

きっかけ
SLI/SLO文化を導入しようと思ったきっかけは、「プロダクトをより成長させていきたい」という思いが自身としてもインフラチームとしてもあったからです。加えて、SLI/SLOの設計と運用の導入について、私自身がもともと興味を持っていて、弊社のプロダクトに導入したらどういうことが起きるのかを自分の目で見てみたいと思っていたこともあり、インフラチームとして各プロダクトにSLI/SLO文化を推進してみることになりました。
導入するプロダクトについて
今回は私自身もGCP移行で関わりがあったGMOSSPへ、導入してみることにしました。
GMOSSPについての自身のプロダクト理解度としては、導入前の時点で約30%ほどでインフラ側の構成を理解できている程度でした。今回SLI/SLOを設計していく上で必要になるプロダクトの機能の詳細やユーザの使用目的については、導入前はあまり理解できていない状態でした。
進め方
GMOSSPを開発しているエンジニアメンバー(以下開発メンバー)にて最終的に運用できるようになることを目指して最初は私が設計を行い、その後開発メンバーへ引き継いでいく方針で進めていきました。実際の設計から導入までの具体的な進め方は以下になります。
- 導入するプロダクトの理解・CUJの洗い出し
- CUJに対するSLIの定義
- 各SLIに対するSLOの設定
- アラート設計と設定
- 運用設計・実践
導入するプロダクトの理解・CUJの洗い出し
まずは、SLI/SLOを導入するプロダクトについて理解を深めることから始めました。プロダクトの概要や特徴、ユーザやその他プロダクトを活用していくステークホルダ、接続サービスや主要コンポーネントなどを開発メンバーにヒアリングを行いながら、自分で大まかなシステム概要図を作成しました。ここで意識したのは、この後の設計フェーズでSLIの指標を定義しやすいよう、システムへのリクエストからレスポンスまでの経路を大まかに理解することでした。そこからCUJ(クリティカルユーザジャーニー)と思われるものを洗い出し、最終的に開発メンバーにコメントをもらいつつ認識を合わせていきました。
CUJに対するSLIの定義
洗い出したCUJに対して、実際のアプリケーション内部の処理をコードベースで追っていきながらSLIとして利用できそうな指標を洗い出していきました。そしてGoogleのCREエンジニアによって開発されたThe Art of SLOsというワークショップ内で使用されている資料中の「SLIメニュー」を参考にしながら、各CUJに対するSLIを定義しました。
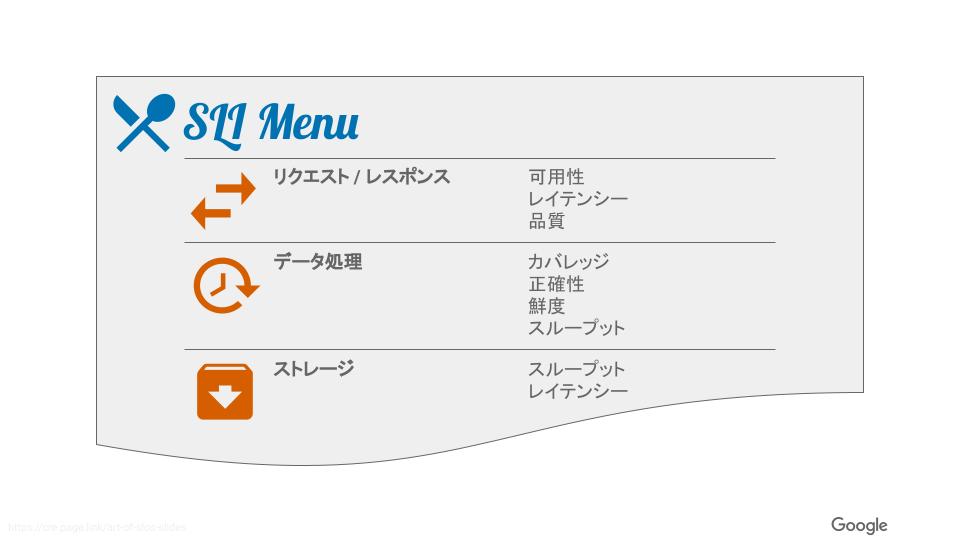
参考:
The Art of SLOs
[PUBLIC] The Art of SLOs – Slides – JA
SLIは可能な限りユーザ体験に近い部分の指標を測定することが好ましいとされているのですが、導入するプロダクトは負荷の低い深夜帯でも秒間約3500ほどのリクエストがあるため、ロードバランサでの指標はコスト面を考慮して有効にしておらず、後続のサーバのメトリクスやログなどから測定しています。
各SLIに対するSLOの設定
まずは定義したSLIに対してそれぞれ、有効なイベントとその中の良いイベントを定義するところから始めました。そして、現状の有効なイベント中の良いイベントの割合を確認し、その割合よりも少し緩めの値を開発メンバーとすり合わせを行い、SLOとして設定しました。ここでは、ユーザがそのレベルの信頼性に頼ってしまうことになってしまうためSLOはあえて厳しく設定せず、あくまでもギリギリ達成できればサービスの典型的なお客様が満足するようなレベルのSLOに設定することが大切です。最初は緩めに設定して運用し、運用していく中で少しずつ厳しくしていくことが良いと思いこのように設定しました。
アラート設計と設定
アラートについては、Google Cloud MonitoringのSLOモニタリング機能を使って設定しました。
SLOをモニタリングしアラート通知する方法としては、Googleにて出版されている書籍「The Site Reliability Workbook」では以下2つが紹介されています。
- ウィンドウ時間のうちリクエストに対するエラー率についてモニタリングする方法
- 精度を高めるためにはチューニングが難しい
- ウィンドウ時間を短く設定するとアラートが頻発しノイズになる可能性
- ウィンドウ時間を長く設定するとアラートがトリガーされにくくなる可能性(アラートリセットまでの時間が長くなるため)
- 精度を高めるためにはチューニングが難しい
- ウィンドウ時間のうちバーンレートについてモニタリングする方法
- アラートの精度が良い(エラーバジェットの消費速度がモニタリング対象となるため)
- 以下2種類のアラートを設定すると良い
- 急速バーンアラート:エラーバジェットが急激に減少しているときにアラート
- 低速バーンアラート:SLO期間の終了前にエラーバジェットが枯渇する可能性のある消費速度で減少しているときにアラート
- サービス影響はないけどエラーが一定でていた時のような「気づかないうちにエラーバジェットを消費してしまっていた」という状況を防ぐために有効なアラート
参考:The Site Reliability Workbook – Alerting on SLOs
上記より、アラートの確認にかかる工数をできるだけ少なくしたいため、今回は急速バーンアラートと低速バーンアラートを設定しました。
Cloud Monitoringでバーンレートアラートを設定する時には select_slo_burn_rate というセレクタを使用するとGCPで自動で「現在の失敗率/SLO期間中の理想的な失敗率」すなわち時系列データの集計期間の「バーンレート値」を算出してくれるので便利です。
また、データの集計期間と紛らわしいですが、ルックバック期間については閾値に対してSLO値を評価する期間のことで、急速バーンアラートは短く設定し低速バーンアラートは長く設定します。
このように、GMOSSPのバーンレートアラートについては、バーンレートが残りのエラーバジェットの80%を消費する速度になっている時にアラートを通知するようなバーンレート閾値を設定しました。
今回は初めて導入するということもあり大まかな値を設定しましたが、運用開始して微調整していくのが良いと思います。
運用設計・実践
このフェーズでは、設定したSLOモニタリングとアラートをどう活用・運用していくのかについて、まず最初に私の方で設計し、開発メンバーとも認識を合わせた結果、以下のように運用していくことになりました。
- 残エラーバジェットの定期的な確認:毎日の朝会にて実施
- 残りのエラーバジェットを確認し、リスクが高いリリースについては相談する
- SLI/SLO指標・運用についての定期的振り返り:スプリントレビューにて実施
- 指標の追加や変更の必要があるかどうか確認
- エラーバジェットポリシーについて変更する必要があるかどうか確認
- その他SLI/SLOの運用についての相談
上記のイベントには、私自身も最初はサポートとして何回か参加しましたが、基本的には開発メンバー主体でやってもらいました。最初はどこに着目すべきかやどう進めていくかを適宜フィードバックしたりしましたが、回を重ねていくとともに開発メンバーもSLI/SLOについて理解を深め、自主的に改善のための議論と対応ができるようになっていきました。
導入前と導入後で変わったこと
2023年9月ごろより運用を開始し2023年11月現時点では、SLOモニタリング導入の最終目的であった「サービスを利用する顧客・ユーザからの信頼性を維持する」ことについては、まだ正直実感はできておりません。というのも、これから先運用していくにつれて少しずつ実感していくことだと思っているからです。
ですが、その最終目的の前段階である「ユーザから見たサービスの信頼性の可視化」については、SLOモニタリングを設定し導入し始めたことで可視化することができました。設定したSLOモニタリングを使って、まずはエラーバジェットの残りを見つつリリースを計画するというような一定の信頼性を継続することから取り組んでいき、その上で信頼性の向上(SLOを厳しくしていくこと)を目指していければと思います。
そして、開発メンバーのSLI/SLOの理解度についてもアンケートに回答いただき、ほとんどのメンバーが「用語の意味や概要を知っていた」という導入前の状態と比べ、導入後には「SLOモニタリング運用の目的を理解した上で運用できている状態」、さらには「他の人に説明できる状態」まで向上させることができました。
加えて私自身についても、SLI/SLOの設計の知識はもちろんですが、SLI/SLOを導入するというインフラチームの施策を無事にやりとげることができ、経験にもなりました。
全体としてよかったこと・苦労したこと
全体を通してよかったこととしては、前述した通りサービスの信頼性を可視化できたことです。サービスの今後の成長には、ユーザからの信頼の獲得とその維持が大切であり、かつ信頼性を損なわない範囲での新機能のリリースなどの挑戦する姿勢も必要だということを実感しました。
また苦労したこととしては、社内で初の施策を実施するということもあり、個人的にはSLI/SLOを理解するまでに時間がかかったことです。特にアラートの設計は少し複雑に感じたので、何回もドキュメントを読み込み直しつつ取り組んでいました。
また、普段プロダクトに深く関わってはいないこともあり、プロダクトに関する理解についても時間がかかりました。このことに関しては、開発メンバーとペアプロのように密になって設計していくことができれば、導入までの難易度は下がる気がします。
おわりに
簡単ではありますが、今回はSLOモニタリングを導入し感じたことを紹介しました。
今回導入したSLOモニタリングが、「SLOモニタリングがあったからこそ、プロダクトが成長できた!」といつか言われるようになったらいいなと思います。
導入していく中でまた何か進展がありましたら、次回以降に執筆したいと思います。
最後に、弊社アドマーケティングでは、今年もQiita アドベントカレンダーに参加いたします!
こちらで随時公開される記事も、どうぞご期待ください。そしてぜひチェックをお願いいたします!
GMOアドマーケティングのインフラエンジニア。(♀)
クラウドインフラのアーキテクチャ設計が得意です。
アプリ開発もできます。
白米と服とおいしいものとFPSと技術が好きです。


