
こんにちは。
GMOアドマーケティングの@zakisanbaimanです。
弊社ではDWHとしてBigQueryを採用しているのですが、テーブルサイズが巨大になりそのクエリコストが課題になっていました。
そこでテーブルにパーティションを設定し、クエリの書き方を工夫することによってコストを抑えようと試みたので内容を共有します。
パーティションテーブルとは
1つのテーブルを指定した単位で分割させることでクエリ時に参照するレコード数を削減し、クエリコストの削減やパフォーマンス向上を狙うことができます。
RDBMSのパーティショニングに近い機能ですね。
パーティションは1テーブルに対して1つのみ設定でき、「時間単位の列(TIMESTAMP型やDATETIME型)」、「整数型の列」、「取り込み時間」に対して設定できます。
今回はTIMESTAMP型の列に対して”HOUR”単位でパーティションを設定しました。
注意点
気をつけるべきこととして、パーティション化されたテーブルに対しては標準SQLでのみクエリ可能となります。
そのためレガシーSQLで記述されている箇所がある場合、全て修正する必要があります。
また、トップレベルの列にしか設定できないため、RECORDやREPEATED内の列に対しては設定できません。
移行準備
1. レガシーSQL修正
パーティションテーブルに対しては標準SQLでのみクエリ可能となるため、レガシーSQLで記述されている箇所を全て修正しました。
注意点としてbq queryコマンドではデフォルトでレガシーSQLを使うようになっているため、オプションに「–use_legacy_sql=false」を付与するかSQLの先頭に「#standardSQL」と記述する必要があります。(2022/9現在)
2. Dataflow修正
弊社ではBigQueryへのETLツールとしてDataflowを採用していますが、テーブルがパーティションされたことで一部コードを修正する必要がありました。
Dataflow修正内容
移行作業
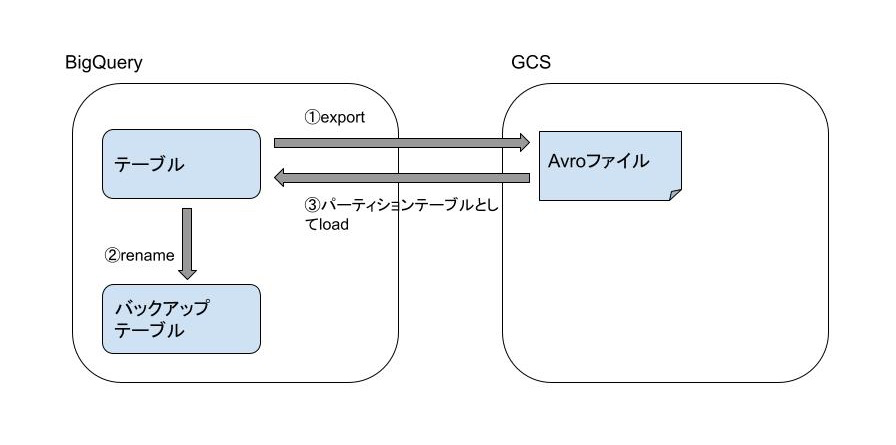
既存テーブルを直接パーティション化するようなコマンドはなかったため、以下手順で移行させました。
1. 既存テーブルをGCSへエクスポート
|
1 2 3 4 5 |
bq extract --project_id="プロジェクトID" \ --destination_format="AVRO" \ --compression="SNAPPY" \ "対象テーブル" "保存先GCSファイルパス" |
注意点として、データが大量にある場合は1日あたりのエクスポート上限に当たってしまう可能性があります。
そのため上限を少し緩くしてもらい、移行作業当日まで数日かけてエクスポートを行いました。
2. 既存テーブルをリネーム
既存テーブルの退避としてテーブル名を変更しました。
|
1 2 |
ALTER TABLE "元テーブル" RENAME TO "リネーム先テーブル名" |
3. GCSへエクスポートしたファイルをパーティションテーブルとしてロード
今回は”time”というTIMESTAMP型の列に対して”HOUR”単位でパーティションを設定しています。
|
1 2 3 4 5 6 7 8 |
bq load --replace=true \ --source_format="AVRO" \ --time_partitioning_field="time" \ --time_partitioning_type="HOUR" \ "テーブル名" \ "GCSファイルパス" \ "スキーマファイル"; |
結果
実際に効果を感じるためには以下のようにパーティション対象列(今回はtime列)の条件を絞ります。
仮に元々24TBの処理量がかかっていたとしたら24分の1の1TBまでクエリコストを減らすことができています。
|
1 2 3 |
SELECT * FROM `テーブル名` WHERE time between '2022-09-26 00:00:00' and '2022-09-26 1:00:00' |
上記のように対象列で絞り込みを行わなければこれまで通りのクエリコストがかかってしまいますので、BigQueryを利用する各種バッチの修正やコンソールでSQLを実行する利用者への周知も必要になります。
まとめ
テーブルのパーティション化自体は意外とシンプルでしたが、最近はBigQueryを分析だけでなくELT(Extract Load Transform)ツールとしても扱っていたため、影響範囲が大きく緊張したタスクとなりました。
パーティション化した次のステップとしてクラスタリング(indexみたいなもの)があるため、そちらも採用したらブログにまとめたいと思います。
最後までお読み頂きありがとうございました。


