
こんにちは、GMOアドマーケティングのS.Rです。
新型コロナウイルスが全世界で流行っています。全世界の感染者数のデータが国から公開され、毎日更新されています。
今日はGoogleに提供されている無料のデータ分析クラウドサービスcolabで全世界の感染者数のデータをダウンロードして簡単に分析する方法を皆さんへ紹介します。
1 最新の感染者数のデータをダウンロードする。
|
1 |
!wget https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/owid-covid-data.csv |
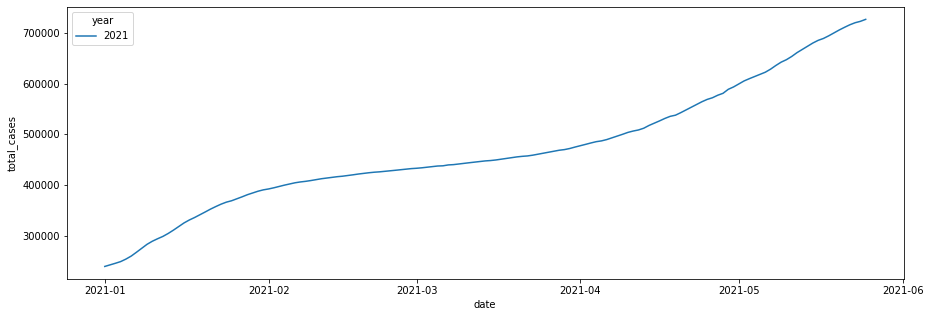
2 2021年の日本の感染者数 X 日付の図を作成する。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd from datetime import datetime all_df = pd.read_csv('owid-covid-data.csv', index_col=0, header=0) all_df['date'] = pd.to_datetime(all_df['date'], format='%Y-%m-%d') jp_df = all_df[(all_df["location"] == "Japan")] jp_df['year'] = jp_df['date'].dt.to_period('Y') jp_df = jp_df[jp_df['year'] == "2021"] fig, ax = plt.subplots(figsize=(15,5)) sns.lineplot(data=jp_df, x="date", y="total_cases",hue="year", ax=ax) |
コードを実行した結果は下記になります。
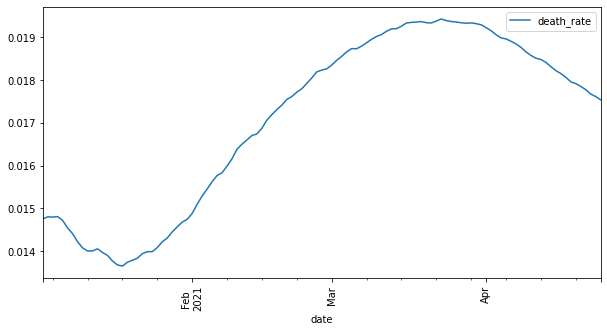
3 2021年の日本の新型コロナウイルスの死亡率 X 日付の図を作成する。
|
1 2 3 4 5 6 7 8 9 |
jp_df = all_df[all_df["location"] == "Japan"][["new_deaths", "date"]] start = datetime.strptime("2021-01-01", "%Y-%m-%d") all_df["date"] = pd.to_datetime(all_df["date"], format="%Y-%m-%d") all_df["death_rate"] = all_df["total_deaths"] / all_df["total_cases"] jp_df = all_df[(all_df["location"] == "Japan") & (all_df["date"] > start)][["death_rate", "date"]] fig, ax = plt.subplots(figsize=(10,5)) jp_df = jp_df.set_index("date") jp_df.plot.line(ax=ax) plt.xticks(label=jp_df.index, rotation='vertical') |
コードを実行した結果は下記になります。
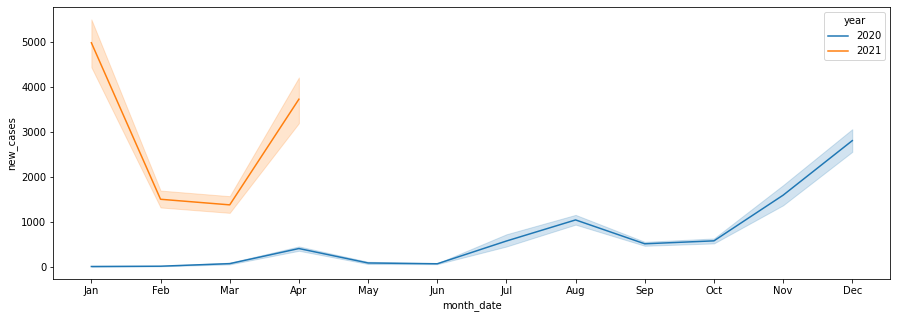
4 日本の月毎の平均感染者数の2021年と2020年のデータを比較する 。
|
1 2 3 4 5 6 7 8 9 10 11 |
import matplotlib.pyplot as plt import seaborn as sns from datetime import datetime all_df = pd.read_csv('owid-covid-data.csv', index_col=0, header=0) all_df['date'] = pd.to_datetime(all_df['date'], format='%Y-%m-%d') jp_df = all_df[(all_df["location"] == "Japan")] jp_df['month_date'] = jp_df['date'].dt.strftime('%b') jp_df["dayofyear"] = jp_df['date'].dt.dayofyear jp_df['year'] = jp_df['date'].dt.to_period('Y') fig, ax = plt.subplots(figsize=(15,5)) sns.lineplot(data=jp_df, x="month_date", y="new_cases",hue="year", ax=ax) |
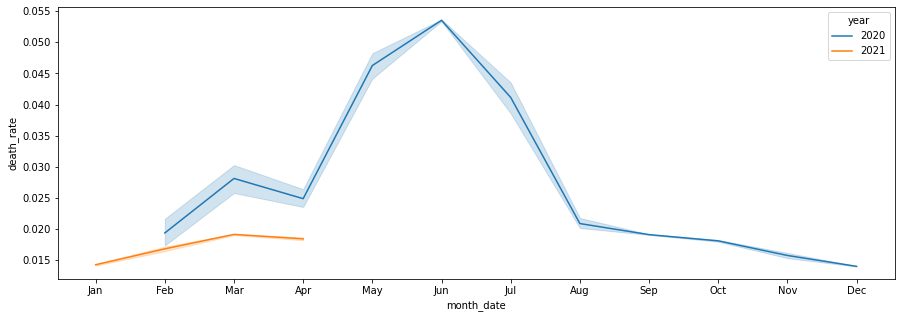
5 日本の月毎の平均死亡率の2021年と2020年のデータを比較する 。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import matplotlib.pyplot as plt import seaborn as sns from datetime import datetime all_df = pd.read_csv('owid-covid-data.csv', index_col=0, header=0) all_df['date'] = pd.to_datetime(all_df['date'], format='%Y-%m-%d') all_df["death_rate"] = all_df["total_deaths"] / all_df["total_cases"] jp_df = all_df[(all_df["location"] == "Japan")] jp_df['month_date'] = jp_df['date'].dt.strftime('%b') jp_df["dayofyear"] = jp_df['date'].dt.dayofyear jp_df['year'] = jp_df['date'].dt.to_period('Y') fig, ax = plt.subplots(figsize=(15,5)) sns.lineplot(data=jp_df, x="month_date", y="death_rate",hue="year", ax=ax) |
6 日本の死亡率と世界の平均死亡率を比較する 。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import matplotlib.pyplot as plt import seaborn as sns from datetime import datetime all_df = pd.read_csv('owid-covid-data.csv', index_col=0, header=0) world = all_df.groupby("date").sum().reset_index() world["location"] = "world" all_df = all_df.append(world) all_df["death_rate"] = all_df["total_deaths"] / all_df["total_cases"] all_df['date'] = pd.to_datetime(all_df['date'], format='%Y-%m-%d') jp_df = all_df[(all_df["location"] == "Japan") | (all_df["location"] == "world")] jp_df['year'] = jp_df['date'].dt.to_period('Y') jp_df = jp_df[jp_df['year'] == "2021"] fig, ax = plt.subplots(figsize=(15,5)) sns.lineplot(data=jp_df, x="date", y="death_rate",hue="location", ax=ax) |
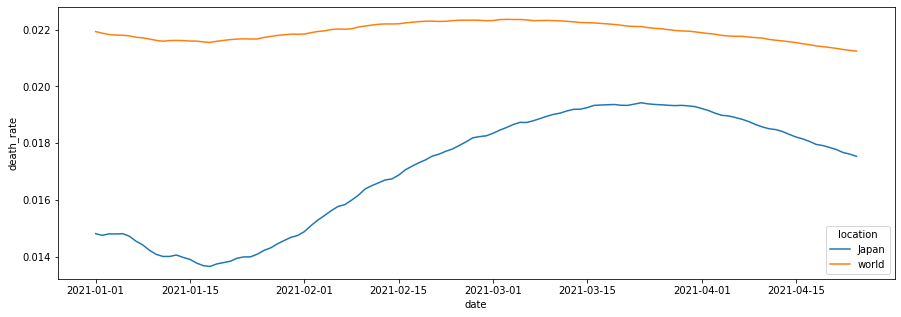
新型コロナウイルスに日本の平均死亡率は世界の平均より低いですね。
7 まとめ
今回はColabで日本の新型コロナウイルスの感染者状況を分析する方法を皆さんへ紹介してみました。いかがでしたでしょうか。もし興味があれば是非試してください。
新型コロナウイルス感染症の1日も早い収束を心よりお祈り申し上げます。



