの準備 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") pred = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer, device=device, top_k=None) |
今回は出力がネガティブかポジティブなのでExplainerで直接指定しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import numpy as np import scipy as sp import shap # カスタムのExplainer設定 def f(x): tv = torch.tensor([tokenizer.encode(v, padding='max_length', max_length=128, truncation=True) for v in x]).cuda() attention_mask = (tv!=0).type(torch.int64).cuda() outputs = model(tv,attention_mask=attention_mask)[0].detach().cpu().numpy() scores = (np.exp(outputs).T / np.exp(outputs).sum(-1)).T val = sp.special.logit(scores) return val explainer = shap.Explainer(f, tokenizer, output_names=["ポジティブ", "ネガティブ"]) |
| 文章 | 備考 | 期待される結果 |
| とても面白かったです。ストーリーの作り方や絵の見せ方などセンスの塊だと思ってます! | ポジティブ要素の強い単語が多く含まれる文章 | ポジティブ |
| なんでそんなこと言うのさ? | 単語としては中立のものしかないが、ニュアンス的に苛立ちが含まれていそうな文章。かなり口語。 | ネガティブ |
| 最近は嫌なことばかりが続いていて相当落ち込んでいます。 | ネガティブ要素の強い単語が多く含まれる文章 | ネガティブ |
| 最近は嫌なことばかりが続いていて相当落ち込んでいます。でもこれで励まされました。 | 上の文章を打ち消す状況文を追加 | ポジティブ |
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd sentences = pd.Series( ["とても面白かったです。ストーリーの作り方や絵の見せ方などセンスの塊だと思ってます!", "なんでそういうこと言うのさ?", "最近は嫌なことばかりが続いていて相当落ち込んでいます。", "最近は嫌なことばかりが続いていて相当落ち込んでいます。でもこれで励まされました。"] ) shap_values = explainer(sentences) |
SHAP値は自分で可視化もできますが、既にグラフ化して簡単に可視化できる関数が用意されているためこれを活用していきます。今回は自然言語処理でよく用いられる2つのプロット関数を実行して結果を確認していきます。
用意されたSHAPのプロット用関数は他にもたくさんあり、 shap.plot.* で参照できます。
SHAPを確認する前にまずは普通に予測した結果を確認してみると、以下のような結果になりました。
| 文章 | 結果 | ポジティブ確率 | ネガティブ確率 |
| とても面白かったです。ストーリーの作り方や絵の見せ方などセンスの塊だと思ってます! | ポジティブ | 97.74% | 2.26% |
| なんでそんなこと言うのさ? | ネガティブ | 36.38% | 63.62% |
| 最近は嫌なことばかりが続いていて相当落ち込んでいます。 | ネガティブ | 29.26% | 70.74% |
| 最近は嫌なことばかりが続いていて相当落ち込んでいます。でもこれで励まされました。 | ポジティブ | 88.53% | 11.47% |
確率的には怪しい文章もあるものの、期待した通りの予測にはなっていますね。
早速これらの文章の予測の根拠を探るべくプロットしていきます。
まずは文章ごとにどうネガポジ判定に作用したのかを確認します。
|
1 |
shap.plots.text(shap_values) |
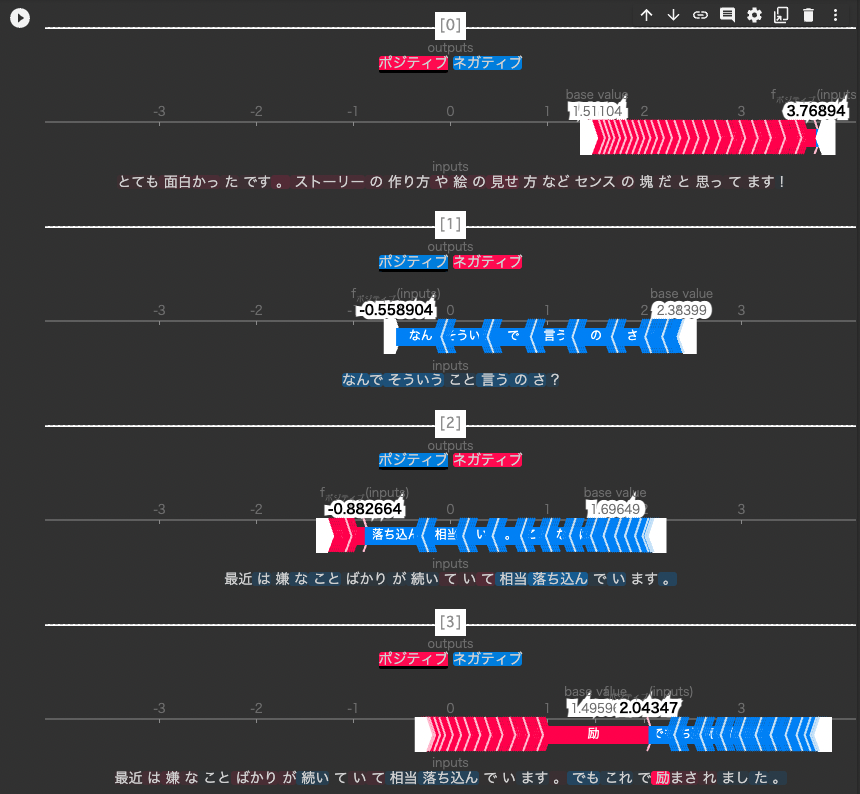
少し分かりづらいですが、この場合では数直線は「ポジティブである確率を計算するための値」を表しており、各単語が出す予測値の全平均が base value になります。
BERTモデルで予測した時に、ある特定の単語について予測値の平均よりもポジティブのニュアンスを含んでいると思われた場合は赤色になり、数直線右側に予測値を押し上げます。逆に、ネガティブのニュアンスを含んでいると思われた場合は青色になり、数直線左側に予測値を引き下げます。
それを全単語について足し合わせた結果が fポジティブ(inputs) になり、 base valueよりも高いか否かを見ることができます。
上3つはポジティブorネガティブへのほとんど一方的な作用が確認できます。
最後の文章はポジティブ側へもネガティブ側へもそれぞれ作用していることがわかります。「最近は〜います。」のネガティブ度合いが上の文章と比べて減っているのは、その後の「でも〜ました。」という逆説的な文章がくるためでしょうか?BERTモデルは文章全体の文脈を考慮するのであり得そうな気がします。
さらに、「落ち込ん」「励」の単語はかなり強く予測値を変動させていることがわかります。
「なんで」「相当」などの単語はこれ単体ではポジティブともネガティブとも取れないですが、文章全体のニュアンスから、「ネガティブの意味で使われている」とモデルが判断してることもわかりますね。
次に、単語ごとにどの程度ポジティブ側に寄与したかを絶対値のランキング形式で示せるようプロットします。
|
1 2 3 |
import japanize_matplotlib shap.plots.bar(shap_values[:,:,"ポジティブ"].mean(0)) |
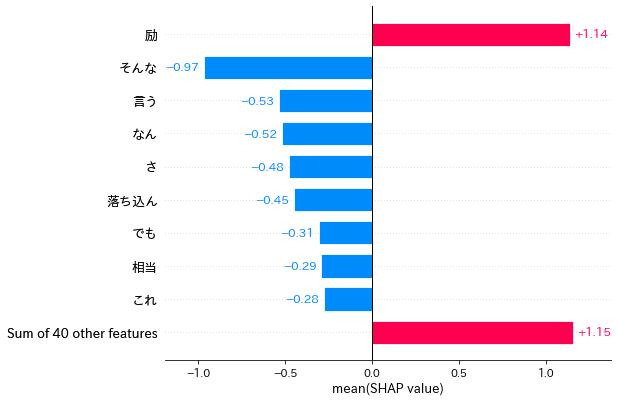 先ほどの「励」「落ち込ん」も上位に入っており、全文章の中では強くネガティブやポジティブ判定に関わることがわかります。
先ほどの「励」「落ち込ん」も上位に入っており、全文章の中では強くネガティブやポジティブ判定に関わることがわかります。本記事では短い文章4つのみしか予測していないため単語数も少ないですが、もっと多くの文章の予測に対してSHAPを使えばより精度の高い単語の寄与度を調査することができるでしょう。
おわりに
今回はXAI技術として有名なライブラリであるSHAPを用いて、日本語の文章をネガポジ判定した時のSHAP値確認とプロットによる可視化まで行いました。自然言語処理はカテゴリ判別や機械翻訳など他にも様々なモデルにチューニングして用いることができますし、SHAP自体は画像認識分野の機械学習モデルにも対応しているため応用力も非常に高いです。今後もSHAPをはじめとしたXAIの技術を使って様々な機械学習モデルを解剖していきたいと思います!
明日はY-Kさんによる「自然言語処理モデル(BERT)で文の意味上の類似度を計算」に関しての記事です。
引き続き、GMOアドマーケティング Advent Calendar 2022 をお楽しみください!
■学生インターン募集中!
https://note.gmo-ap.jp/n/nc42c8a60afaf
■エンジニア採用ページはこちら!
https://note.gmo-ap.jp/n/n02cbeb6edb0d
■GMOアドパートナーズ 公式noteはこちら!
https://note.gmo-ap.jp/


