
前回は機械学習開発の標準戦略MLOpsを皆さんへ紹介しました。
今日はKubeflowを実践する為にGoogle Cloud のMLOps サービスAI platform pipelines で 簡単に手書き数字の分類システム(MNIST)を開発する例を紹介させていただきます。
※なお、この記事中の図示は、特に断りが無い限り筆者が作成したものです。
AI platform pipelinesとは
AI platform pipelinesはGoogle Cloudが提供している、機械学習開発の標準戦略MLOpsを自動化するクラウドサービスです。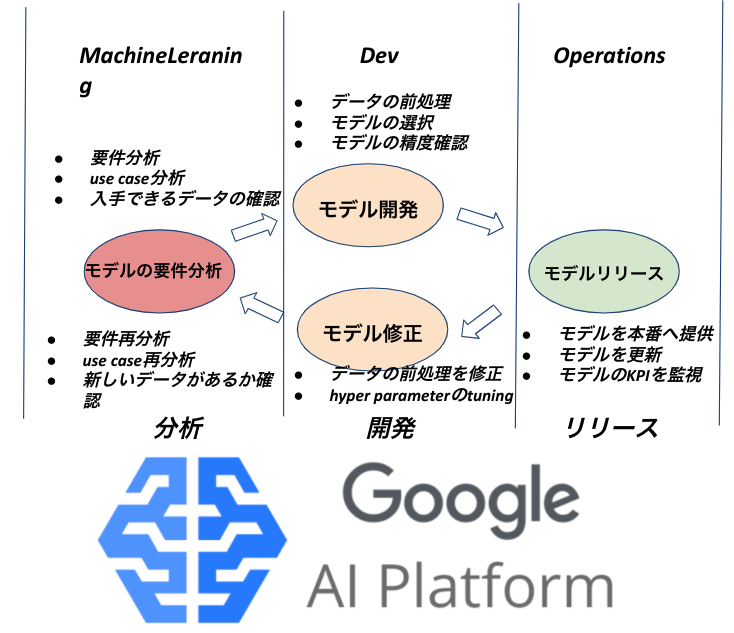
AI platform pipelinesとKubeflow
AI platform pipelinesはKubeflowに基づいて開発されたクラウドサービスです。AI Platformを利用するとKubeflowの環境構築をする時間を短縮できます。AI platform pipelinesの環境構築
Google Cloud プロジェクトを用意する
AI Platform pipelines の利用には Google Cloud プロジェクトの設定が必要です。もしGoogle Cloud プロジェクトを持っていなければこちらの公式サイトを参考にして、アカウントを作成してください。GCPの権限を設定する
AI Platform Pipelinesの利用はプロジェクトの閲覧者(roles/viewer)と Kubernetes Engine 管理者(roles/container.admin)のロールか、プロジェクトのオーナー(roles/owner)のロールなどと同等の権限を含むロールが必要です。Cloud Shell で次のコマンドを実行して上記の権限を設定しましょう。
|
1 2 3 |
gcloud projects get-iam-policy PROJECT_ID --flatten="bindings[].members" --format="table(bindings.role, bindings.members)" --filter="bindings.role:roles/container.admin OR bindings.role:roles/viewer" |
新しいAI Platform Pipelinesのインスタンスを立ち上げ
- AI Platform Pipelinesの管理画面へ遷移してください
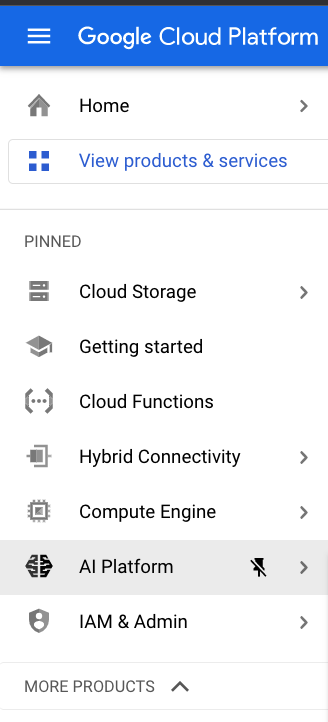
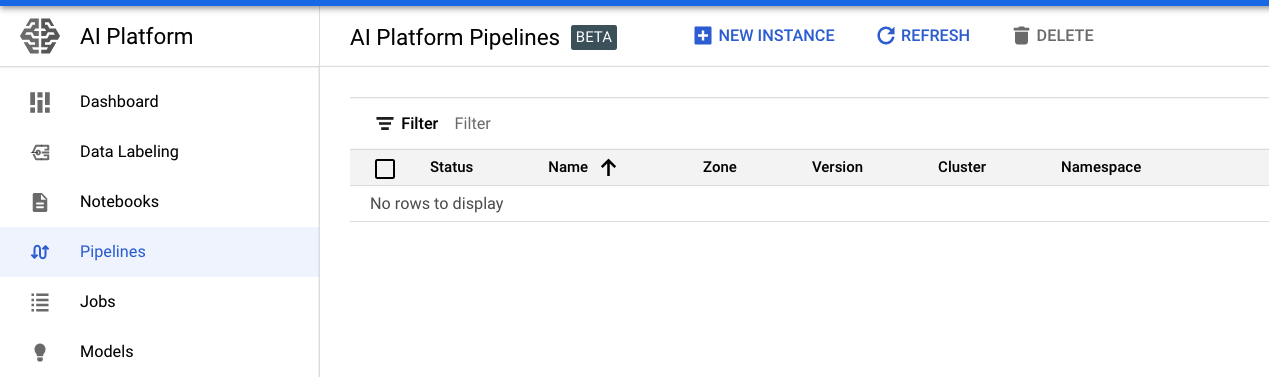
- [NEW INSTANCE] をクリックして新しいclusterを立ち上げましょう。
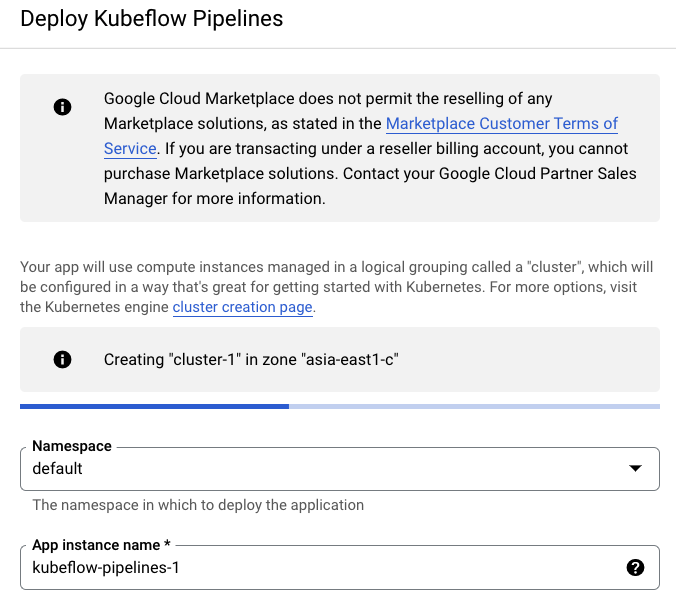
- Cloud リソースへのアクセス権を許可して[Create cluster] をクリックします。

- clusterが作成されるまで待ってください。
- AI Platform Pipelinesをdeployする。
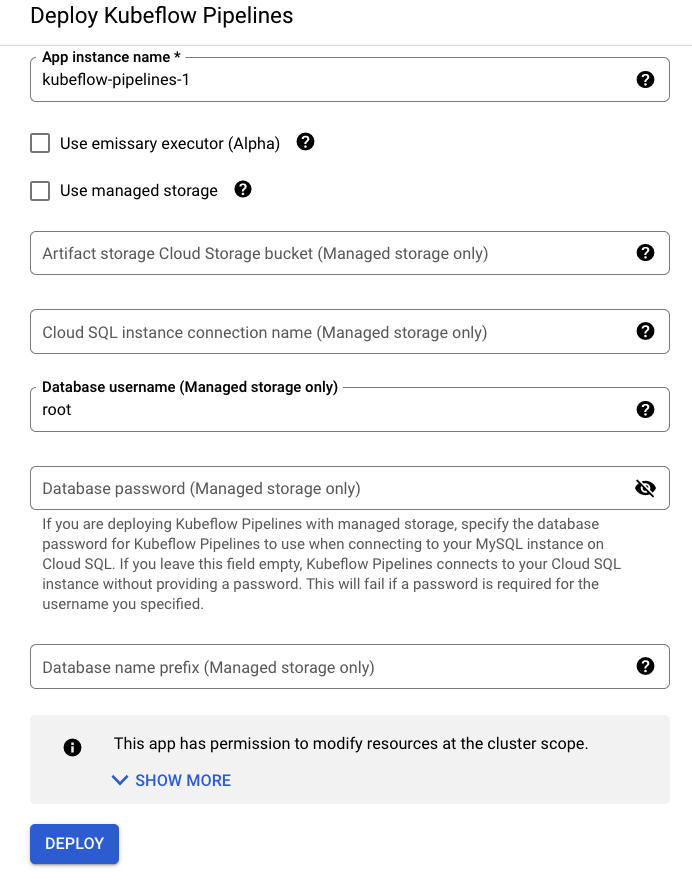
[DEPLOY]をクリックしてください。 - [ OPEN PIPELINES DASHBOARD]を押してKubeflow PipelinesのDashboard UIへ飛ぶ

- Kubeflow PipelinesのDashboard UI
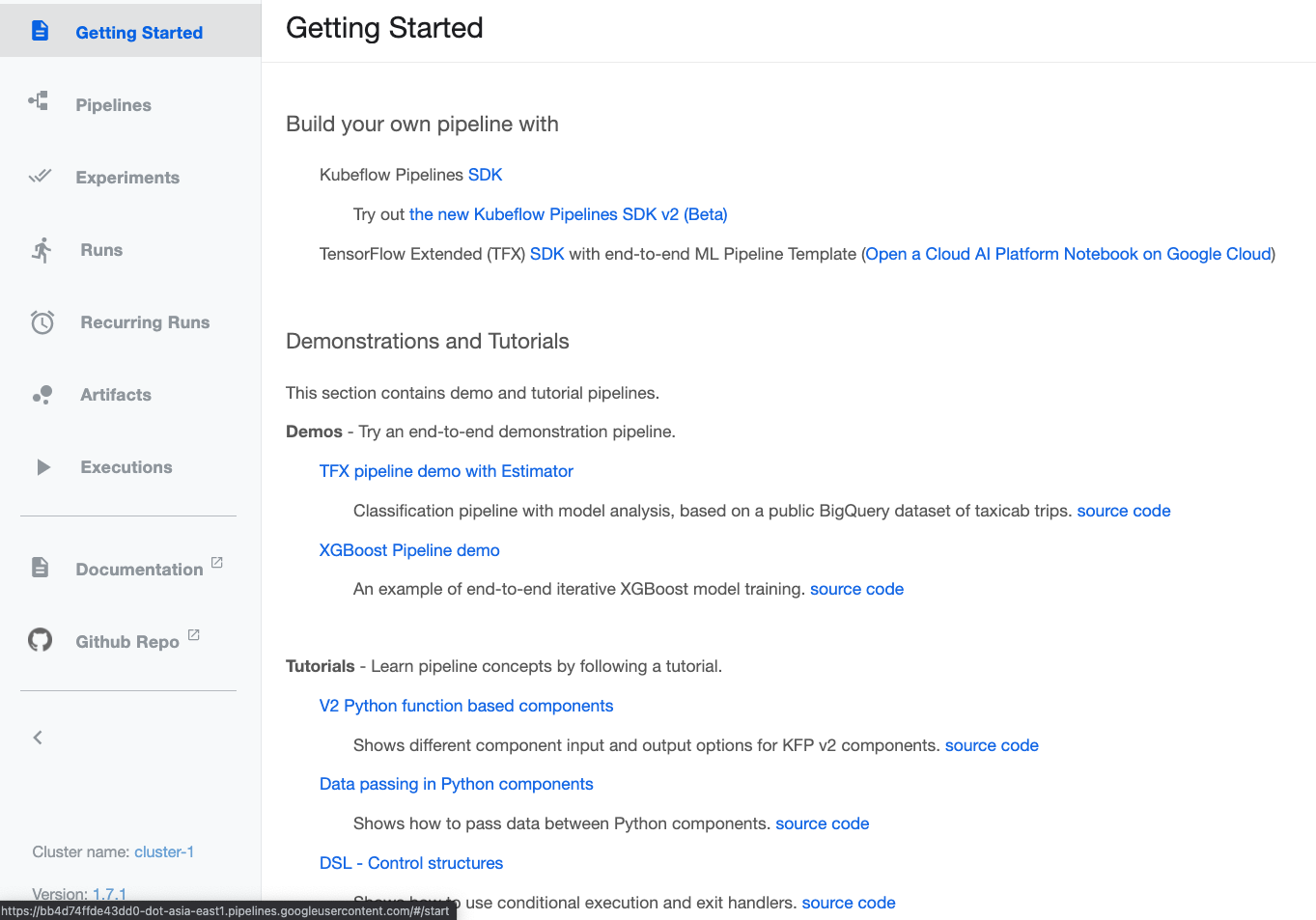
Kubeflow Pipelines SDKをインストール
こちらの公式サイトを参考にしてKubeflow Pipelines SDKをインストールしてください。MNISTのKubeflow Pipelinesを定義するファイルを書く
今回のモデルは下記の4 つのpipelineがあります。- データを前処理
- モデルを学習
- モデルの精度を計算
- モデルの精度を可視化
| pipelineの役割 | ファイル名 |
| データを前処理 | load_mnist_data.yaml |
| モデルを学習 | train_model.yaml |
| モデルの精度を計算 | evaluate_model.yaml |
| モデルの精度を可視化 | confusion_matrix.yaml |
| pipelineを組み合わせるscript | mnist_training.py |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
name: Load the mnist dataset description: |- Load the mnist dataset. args: bucket: gcs path Raises: RuntimeError: If dataset is not successfully loadded properly and HALT_ON_ERROR flag is set. inputs: - name: bucket type: String implementation: container: image: google/cloud-sdk:279.0.0 command: - python3 - -u - -c - | import subprocess #必要のツールをインストールする subprocess.run(['curl', 'https://bootstrap.pypa.io/get-pip.py', '-o', 'get-pip.py'],capture_output=True) subprocess.run(['apt-get', 'install', 'python3-distutils', '--yes'], capture_output=True) subprocess.run(['python3', 'get-pip.py'], capture_output=True) subprocess.run('pip3 install -U scikit-learn scipy pandas kfp>=0.1.31 --quiet',shell=True, check=True) from sklearn import datasets from sklearn.model_selection import train_test_split import pandas as pd import argparse _parser = argparse.ArgumentParser(prog='Load the mnist dataset') _parser.add_argument("--bucket", dest="bucket", type=str, required=True, default=argparse.SUPPRESS) _parsed_args = _parser.parse_args() digits = datasets.load_digits() n_samples = len(digits.images) rawdata = digits.images.reshape((n_samples, -1)) X_train, X_test, y_train, y_test = train_test_split(rawdata, digits.target, test_size=0.5, shuffle=False) pd.DataFrame(X_train).to_csv('X_train.csv', header=False, index=False) pd.DataFrame(X_test).to_csv('X_test.csv', header=False, index=False) pd.DataFrame(y_train).to_csv('y_train.csv', header=False, index=False) pd.DataFrame(y_test).to_csv('y_test.csv', header=False, index=False) subprocess.run('gsutil cp X_train.csv %s/' % _parsed_args.bucket,shell=True, check=True) subprocess.run('gsutil cp y_train.csv %s/' % _parsed_args.bucket,shell=True, check=True) subprocess.run('gsutil cp X_test.csv %s/' % _parsed_args.bucket,shell=True, check=True) subprocess.run('gsutil cp y_test.csv %s/' % _parsed_args.bucket,shell=True, check=True) args: - --bucket - inputValue: bucket |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
name: Train mnist model. description: |- Train a mnist model args: bucket: Raises: RuntimeError: If dataproc instance is not deleted properly and HALT_ON_ERROR flag is set. inputs: - name: bucket type: String implementation: container: image: google/cloud-sdk:279.0.0 command: - python3 - -u - -c - | import subprocess subprocess.run(['curl', 'https://bootstrap.pypa.io/get-pip.py', '-o', 'get-pip.py'],capture_output=True) subprocess.run(['apt-get', 'install', 'python3-distutils', '--yes'], capture_output=True) subprocess.run(['python3', 'get-pip.py'], capture_output=True) subprocess.run('pip3 install -U scikit-learn scipy pandas kfp>=0.1.31 --quiet',shell=True, check=True) from sklearn.ensemble import RandomForestClassifier from joblib import dump, load import pandas as pd import argparse _parser = argparse.ArgumentParser(prog='Train mnist model.') _parser.add_argument("--bucket", dest="bucket", type=str, required=True, default=argparse.SUPPRESS) _parsed_args = _parser.parse_args() # Create a classifier: a support vector classifier subprocess.run('gsutil cp %s/X_train.csv ./X_train.csv' % _parsed_args.bucket,shell=True, check=True) subprocess.run('gsutil cp %s/y_train.csv ./y_train.csv' % _parsed_args.bucket,shell=True, check=True) X_train = pd.read_csv("X_train.csv",header=None) y_train = pd.read_csv("y_train.csv",header=None) clf = RandomForestClassifier() # Split data into 50% train and 50% test subsets # Learn the digits on the train subset clf.fit(X_train, y_train) dump(clf, 'rf.model') subprocess.run('gsutil cp rf.model %s/' % _parsed_args.bucket,shell=True, check=True) args: - --bucket - inputValue: bucket |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
name: Evaluate model. description: |- Evaluated the model. args: bucket: Raises: RuntimeError: If model is not deleted properly evaluated. HALT_ON_ERROR flag is set. inputs: - name: bucket type: String implementation: container: image: google/cloud-sdk:279.0.0 command: - python3 - -u - -c - | import subprocess subprocess.run(['curl', 'https://bootstrap.pypa.io/get-pip.py', '-o', 'get-pip.py'],capture_output=True) subprocess.run(['apt-get', 'install', 'python3-distutils', '--yes'], capture_output=True) subprocess.run(['python3', 'get-pip.py'], capture_output=True) subprocess.run('pip3 install -U scikit-learn scipy pandas kfp>=0.1.31 --quiet',shell=True, check=True) import argparse _parser = argparse.ArgumentParser(prog='Evaluate model.') _parser.add_argument("--bucket", dest="bucket", type=str, required=True, default=argparse.SUPPRESS) _parsed_args = _parser.parse_args() from joblib import dump, load import pandas as pd subprocess.run('gsutil cp %s/rf.model rf.model' % _parsed_args.bucket,shell=True, check=True) subprocess.run('gsutil cp %s/X_test.csv X_test.csv' % _parsed_args.bucket,shell=True, check=True) subprocess.run('gsutil cp %s/y_test.csv y_test.csv' % _parsed_args.bucket,shell=True, check=True) clf = load('rf.model') X_test = pd.read_csv("X_test.csv",header=None) y_test = pd.read_csv("y_test.csv",header=None) predicted = clf.predict(X_test) predictedDF = pd.DataFrame(predicted,columns=["predicted"]) predictedDF["target"] = y_test predictedDF.to_csv('predicted.csv', index=False) subprocess.run('gsutil cp predicted.csv %s/' % _parsed_args.bucket,shell=True, check=True) args: - --bucket - inputValue: bucket |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 |
name: Confusion matrix description: Calculates confusion matrix inputs: - {name: Predictions, type: GCSPath, description: 'GCS path of prediction file pattern.'} # type: {GCSPath: {data_type: CSV}} - {name: Target lambda, type: String, default: '', description: 'Text of Python lambda function which computes target value. For example, "lambda x: x[''a''] + x[''b'']". If not set, the input must include a "target" column.'} - {name: Output dir, type: GCSPath, description: 'GCS path of the output directory.'} # type: {GCSPath: {path_type: Directory}} outputs: - {name: MLPipeline UI metadata, type: UI metadata} - {name: MLPipeline Metrics, type: Metrics} implementation: container: image: google/cloud-sdk:279.0.0 command: - python3 - -u - -c - | import subprocess subprocess.run(['curl', 'https://bootstrap.pypa.io/get-pip.py', '-o', 'get-pip.py'],capture_output=True) subprocess.run(['apt-get', 'install', 'python3-distutils', '--yes'], capture_output=True) subprocess.run(['python3', 'get-pip.py'], capture_output=True) subprocess.run('pip3 install -U scikit-learn tensorflow scipy pandas kfp>=0.1.31 --quiet',shell=True, check=True) import argparse import json import os from urllib.parse import urlparse import pandas as pd from pathlib import Path from sklearn.metrics import confusion_matrix, accuracy_score from tensorflow.python.lib.io import file_io def main(argv=None): parser = argparse.ArgumentParser(description='ML Trainer') parser.add_argument('--predictions', type=str, help='GCS path of prediction file pattern.') parser.add_argument('--output', type=str, help='GCS path of the output directory.') parser.add_argument('--target_lambda', type=str, help='a lambda function as a string to compute target.' + 'For example, "lambda x: x['a'] + x['b']"' + 'If not set, the input must include a "target" column.') parser.add_argument('--ui-metadata-output-path', type=str, default='/mlpipeline-ui-metadata.json', help='Local output path for the file containing UI metadata JSON structure.') parser.add_argument('--metrics-output-path', type=str, default='/mlpipeline-metrics.json', help='Local output path for the file containing metrics JSON structure.') args = parser.parse_args() dfs = [] files = file_io.get_matching_files(args.predictions) for file in files: with file_io.FileIO(file, 'r') as f: dfs.append(pd.read_csv(f)) df = pd.concat(dfs) if args.target_lambda: df['target'] = df.apply(eval(args.target_lambda), axis=1) vocab = list(df['target'].unique()) cm = confusion_matrix(df['target'], df['predicted'], labels=vocab) data = [] for target_index, target_row in enumerate(cm): for predicted_index, count in enumerate(target_row): data.append((vocab[target_index], vocab[predicted_index], count)) df_cm = pd.DataFrame(data, columns=['target', 'predicted', 'count']) cm_file = os.path.join(args.output, 'confusion_matrix.csv') with file_io.FileIO(cm_file, 'w') as f: df_cm.to_csv(f, columns=['target', 'predicted', 'count'], header=False, index=False) metadata = { 'outputs' : [{ 'type': 'confusion_matrix', 'format': 'csv', 'schema': [ {'name': 'target', 'type': 'CATEGORY'}, {'name': 'predicted', 'type': 'CATEGORY'}, {'name': 'count', 'type': 'NUMBER'}, ], 'source': cm_file, # Convert vocab to string because for bealean values we want "True|False" to match csv data. 'labels': list(map(str, vocab)), }] } Path(args.ui_metadata_output_path).parent.mkdir(parents=True, exist_ok=True) Path(args.ui_metadata_output_path).write_text(json.dumps(metadata)) accuracy = accuracy_score(df['target'], df['predicted']) metrics = { 'metrics': [{ 'name': 'accuracy-score', 'numberValue': accuracy, 'format': "PERCENTAGE", }] } Path(args.metrics_output_path).parent.mkdir(parents=True, exist_ok=True) Path(args.metrics_output_path).write_text(json.dumps(metrics)) if __name__== "__main__": main() args: [ --predictions, {inputValue: Predictions}, --target_lambda, {inputValue: Target lambda}, --output, {inputValue: Output dir}, --ui-metadata-output-path, {outputPath: MLPipeline UI metadata}, --metrics-output-path, {outputPath: MLPipeline Metrics}, ] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import json import kfp from kfp import components from kfp import dsl import os import subprocess confusion_matrix_op = components.load_component_from_file('confusion_matrix.yaml') load_mnist_data_op = components.load_component_from_file('load_mnist_data.yaml') train_model_op = components.load_component_from_file('train_model.yaml') evaluate_model_op = components.load_component_from_file("evaluate_model.yaml") @dsl.pipeline( name='mnist_train_pipeline', description='A example that does end-to-end distributed training for mnist classification.' ) def mnist_train_pipeline(output='gs://{{kfp-default-bucket}}'): #bucketのpath output_path = str(output) true_label = '1' true_score_column = 'predicted_proba' output_template = output_path + '/' + dsl.RUN_ID_PLACEHOLDER + '/data' _load_mnist_data_op = load_mnist_data_op(bucket=output).set_display_name('preprocess data') _train_model_op = train_model_op(bucket=output).after(_load_mnist_data_op).set_display_name('train model') _evaluate_model_op = evaluate_model_op(bucket=output).after(_train_model_op).set_display_name('evaluate model') _cm_op = confusion_matrix_op( predictions=output_path + "/predicted.csv", output_dir=output_template).after(_evaluate_model_op).set_display_name('confusion matrix') if __name__ == '__main__': kfp.compiler.Compiler().compile(mnist_train_pipeline, __file__ + '.yaml') |
|
1 |
dsl-compile --py mnist_training.py --output mnist_training.zip |
MNISTのKubeflow Pipelinesをuploadする
Kubeflow PipelinesのDashboard UIで[Upload pipeline]をクリックしてください。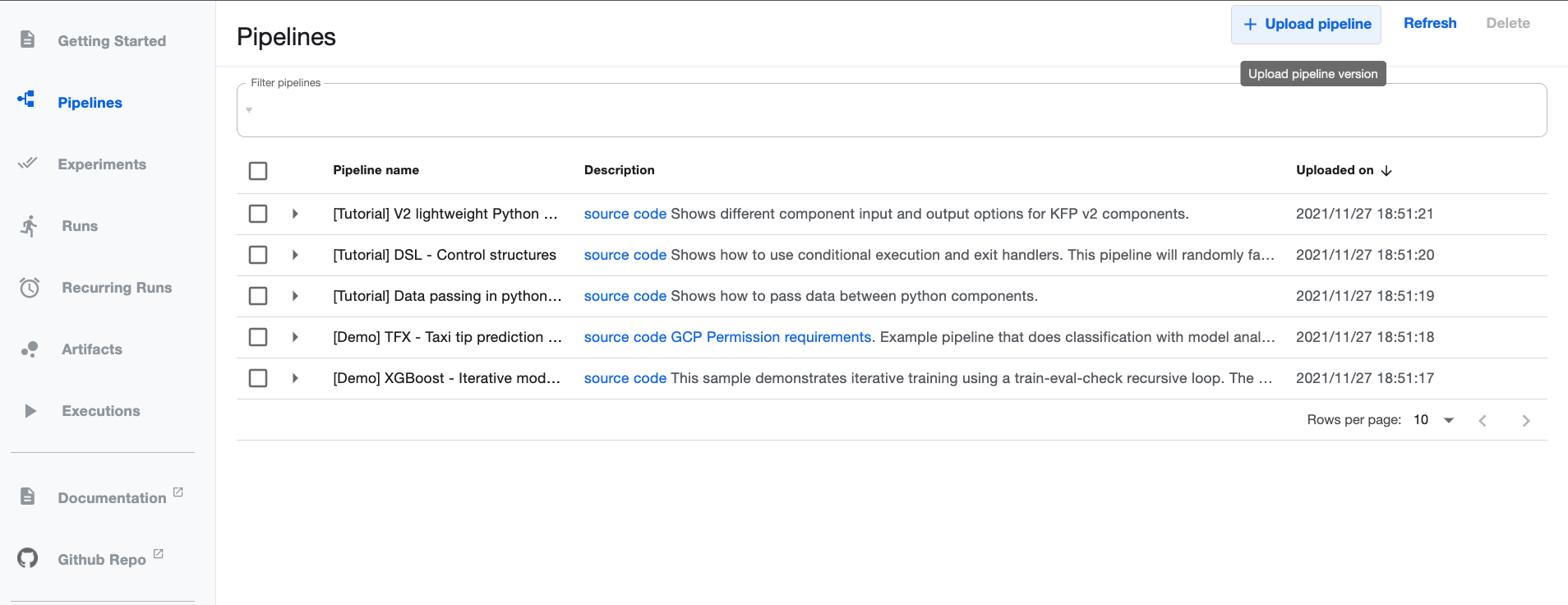 前に作成していたmnist_training.zipをuploadしましょう。
前に作成していたmnist_training.zipをuploadしましょう。 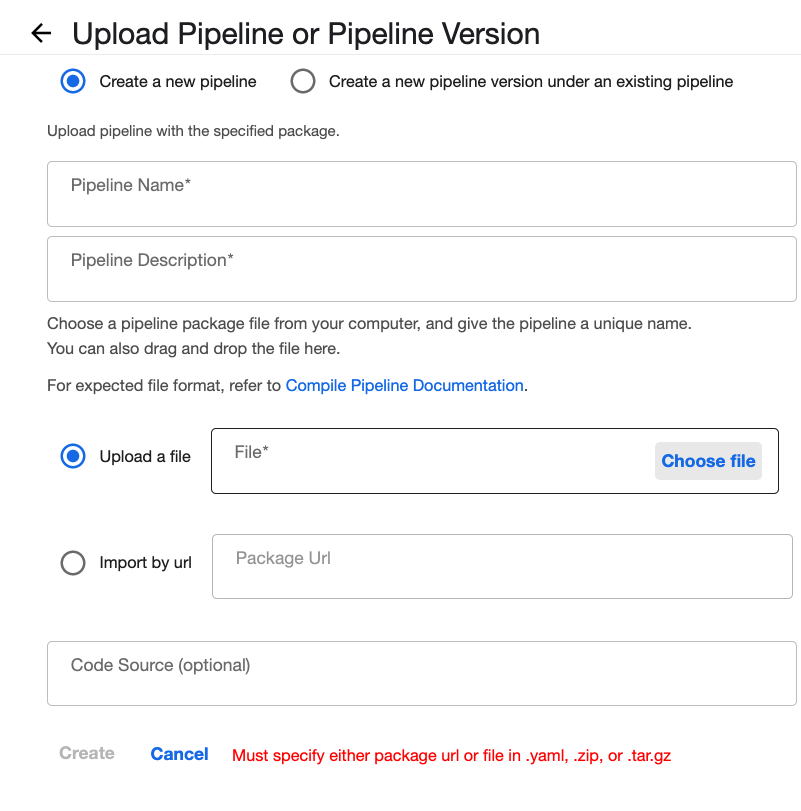 mnist_training.zipをupload した様子。
mnist_training.zipをupload した様子。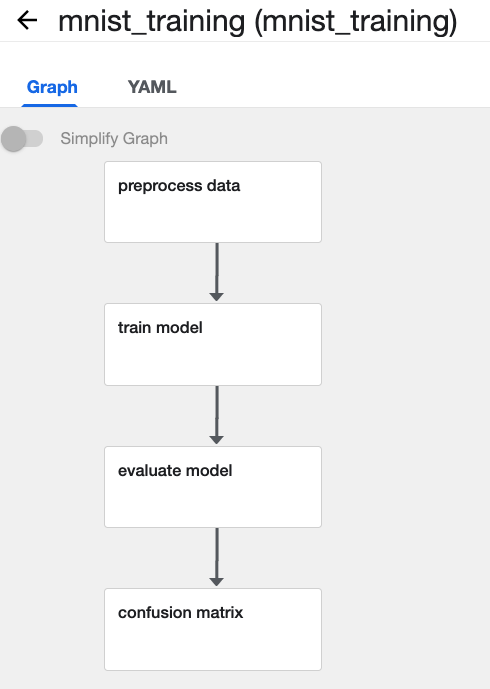
MNISTのKubeflow Pipelinesを実行する
それでは、右上の[Create run]をクリックして早速MNIST のKubeflow Pipelines を走ってみましょう。 defaultの設定のまま実行します。
defaultの設定のまま実行します。  3分ぐらい待って実行は完了できました。
3分ぐらい待って実行は完了できました。 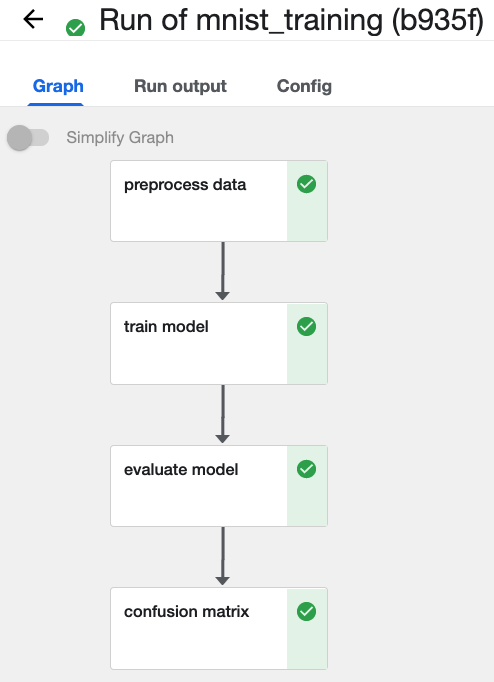 最後のconfusion matrixのpipelineを押すと今回のモデルのテストデータが確認できます。
最後のconfusion matrixのpipelineを押すと今回のモデルのテストデータが確認できます。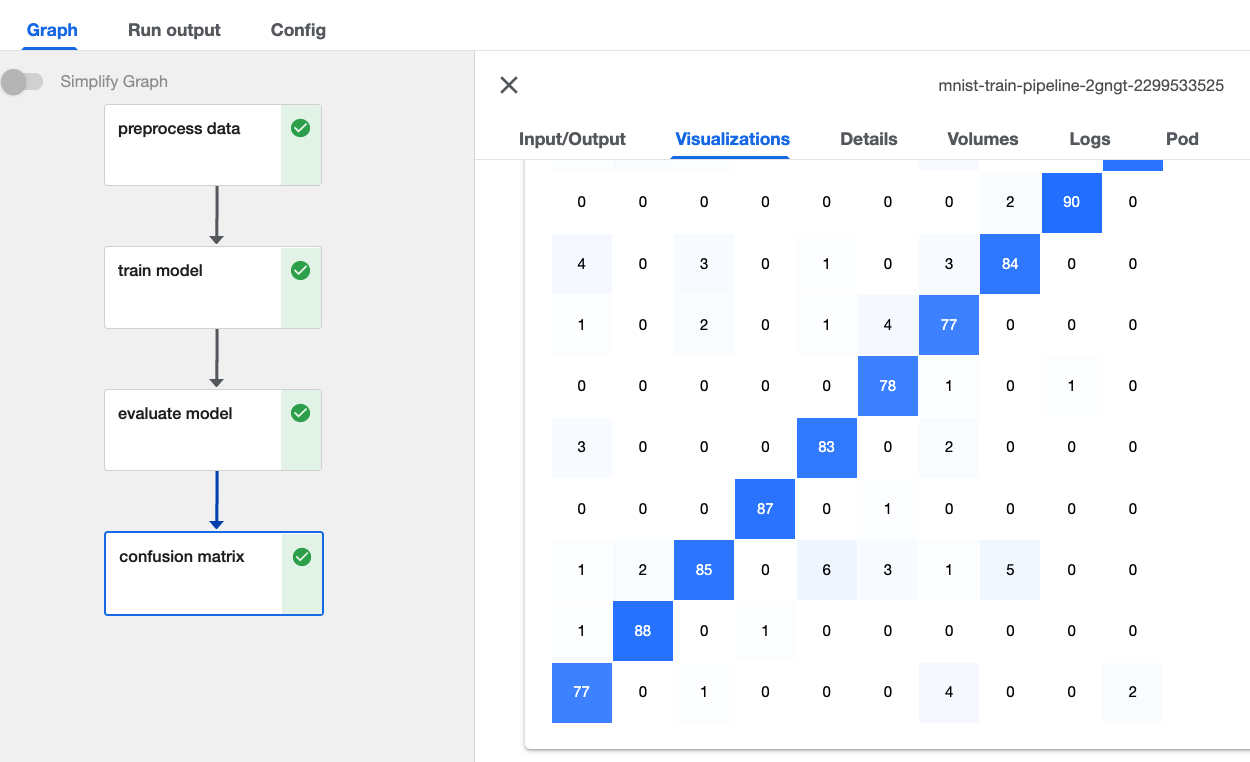
終わりに
今回GCP:AI platform pipelinesで を構築する方法を紹介しました。もし今回のブログが皆さんのMLOpsの開発にお役に立てば幸いです。


