
こんにちは、GMOアドマーケティングのS.Rです。
TPUとはディープラーニングを高速化するために、Googleが開発したプロセッサーです。TPUの利用により、ディープラーニングのモデルのトレーニング時間を20倍以上改良する事が可能です。
TensorFlow 1.xでTPUを利用するAPIを提供していますが、TensorFlow 2.0ではこのAPIの利用方法が変更されました。
今回はTensorFlow 2.0でTPUを利用する方法を皆さんへご紹介します。
利用する環境
Googleが無料で提供している機械学習目的の研究用ツール【Colab】を利用します。
1 Colabのインスタンスを作る
Colabを利用するために必要な最初のStepは、Colabのファイルを作る事です。
Google Driveの管理画面へ遷移し、新しいColabのファイルを作ります。
2 TPUを設定する
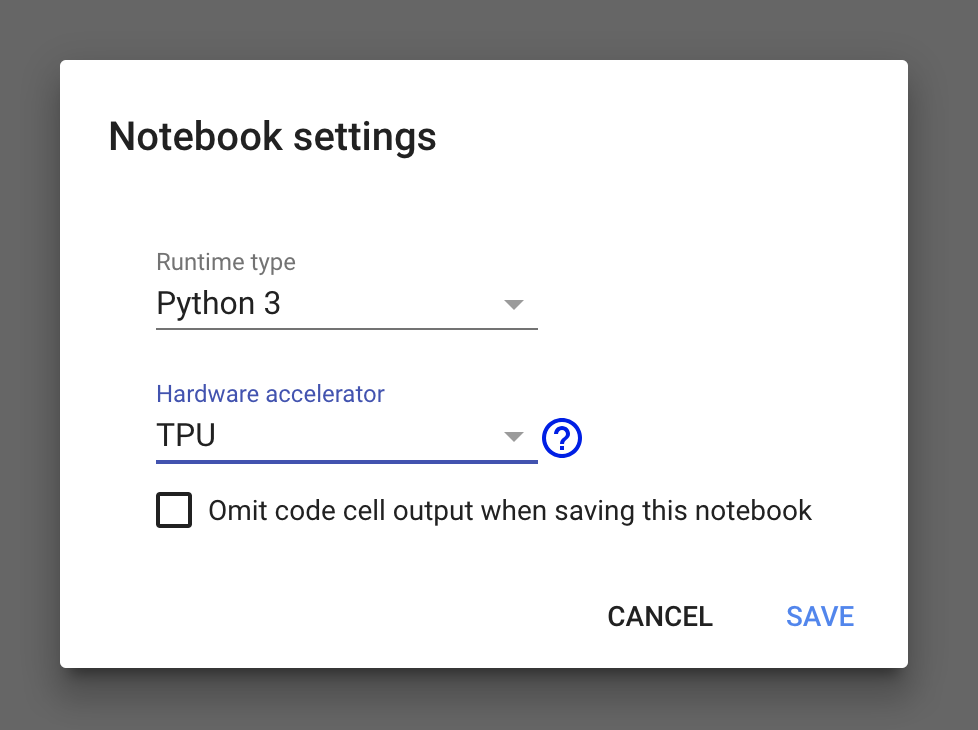
作成されたファイルのメニューにあるRuntimeをクリックし、ポップアップメニューからchange runtime typeを選択します。
【Notebook settings】画面で、【Hardware accelerator】を “TPU” に設定します。
TPUの実行例
今回もまた手書き数字を認識するデータセット、Ministを例として説明します。
1TensorFlow 2.0 を有効にする。
|
1 2 3 4 5 6 |
from __future__ import absolute_import, division, print_function, unicode_literals try: %tensorflow_version 2.x except Exception: pass import tensorflow as tf |
2 TPUと連携して初期化する。
|
1 2 3 4 5 6 |
import os import tensorflow_datasets as tfds resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR']) tf.config.experimental_connect_to_cluster(resolver) tf.tpu.experimental.initialize_tpu_system(resolver) |
3 MINISTデータセットをロードする。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
def get_dataset(batch_size=200): datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True, try_gcs=True) mnist_train, mnist_test = datasets['train'], datasets['test'] def scale(image, label): image = tf.cast(image, tf.float32) image /= 255.0 return image, label train_dataset = mnist_train.map(scale).shuffle(10000).batch(batch_size) test_dataset = mnist_test.map(scale).batch(batch_size) return train_dataset, test_dataset train_dataset, test_dataset = get_dataset() |
4 学習モデルを作成する。
今回は1層 CNNを利用します。
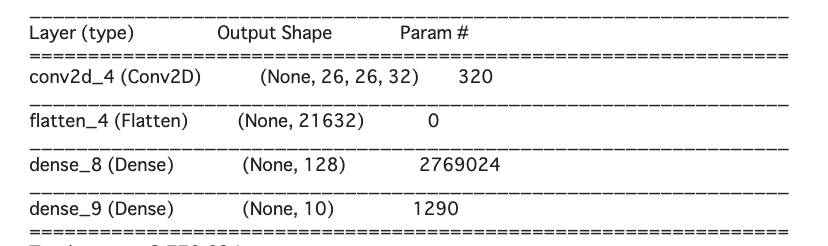
コードは下記です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def create_model(): return tf.keras.Sequential( [tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10)]) with strategy.scope(): model = create_model() model.summary() model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['sparse_categorical_accuracy']) |
5 モデルを学習する。
|
1 2 3 4 5 6 7 8 9 10 |
import time ts = [] ts.append(time.time()) model.fit(train_dataset, epochs=5, validation_data=test_dataset) ts.append(time.time()) print('Fitting time: %.1f (sec)' % (ts[-1] - ts[-2])) res = model.evaluate(x_test, y_test, verbose=2) print('model accuracy %s \n' % res[1]) |
学習の結果は下記です。

まとめ
今回はTensorFlow 2.0でTPUのAPIモデルをトレーニングするための一例をご紹介しました。いかがでしたでしょうか。
高い計算力を使うと、モデルの精度、作成速度が改善できます。
今回のブログが、皆さんのディープラーニング モデルの実装にお役に立てば幸いです。



