
この記事は GMOアドマーケティング Advent Calendar 2023 24日目の記事です。
こんにちは、GMOアドマーケティングのM.Hです。今年ももう年の瀬を迎えようとしておりますが、思い返せば自然言語についても画像についても生成AIの進化や多様化の著しい2023年でしたね。来年も同じこと言ってそうですが…笑
この記事ではそんな話題の中から画像生成AIの、実は最近また勢いづいてきているStability AIのStable Diffusionについて、特にStable Diffusionの最新モデルであるSDXL1.0にまつわる内容を取り上げていきます。
注意:本記事で掲載している生成画像およびサムネイル画像は全て商用利用可能であるOpenAIのサービスであるDALL-E3およびStability AIの公式モデルを用いて作成したものです。いずれもコンテンツポリシーやライセンス文に基づき使用しています。また、極端に類似の画像や写真が存在していないことをあらかじめ確認しております。
1. 他画像生成サービスとStable Diffusion
2023年は、OpenAIのDALL-E3の発表やAdobeのFireflyなど非常に強力な画像生成AIが登場しました。これらのサービスはプロンプト入力が日本語にも対応していたり、サービス内で作成した画像が公式に商用利用可能だったり、対話形式やインタラクティブに画像を細かく修正可能だったりと高品質でクリーンな画像を生成・利用できるものです。
特に、プロンプトを自然言語の形で日本語で入力できることは利用のハードルを相当下げているかと思います。そう言った点ではStable Diffusionは導入の壁が高いと言えます。しかし、Stable Diffusionの強みはモデルが公開されておりコミュニティの盛り上がりが強いため、個人ユーザレベルでチューニングされた派生モデルが膨大に存在することかと思います。また、生成にあたって補助的な機能を提供する拡張機能も同じく膨大にあり、他の画像生成サービスとは比べ物にならないカスタマイズ性を持ちます。
またこの記事では触れませんが、2023年11月には画像からビデオで生成するStable Video Diffusionモデルや、画像生成に必要なステップを大幅に削減してリアルタイムレベルで生成を可能にするSDXL Turboモデルなど、次々と新しいモデルが発表されており、最近また勢いを増してきている印象です。
2. 各モデルバージョンの変遷とSDXL1.0モデルの特徴
Stable Diffusionは一般向けにモデルを提供したのは2022年7月ですが、コミュニティの盛り上がりによって派生モデルが多く公開されはじめたのは主にSD1.5というモデルバージョンあたりでした。以下に簡単な時系列を載せます。
2022年10月:[SDv1.5] 多くの派生モデルやControlNetモデルが作られ主流になる
2022年12月:[SDv2.1] 解像度と精度UP。v1.5と並んで派生モデルが多い
2023年 4月:[SDXL Beta] 解像度が1024×1024に。後のXLモデルの基礎
2023年 6月:[SDXL0.9] XLモデルとして実用性が高い精度に。いくらか派生モデルがある
2023年 7月:[SDXL1.0] 記事執筆時点で最新。より高精度になり派生モデルが次々出現中
この記事を執筆する時点ではSDXL1.0は最新のメジャーバージョンのモデルであり、これまでのモデルよりも高品質な画像を生成することが可能になり、特にコントラストやライティングを含んだ全体的な色調についての精度が強化されています。さらに、ネイティブ解像度は1024×1024であり、より繊細な画像を生成することができるようです。
SDXL1.0の大きな特徴としては、従来のモデルと同様に利用して画像を生成する「ベースモデル」と最終的なノイズ除去ステップに特化した「リファイナーモデル」の2つがあり、基本的にはこの2つを組み合わせて使います。
このような特徴があるSDXL1.0ですので、当然ではありますがこれまでのモデルと比べてモデルのサイズも大きくなりました。具体的にはSD1.5では1つのモデルが10億個近くのパラメータを持ちサイズがおおよそ2GB程度だったのに対し、SDXL1.0は35億個のパラメータを持つベースモデルと、66億個のパラメータを持つリファイナーモデルです。ベースモデルのサイズは約6.5GBとかなり増量していると思います。
3. モデルの精度比較
今回比較するために使用したものは「SD1.5」「SDXL1.0」「DALL-E3」としました。生成する画像のアイディアはChatGPTに考えてもらいました。また、Stable Diffusionに入力するプロンプトは、後述しますが拡張機能によってChatGPTと連携して生成しています。いずれの生成においても、後から修正をしていない初回生成分のみ掲示しています。
入力文としては全て以下の文章の通りとなります。
- 魔法の森の中にある古い城:古代の城が霧に包まれた魔法の森の中にあり、周囲は色とりどりの光る花や神秘的な生き物で溢れている
- 古代の戦士:古代の甲冑を身に着けた勇敢な戦士が、手にした剣を高く掲げている。背景は荒涼とした戦場
- 忍者の訓練:秘密の忍者の訓練場で、忍者が武器や身体能力を鍛えている様子。背景には日本の山々が見える
- 3D文字エフェクト:鮮やかな色と影を使って、「GMO AD Partners」の立体的に見えるようにデザインされる3Dの文字を描く
- 自然インスピレーションのロゴ:山、木、花、海などの自然要素を取り入れたロゴ
- 宇宙の冒険者:遠い宇宙の星々を背景した、宇宙飛行士のスーツのような装備を身につけた緑色の瞳を持つ日本のアニメキャラクター調の男の子
| 生成画像 | SD1.5 | SDXL1.0 | DALL-E3 |
|
1 |
 |
 |
 |
| 2 |  |
 |
 |
| 3 |  |
 |
 |
|
4 |
 |
 |
 |
|
5 |
 |
 |
 |
|
6 |
 |
 |
 |
いかがでしょうか?SD1.5と比べるとSDXL1.0は明らかに精度が向上しているかと思います。SD1.5は意図を汲み取ってくれないケースもありましたが、SDXL1.0とDALL-E3はある程度抽象的な指示であってもそれっぽい画像を作成してくれました。あとは個人の好みや生成したいシチュエーションの問題になってきそうです。
リアル調の画像はさすがにSDXL1.0, DALL-E3で実力拮抗という印象です。忍者の画像は日本要素が入っているからかSDXL1.0では若干コミック調で出力されましたが、「日本の山」という文言から富士山っぽいものを出力してくれています。
文字やロゴはDALL-E3の方が一枚上手の印象です。SDXL1.0は画像のクオリティは良くても痒いところに手が届かない感じでした。
アニメ調の画像はSDXL1.0の方がそれっぽいような?何回か試すと結果は変わってきそうです。
なんにせよ、SDXL1.0とDALL-E3では大きく精度に乖離があるようには思えませんでした。また、本記事で使用しているStable Diffusionのモデルは基盤となる公式のモデルですから、別途チューニングされた派生モデルを適宜導入して生成すればさらにクオリティは向上していくものと思われます。派生モデルについて本記事では詳しく触れませんが、CivitAIなどのポータルサイトから検索・ダウンロードすることができます。
4. 拡張機能ControlNet技術との連携
Stable Diffusionの強みとしてさまざまな拡張機能があることは先述のとおりですが、ここでいう拡張機能とはWebUIに導入するものを指します。Stable Diffusionを扱えるWebUIで有名なものはいくつかありますが、本記事ではトップシェアであるAUTOMATIC1111に適用できる拡張機能について取り上げます。
4.1 ControlNet
ControlNetは2022年に開発されたアーキテクチャです。特に画像生成においてはポージングや奥行き、輪郭などを抽出して、出力結果を操作することができます。下書きからイラスト生成したり画像のレタッチができるやつですね。
記事冒頭でも書きましたがSD1.5が最初に盛り上がったモデルでしたので、ControlNetもそれに合わせる形でSD1.5対応のモデルがあります。その後SDXL1.0モデルが発表され、最初こそは対応ControlNetモデルは乏しかったですが、今ではもうほとんどの主力手法には対応していると思います。Hugging Faceでモデルをまとめてくれているのでこちらもご参照ください。
試しにSDXL1.0対応のControlNetで画像を生成してみました。また、現在はGPT-4VによってChatGPTが画像入力に対応しており似たようなことができますので比較も行いました。
- 元画像をサイバーパンク調に変換する
- 元画像の女性について、都会の海で風に吹かれているような画像に直す
| 指示 | 元画像 | SDXL1.0 | DALL-E3 |
|
1 |
 |
 |
 |
| 2 |  |
 |
 |
(※)
1.の写真は筆者が個人的に撮影したものです。
2のポーズ画像は「無料の写真素材・AI画像素材「ぱくたそ」」サイトの画像を利用させていただきました。
こちらはGPT-4VとDALL-E3の組み合わせでも結構な精度でした。元画像の構図、色味を残しつつ新しく画像を作り出している印象を受けます。対してSDXL1.0では元画像の構図は完全に残す形で変換しています。今回使用したのがCannyやDepthでしたのでそのような結果になっているかと思いますが、これはStable DiffusionのControlNetの特徴と言えるかもしれません。
4.2 OpenAI APIとの連携
Stable Diffusionが初心者向けではないと言われる大きな理由の1つは、基本的にプロンプトを自然言語の形で与えられないこと、かつ英語オンリーであることかと思います。いわゆる「呪文」と呼ばれるやつです。しかし、どうしても自然言語で指示文を書いて手軽に画像を作りたい…拡張機能の中にはその需要を満たしてくれるものがいくつかあります。本記事で生成してきた画像もこれを利用しました。
以下にOpenAI APIとの連携ができる拡張機能3つをピックアップしました。これで設定すればchatGPTを利用する要領でプロンプトを生成できます。
- Physton / sd-webui-prompt-all-in-one
- hallatore / stable-diffusion-webui-chatgpt-utilities
- niki22mk2 / gpt-promptgen
どれも機能は同じなので好きなものを入れれば良いというわけではなく、GPTモデルに投げるプロンプトが異なるため同じ文章を与えても出力に結構な差があります。また、OpenAIのAPI Keyを登録する必要があり、利用は従量課金なのでその点注意してください。
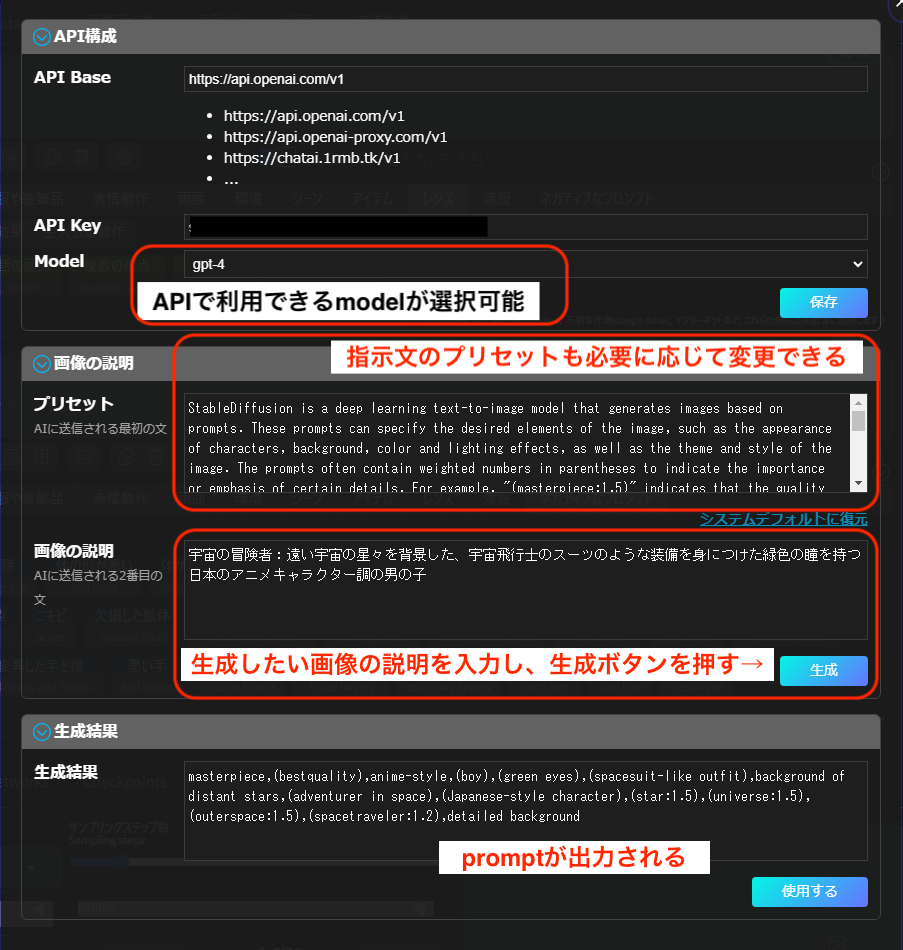
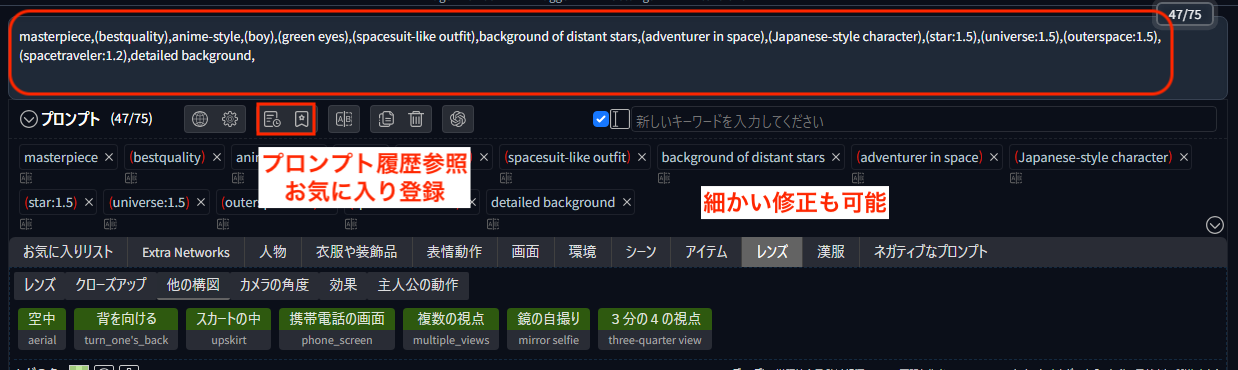
特に1.の「prompt all in one」は生成後のプロンプトの微調整や履歴の確認などもできて個人的におすすめです。文字通りプロンプトに関する補助機能が1つにまとまっています。次の画像のようにAPI Keyを保存し利用モデルを選択したらすぐ利用できます。画像の説明を入力して「生成」ボタンを押せばプロンプトが出力されるので、「使用する」ボタンを押してそのまま画像生成可能です。指示文のプリセットもデフォルトのものがありますが必要に応じてカスタマイズできます。画像の説明は日本語でも問題ありませんでした。
5. まとめ
総評としては、SDXL1.0とDALL-E3ともに非常に高い精度を出しており、いずれも実用に耐えうると思います。特にSDXL1.0はこれをベースとした多様なチューニングモデルが次々と登場し、拡張機能も膨大にあることはかなりの強みになるかと思います。また本記事では触れませんでしたが、AdobeのFireflyも非常に強力なツールです。
どのモデルが最も優れているかを一概に決めるのではなく、状況に応じて異なるモデルを使い分けることが重要だと考えられます。
以上Stable Diffusionの最新モデルであるSDXL1.0を中心にして実際に生成した結果を交えて説明してきましたが、いかがでしょうか?この記事が誰かの参考になれば幸いです。
明日は星野さんによる「次世代WebカンファレンスのPrivacyセッションに登壇した話」です。
引き続き、GMOアドマーケティング Advent Calendar 2023 をお楽しみください!
■採用ページはこちら!
https://recruit.gmo-ap.jp/
■GMOアドパートナーズ 公式noteはこちら!
https://note.gmo-ap.jp/


