
こんにちは。
GMOアドマーケティングのM.Nです。
TAXELのインフラは、今年2月に一部機能をGMOアプリクラウド内移行(バージョンアップ)し、残りをGCPに移行しました。
今回はその際に起きたトラブルの事例を紹介しようと思います。
1. 時折発生するアラート
移行が無事に終わり、2ヶ月ほど経った頃、一通のalertが飛んできました。
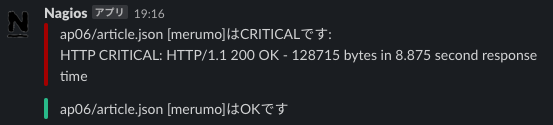
article.jsonはレコメンドウィジェットのリクエストですが、レスポンスに9秒弱かかっているようです。
直後に復帰しているのでウィジェットが全く配信できていない、という状態にはなっていないようですが・・・気になります。
また、どこかのAPサーバーだけで発生しているというわけでもなさそうです。
最初は一時的なものかと思って様子を見ていましたが、日増しに頻度が増え一日数回飛んでくるようになりました。
軽く調査したところ、alertは特定の時間帯に偏っているわけではないこと。また、特定のメディアのみで発生しているものではなさそう、ということは分かりました。
しかしこの時点ではまだハッキリとした原因が掴めていません。
2. APサーバーの負荷が増加
そうこうしているうちにAPサーバーのLoad Averageがあがっているというalertが出てきました。
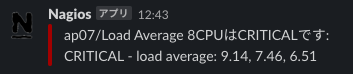
ここで本腰を入れて調査することに。
3. サーバーリソースの調査
まずはGrafanaを使って現状を確認していきます。
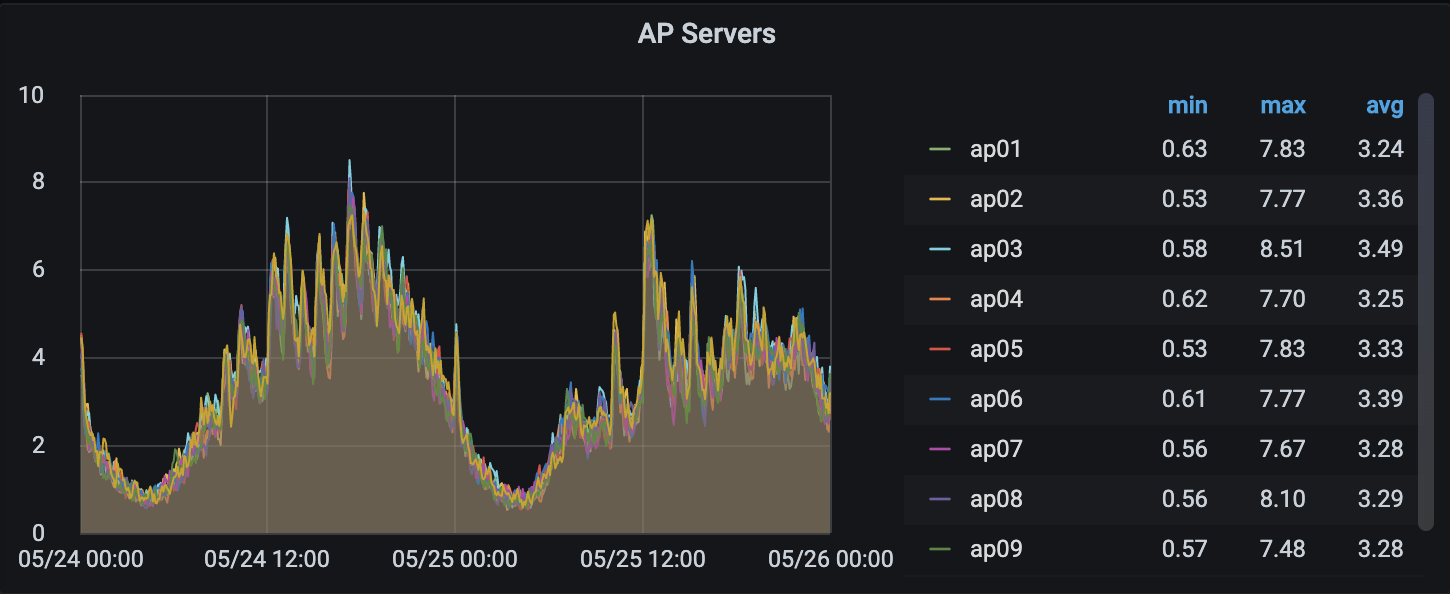
APサーバーのLoadAverageの推移です。
CPUが8コアなので、5/24 18:00頃などは危険な状態です。
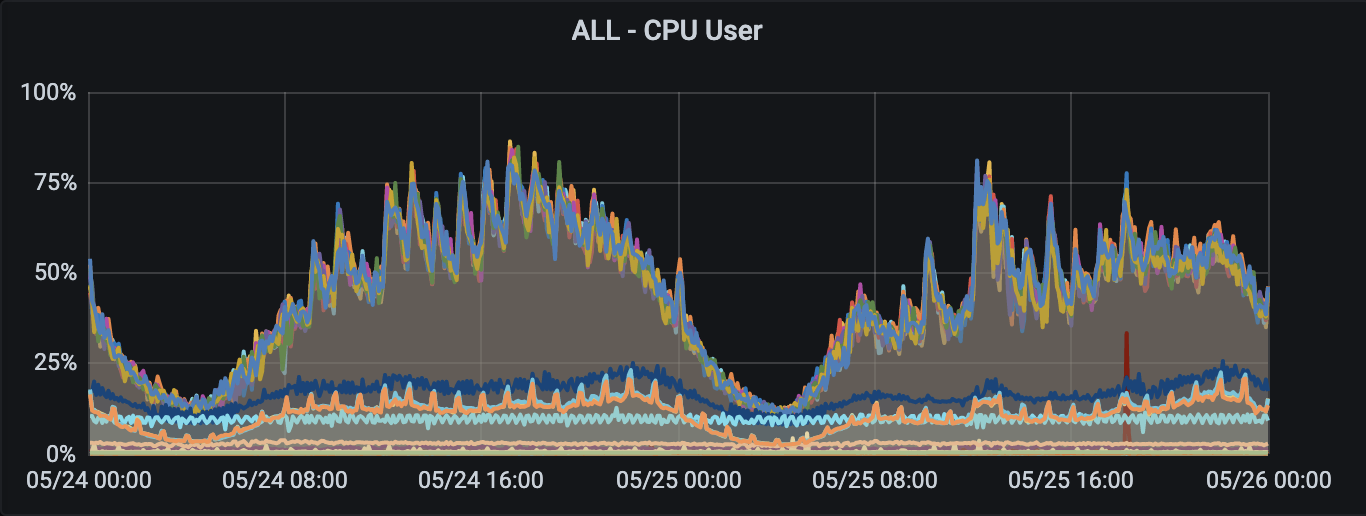
つづいてCPU使用率です。
APサーバーのCPU使用率がピーク時に80%を超えています。
もっと長期でみると、全体的に徐々に増加傾向で明らかに怪しいです。。。
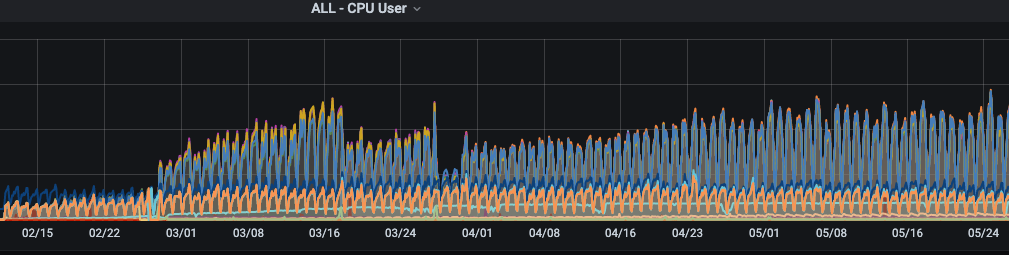
急場を凌ぐためAPサーバーを数台追加してみましたが、改善は見られませんでした。
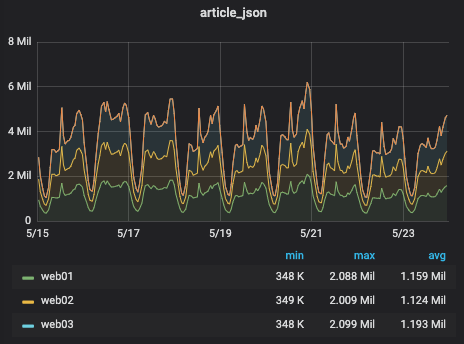
article.jsonのリクエスト数です
リクエスト数はそれほど変化はなさそうです。むしろ5/22付近は比較的少ない部類に入ります。
なので単なるリクエスト数の増加が原因、というわけではなさそうです。
プログラムの修正やインフラ周りの変更は特に思い当たる節がなかったため、この時点でHBase周りが原因の可能性が高そうだと考えました。
4. HBaseの利用調査
TAXELのAPサーバーからのHBaseへのアクセスは基本的にRowKeyに対してPrefixFilterを指定してScanすることがほとんどです。
そしてこのときデータによって特定のRegionにアクセスが集中する現象が発生しやすいため、TableによってはRowKeyが分散するように設計しています。
例えば、レコメンド記事の在庫などはメディアの規模によってレコード数が数百〜数千万とバラツキが大きく
RowKey = [メディアID][記事ID(hash化された文字列)] という構成にした場合はパフォーマンスが低下します。
この場合、 RowKey = [記事ID][メディアID]のようにすることでデータの偏りを回避できます。
これは悪い例
> scan ‘recommended_article’, ROWPREFIXFILTER => ‘1_’
1_aaaaa
1_bbbbb
10 row(s)
> scan ‘recommended_article’, ROWPREFIXFILTER => ‘2_’
2_aaaaa
2_bbbbb
2_ccccc
2_ddddd
2_eeeee
2_fffff
10,000,000 row(s)
これはよい例
> scan ‘recommended_article’, ROWPREFIXFILTER => ‘a’
aaaaa_1
aaaab_1
aaaac_1
aaaaa_2
aaaab_2
aaaac_2
10,000 row(s)
> scan ‘recommended_article’, ROWPREFIXFILTER => ‘b’
bbbbb_1
bbbbc_1
bbbbd_1
bbbbb_2
bbbbc_2
bbbbd_2
10,000 row(s)
今回も一部のRowKeyのデータが増大したことによりレスポンスの低下が発生しているのではないかと考えました。
続いて、実際どのくらいのリクエストがあるか、ambariのRequest metricsを見て確認します。
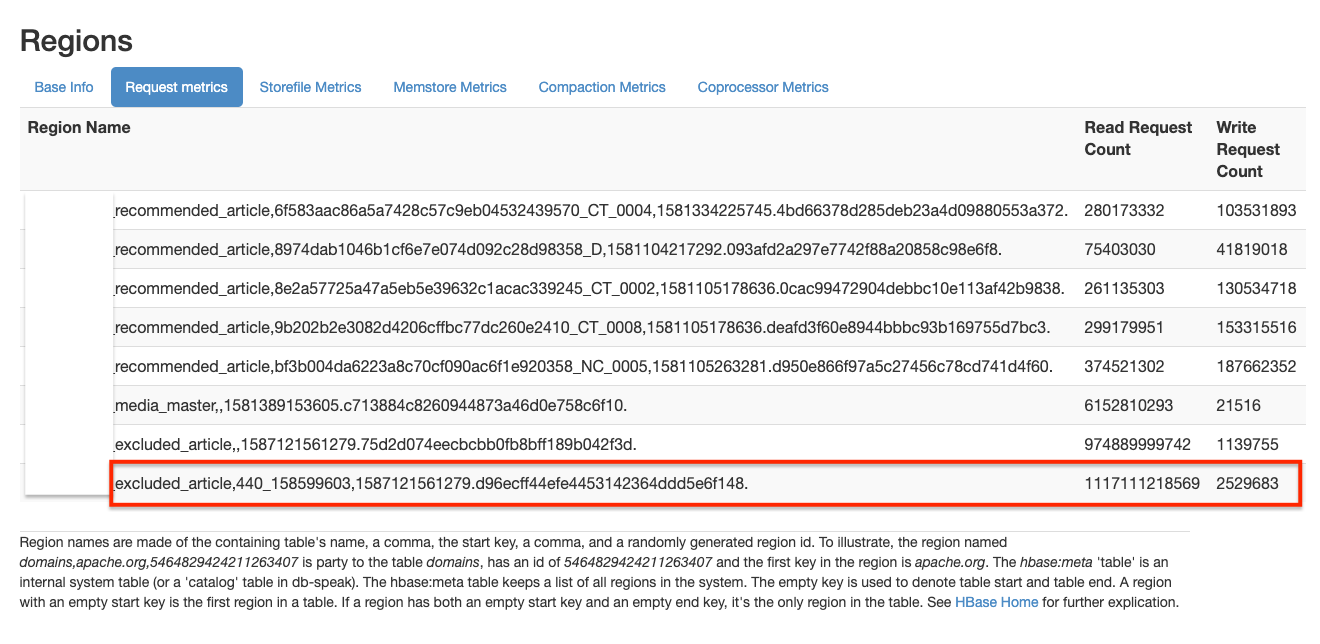
すると、赤枠で囲ったexcluded_articleのRead Request Countが1番多く、またRowKeyが “440_xxxxxx” となっており、前述した条件を満たすようなデータになっています。
これは怪しそうです。
5. 実データをみてみる
本番HBaseに接続してデータを確認してみます。
すると以下のようなデータが取得できました。(一部加工しています)
> scan ‘excluded_article’, ROWPREFIXFILTER => ‘440_’
440_1592716400_xxxxxx column=deleted_article:v, timestamp=1592716400438, value={“deletedAt”:1592716400,”articleId”:”xxxxxx”,”mediaId”:”440″,”url”:”https://hoge.com/fuga”}
1,000,000 row(s) in 9.1630 seconds
通常の運用方法では、この条件でscanしたら数万行程度に収まる想定なのですが、100万行ありました。
これは明らかに怪しいです。
よくよく調べてみると、timestampが古いデータが残っているようでした。
excluded_articleのテーブル定義を見てみます。
> describe ‘excluded_article’
Table excluded_article is ENABLED
excluded_article
COLUMN FAMILIES DESCRIPTION
{NAME => ‘deleted_article’, BLOOMFILTER => ‘ROW’, VERSIONS => ‘1’, IN_MEMORY => ‘false’, KEEP_DELETED_CELLS => ‘FALSE’, DATA_BLOCK_ENCODING => ‘NONE’, COMPRESSION => ‘NONE’, MIN_VERSIONS => ‘0’, BLOCKCACHE => ‘true’, BLOCKSIZE => ‘65536’, REPLICATION_SCOPE => ‘0’}
1 row(s) in 0.0950 seconds
推測ですが、どうやら
– 運用初期はTTLが設定されていなかった
– 運用中にデータが増えたので当該テーブルに対してTTLを設定した
– 移行時にテーブルを作り直したため消えてしまった
というのが原因のようです。
古いデータを削除すれば一時的に凌げますが、ここはちゃんとTTLを設定し直すことにしましょう。
6. 復旧
excluded_articleテーブルにTTLを設定したいので、テーブルを再作成します。
幸い今回のデータは消失してもそれほど困らないデータであったため、一時的に配信側から参照しないようにコードを修正した上でテーブルの削除→作成を行いました。
削除する前に無効にしておかないとエラーで実行できないので注意です。
> disable ‘excluded_article’
0 row(s) in 2.3430 seconds> drop ‘excluded_article’
0 row(s) in 1.3100 seconds> create ‘excluded_article’,
> {NAME => ‘deleted_article’, DATA_BLOCK_ENCODING => ‘NONE’, BLOOMFILTER => ‘ROW’, VERSIONS => 1, TTL => 345600, BLOCKCACHE => true}
0 row(s) in 2.2900 seconds> describe ‘excluded_article’
Table excluded_article is ENABLED
excluded_article
COLUMN FAMILIES DESCRIPTION
{NAME => ‘deleted_article’, BLOOMFILTER => ‘ROW’, VERSIONS => ‘1’, IN_MEMORY => ‘false’, KEEP_DELETED_CELLS => ‘FALSE’, DATA_BLOCK_ENCODING => ‘NONE’, TTL => ‘345600 SECONDS (4 DAYS)
‘, COMPRESSION => ‘NONE’, MIN_VERSIONS => ‘0’, BLOCKCACHE => ‘true’, BLOCKSIZE => ‘65536’, REPLICATION_SCOPE => ‘0’}
1 row(s) in 0.1240 seconds
TTLを4日に設定したので、これでデータが増え続けることは回避できるはずです。
対応後の状態をGrafanaで確認してみると、改善されていることが確認できました。

また、テーブル定義書もTTLを設定するように修正しておきました。
これで再度移行することになっても安心です。
7. さいごに
今回HBaseにまつわるトラブルの事例を紹介しました。
定期的な監視や日々の運用の知見を活かし、大規模な障害に発展する前に対応することができてよかったです。


