
こんにちは、GMOアドマーケティングのS.Rです。
日本語のNLP(自然言語処理)で形態素解析は大切な処理の1つとなります。
今回は、形態素解析ツール「MeCab」へWikipediaの辞書を追加する方法を紹介します。1. 日本語の形態素解析ツールMeCab
MeCabは日本語の形態素解析ツールです。詳細はWikipediaの説明をご覧ください。
MeCabはオープンソースの形態素解析エンジンで、奈良先端科学技術大学院大学出身、現GoogleソフトウェアエンジニアでGoogle 日本語入力開発者の一人である工藤拓によって開発されている。名称は開発者の好物「和布蕪(めかぶ)」から取られた。
MaCab、2019年09月17日、ウィキペディア日本語版、https://ja.wikipedia.org/wiki/MeCab
2. 「MeCab」へWikipediaの辞書を追加する方法の説明

1) Mecabをインストールする:
|
1 2 3 4 5 |
sudo apt-get install build-essential sudo apt-get -y install mecab libmecab-dev mecab-ipadic mecab-ipadic-utf8 git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git sudo apt install file yes yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n -a |
2) Mysqlをインストールする:
下記のコメントでMysqlをインストールします。
|
1 2 |
sudo apt-get -y update sudo apt -y install mariadb-server |
3) Mysqlのデータベースを作る:
|
1 |
sudo mysql -uroot -e "create database jawikipedia" |
4) Wgetをインストールする:
|
1 |
sudo apt-get -y install wget |
5) Wikipediaから辞書のローデータをダウンロードする:
※引用元|Wikipediaデータ MySQLを経由してBigQueryにLoadする|GMOアドマーケティング Advent Calendar 201911日目|https://qiita.com/fiemon/items/a3b2fda47b7dfef9cc6a
6) Mysqlへローデータを読み込む
※引用元|Wikipediaデータ MySQLを経由してBigQueryにLoadする|GMOアドマーケティング Advent Calendar 201911日目|https://qiita.com/fiemon/items/a3b2fda47b7dfef9cc6a
7) 辞書データのCSVファイルを作成:
※引用元|Wikipediaデータ MySQLを経由してBigQueryにLoadする|GMOアドマーケティング Advent Calendar 201911日目|https://qiita.com/fiemon/items/a3b2fda47b7dfef9cc6a
8) PythonでCSVファイルをmecab-ipadic-neologdのフォーマットへ変換する
下記のpythonのcodeを~/parse.pyで保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# encoding: utf-8 import codecs import os def isValid(word): try: if len(word) == 1 or u'_' in word: return False return True except: return False def parse(infile,output_file): fout = codecs.open(output_file , "a+", "utf-8") fin = codecs.open(infile, "r", "utf-8") dup_map = {} for line in fin: word = line.rstrip().split(",")[0] if "page" in word: continue if isValid(word) and word not in dup_map: dup_map[word] = True cost = int(max(-36000, -400 * len(word)**1.5)) fout.write(u"%s,-1,-1,%d,名詞,一般,*,*,*,*,*,*,wikipedia\n" %(word, cost)) fin.close() fout.close() os.system("rm -f /tmp/wikiword.csv") parse("/tmp/jawiki_page.csv", "/tmp/wikiword.csv") |
9) Mecabの辞書を作成
|
1 2 |
python parse.py /usr/lib/mecab/mecab-dict-index -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd -u ~/user_dic.dic -f utf-8 -t utf-8 /tmp/wikiword.csv |
10) Mecabへユーザー辞書を追加する:
|
1 |
sudo bash -c 'echo "userdic = /tmp/user_dic.dic" >> /etc/mecabrc' |
11) 解析結果を試す:
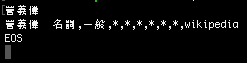
まとめ
今回はMeCabへWikipedia辞書を追加する方法を紹介しました。Wikipedia辞書の追加によってMecabは最新のネット用語、固有表現の単語を認識できるようになります。Wikipedia辞書を活用して形態素解析の精度を大幅に改良できると思います。
今回のブログが皆さんの日本語のNLPの開発にお役に立てば幸いです。



